Editor’s note: On April 16, 2024, we updated our original post on federated learning, which was first published October 13, 2019.
The key to becoming a medical specialist, in any discipline, is experience.
Knowing how to interpret symptoms, which move to make next in critical situations, and which treatment to provide — it all comes down to the training you’ve had and the opportunities you’ve had to apply it.
For AI algorithms, experience comes in the form of large, varied, high-quality datasets. But such datasets have traditionally proved hard to come by, especially in the area of healthcare.
Federated learning is a way to develop and validate accurate, generalizable AI models from diverse data sources while mitigating the risk of compromising data security or privacy. It enables AI models to be built with a consortium of data providers without the data ever leaving individual sites.
Medical institutions have had to rely on their own data sources, which can be biased by, for example, patient demographics, the instruments used or clinical specializations. Or they’ve needed to pool data from other institutions to gather all of the information they need, which requires managing regulatory issues.
Federated learning makes it possible for AI algorithms to gain experience from a vast range of data located at different sites.
The approach enables several organizations to collaborate on the development of models, but without needing to directly share sensitive clinical data with each other.
Over the course of several training iterations the shared models get exposed to a significantly wider range of data than what any single organization possesses in-house.
Federated learning is gaining traction beyond healthcare, moving into financial services, cybersecurity, transportation, high performance computing, energy, drug discovery and other fields.
Frameworks such as NVIDIA FLARE (NVFlare) have enabled enterprises to collaborate by contributing data through federated learning for model improvements.
NVFlare, an open-source federated learning framework that’s widely adopted across various applications, offers a diverse range of examples of machine learning and deep learning algorithms. It includes robust security features, advanced privacy protection techniques and a flexible system architecture — building trust among users.
How Federated Learning Works
The main concept of federated learning is to train models locally without sharing data, only the model parameters.
The aggregator starts with an initial global model and broadcasts the model parameters to all clients. The client node receives the global model parameters and starts training the received model on local data. Then, the newly trained local model is sent back to the aggregator node. Only model parameters, no private data, are shared with the aggregator.
The aggregator node will perform aggregation, such as weighted average, to produce a new global model. That new global model will be broadcast again by repeating the first step until convergence, or until it’s reached the max number of rounds.
AI algorithms deployed in medical scenarios ultimately need to reach clinical-grade accuracy. Largely speaking, this means that they meet, or exceed, the gold standard for the application to which they’re applied.
To be considered an expert in a particular medical field, you generally need to have clocked 15 years on the job. Such an expert has probably read around 15,000 cases in a year, which adds up to around 225,000 over their career.
When you consider rare diseases, which affect around one in 2,000 people, even an expert with three decades’ experience will have only seen roughly 100 cases of a particular condition.
To train models that meet the same grade as medical experts, the AI algorithms need to be fed a large number of cases. And these examples need to sufficiently represent the clinical environment in which they’ll be used.
But currently the largest open dataset contains 100,000 cases.
And it’s not only the amount of data that counts. It also needs to be very diverse and incorporate samples from patients of different genders, ages, demographics and environmental exposures.
Individual healthcare institutes may have archives containing hundreds of thousands of records and images, but these data sources are typically kept siloed. This is largely because health data is private and cannot be used without the necessary patient consent and ethical approval.
Federated learning decentralizes deep learning by removing the need to pool data into a single location. Instead, the model is trained in multiple iterations at different sites.
For example, say three hospitals decide to team up and build a model to help automatically analyze brain tumor images.
If they chose to work with a client-server federated approach, a centralized server would maintain the global deep neural network and each participating hospital would be given a copy to train on their own dataset.
Once the model had been trained locally for a couple of iterations, the participants would send their updated version of the model back to the centralized server and keep their dataset within their own secure infrastructure.
The central server would then aggregate the contributions from all of the participants. The updated parameters would then be shared with the participating institutes, so that they could continue local training.
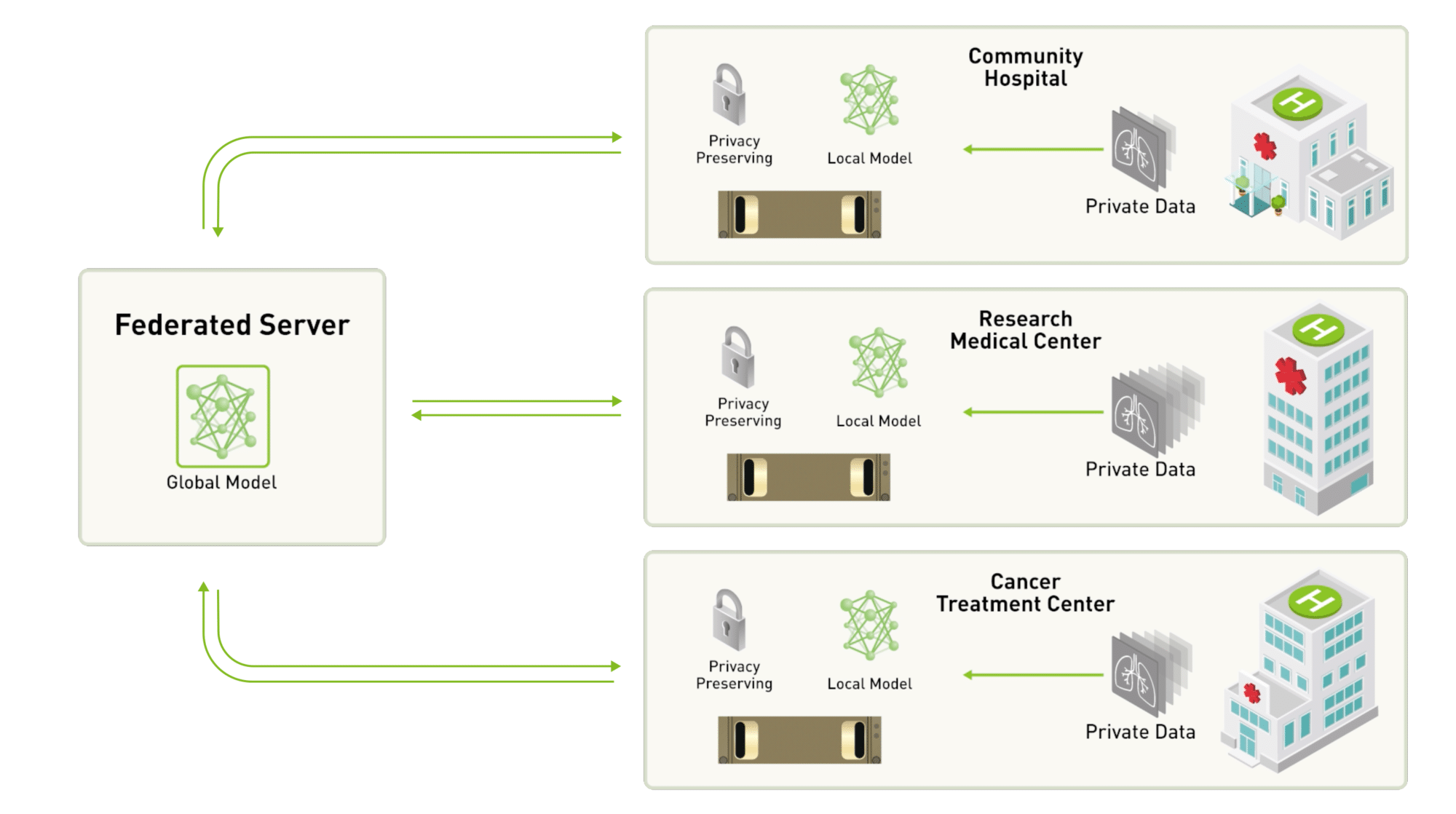
If one of the hospitals decided it wanted to leave the training team, this would not halt the training of the model, as it’s not reliant on any specific data. Similarly, a new hospital could choose to join the initiative at any time.
This is just one of many approaches to federated learning. The common thread through all approaches is that every participant gains global knowledge from local data — everybody wins.
Why Federated Learning?
Federated learning still requires careful implementation to ensure that patient data is kept secure. But it has the potential to tackle some of the challenges faced by approaches that require the pooling of sensitive clinical data.
For federated learning, clinical data doesn’t need to be taken outside an institution’s own security measures. Every participant keeps control of its own clinical data.
As this makes it harder to extract sensitive patient information, federated learning opens up the possibility for teams to build larger, more diverse datasets for training their AI algorithms.
Implementing a federated learning approach also encourages different hospitals, healthcare institutions and research centers to collaborate on building a model that could benefit them all.
How Federated Learning Can Transform Industries
Federated learning could revolutionize how AI models are trained, with the benefits also filtering out into the wider healthcare ecosystem.
Larger hospital networks would be able to work better together and benefit from access to secure, cross-institutional data. While smaller community and rural hospitals would enjoy access to expert-level AI algorithms.
It could bring AI to the point of care, enabling large volumes of diverse data from across different organizations to be included in model development, while complying with local governance of the clinical data.
Clinicians would have access to more robust AI algorithms, based on data that represents a wider demographic of patients for a particular clinical area or from rare cases that they would not have come across locally. They’d also be able to contribute back to the continued training of these algorithms whenever they disagreed with the outputs.
Healthcare startups could bring cutting-edge innovations to market faster, thanks to a secure approach to learning from more diverse algorithms.
Meanwhile, research institutions would be able to direct their work toward actual clinical needs, based on a wide variety of real-world data, rather than the limited supply of open datasets.
Large-scale federated learning projects are now starting, hoping to improve drug discovery and bring AI benefits to the point of care.
MELLODDY, a drug-discovery consortium based in the U.K., aims to demonstrate how federated learning techniques could give pharmaceutical partners the best of both worlds: the ability to leverage the world’s largest collaborative drug compound dataset for AI training without sacrificing data privacy.
King’s College London is hoping that its work with federated learning, as part of its London Medical Imaging and Artificial Intelligence Centre for Value-Based Healthcare project, could lead to breakthroughs in classifying stroke and neurological impairments, determining the underlying causes of cancers, and recommending the best treatment for patients.
In the context of financial services, federated learning can be applied to train a model using data from several banks to estimate individual transaction risk scores while keeping personal information locally at the banks.
Fraud detection is an important federated learning use case for banking and insurance. Institutions can harness data from user accounts and fraud cases to create better fraud-detection models without sacrificing user data privacy.
This can be challenging without federated learning, considering data privacy protection laws such as the EU’s GRPR, China’s PIPL and the recent EU AI Act, which prohibits cross-border data sharing. With federated learning, financial institutions can comply with these laws and regulations while using rich, private datasets for better, safer outcomes.
NVFlare can be used with XGBoost and Kaggle’s Credit Card Fraud Detection dataset for securing credit card transactions and with graph neural networks (GNNs) for financial transaction classification.
Federated learning is also applicable in use cases such as federated data analytics on edge medical devices, cross-board data training with autonomous vehicle models and drug discovery. Driven by data privacy regulations, the need to build better models with more private data, as well as the generative AI boom, the adoption of federal learning is accelerating.
Learn more about NVFlare. Explore more about federated learning on related NVIDIA technical blogs. And discover the science behind the approach, in this paper.