Thursday, March 19, 2:30 p.m. PT 🔗
AI Sing-Along Recaps GTC Keynote
This year’s GTC keynote closed with a campfire gathering of robots and TJ — Toy Jensen, an AI avatar of NVIDIA founder and CEO Jensen Huang — as they toasted marshmallows and recapped the show’s biggest announcements through song.
From breakthrough AI to accelerated computing, it’s a fingerpicking, harmonica-blowing, robot-filled recap of the innovations shaping the future.
The animated video, a surprise finale for keynote viewers, was designed by NVIDIA’s creative team using generative AI tools. After experimenting with an AI music generator to compose songs, a video editor on the team came up with the idea to feature robots making music by a rustic campfire.
Combining various AI models for image and video generation and editing, the team developed a pipeline to create an animation flexible enough to absorb feedback and changes. Another model helped create and maintain a consistent database of characters and models.
Robots gained drums, guitars and maracas; a lobster was added in a nod to NVIDIA NemoClaw; other teams provided reference images for the robot dog and, of course, TJ, whose leather jacket was replaced by a plaid shirt.
Layered on top of the video is a song. In the days before the keynote, the team chose to focus on recapping the major GTC announcements. To bring them vividly to life, a writer and filmmaker worked with NVIDIA marketing leaders to craft lyrics and fine-tune the music, matching the rustic campfire theme.
Monday, March 16, 11:00 a.m. PT 🔗
Live Updates From the GTC Keynote
Welcome to GTC 2026
A capacity crowd at the SAP Center, all waiting for the same thing.
The keynote opened with a video framing the token as the basic unit of modern AI — the building block behind systems used for scientific discovery, virtual worlds and machines operating in the physical world.
NVIDIA founder and CEO Jensen Huang then took the stage to raucous applause from the crowd.
He opened by thanking the pregame show hosts and highlighting the partners participating in the show, along with the 450+ sponsors, 1,000 sessions and 2,000 speakers.
“This conference is going to cover every single layer of the five-layer cake of artificial intelligence,” Huang said.
He marked the 20th anniversary of CUDA — describing it as the “flywheel” driving accelerated computing and the platform that supports “every single phase of the AI lifecycle.”
Huang turned to GeForce, describing NVIDIA as “the house that GeForce made,” the platform that brought CUDA to the world. He walked through GeForce’s history, tying it all back to AI, and introduced DLSS 5, launching a video showing how 3D-guided neural rendering enables real-time, photoreal 4K performance on local hardware. Learn more in the press release.
Next, Huang walked through the field of data processing and how it’s being accelerated for the era of AI. He detailed work with IBM, Dell, Google Cloud, AWS, Microsoft Azure, Oracle and CoreWeave, to serve their customers.
Huang then surveyed the accelerated computing ecosystem — automotive, financial services, healthcare, industrial, media, quantum, retail, robotics and telecom.
“All of these different vectors of AI have platforms that NVIDIA provides,” Huang said, highlighting NVIDIA’s broad range of CUDA-X libraries, which he described as the “crown jewels” of the company.
Huang highlighted the rise of “AI natives” — brand-new companies, some well-known, such as OpenAI and Anthropic, and some still emerging. “This last year, it just skyrocketed,” Huang said, citing $150 billion of investment into venture startups and walking through the history of the technologies that sparked the latest technology boom.
As a result of this boom, the computing demand for NVIDIA GPUs is “off the charts,” he said. “I believe computing demand has increased by 1 million times over the last few years.”
As a result, Huang said he now sees at least $1 trillion in revenue from 2025 through 2027.

Vera Rubin and Beyond — A Generational Leap in Computing
Huang noted that NVIDIA’s token cost is the best in the world, thanks to extreme codesign, reveling in one analyst description of NVIDIA as “the inference king.” “This is the incredible power of extreme codesign,” Huang said, referencing a process where software and silicon are designed in tandem.
The next step: NVIDIA Vera Rubin, a new full-stack computing platform comprising seven chips, five rack-scale systems and one supercomputer for agentic AI. The platform includes the new NVIDIA Vera CPU and BlueField-4 STX storage architecture.
“When we think Vera Rubin, we think the entire system, vertically integrated, complete with software, extended end to end, optimized as one giant system,” Huang said, walking the audience through the insides of new systems built on these technologies.

Looking beyond Vera Rubin, NVIDIA’s next major architecture is Feynman.
It will include a new CPU, NVIDIA Rosa, named for Rosalind Franklin, Huang said, whose X‑ray crystallography revealed the structure of DNA and reshaped modern biology. As Franklin exposed the hidden architecture of life, Rosa is built to move data, tools and tokens efficiently across the full stack of agentic AI infrastructure.
Rosa anchors a new platform that pairs LP40, NVIDIA’s next‑generation LPU, with NVIDIA BlueField‑5 and CX10, connected through NVIDIA Kyber for both copper and co‑packaged optics scale‑up, and NVIDIA Spectrum‑class optical scale‑out, Huang said. Together, the Feynman generation advances every pillar of the AI factory: compute, memory, storage, networking and security.
And to help accelerate the scale-out of new AI capacity, Huang announced the NVIDIA Vera Rubin DSX AI Factory reference design and the NVIDIA Omniverse DSX Blueprint. DSX Air, part of the broader DSX platform, lets companies simulate AI factories in software before building them in the physical world.
Finally, Huang announced NVIDIA is going to space. Its new Vera Rubin architecture honors the astronomer whose work revealed dark matter, and future systems like NVIDIA Space-1 Vera Rubin are being designed to bring AI data centers into orbit, extending accelerated computing from Earth to space.
NVIDIA NemoClaw for OpenClaw, Nemotron Coalition
Huang spotlighted OpenClaw, an open source project from developer Peter Steinberger that he called “the most popular open source project in the history of humanity.”
“OpenClaw has open sourced the operating system of agentic computers … Now, OpenClaw has made it possible for us to create personal agents,” Huang said.

With a single command, developers can pull down OpenClaw, stand up an AI agent and begin extending it with tools and context. NVIDIA is announcing support for OpenClaw across its platform, making it easier for developers to safely build, deploy and accelerate AI agents on NVIDIA‑powered infrastructure.
Every single company in the world today has to have an OpenClaw strategy, Huang said.
To ensure this technology can be deployed securely inside enterprises, Huang introduced the NVIDIA OpenShell runtime and the NVIDIA NemoClaw stack — combining policy enforcement, network guardrails and privacy routing. These technologies can serve as “the policy engine of all the SaaS companies in the world,” Huang said.
In addition, NVIDIA is expanding its open model ecosystem with a new Nemotron Coalition, rallying partners around six frontier model families: NVIDIA Nemotron (language and reasoning), NVIDIA Cosmos (world and vision), NVIDIA Isaac GR00T (general‑purpose robotics), NVIDIA Alpaymayo (autonomous driving), NVIDIA BioNeMo (biology and chemistry) and NVIDIA Earth‑2 (weather and climate).
Physical AI
NVIDIA is extending AI from digital agents into physical AI that can navigate the real world.
Huang said NVIDIA’s robotaxi‑ready platform is drawing new automaker partners, including BYD, Hyundai, Nissan and Geely.
He also highlighted a partnership with Uber to deploy these vehicles into its ride‑hailing network.
Beyond automakers, NVIDIA is working with industrial software giants and robotics leaders such as ABB, Universal Robots and KUKA to integrate its physical AI models and simulation tools, enabling deployment of smarter robots on manufacturing lines, and with telecom providers like T‑Mobile as base stations evolve into edge AI platforms.
That’s a Wrap
Huang capped off his keynote with a surprise visit from Olaf, the snowman from Disney’s Frozen, who appeared to walk straight off a digital screen and onto the stage.
“Ladies and gentlemen, Olaf,” Huang said, as the character waddled out, driven by NVIDIA’s physical AI stack, the Newton physics engine and NVIDIA Omniverse-powered simulation.
“Olaf, how are you? I know because I gave you your computer — Jetson,” Huang joked.
When Olaf asked what that was, Huang replied, “Well, it’s in your tummy … and you learned how to walk inside Omniverse.”
The demo underscored Huang’s broader point: everything on display — from humanoid robots to animated characters — had been simulated, not pre-rendered.
Huang closed by recapping the themes — inference, the AI factory, the OpenClaw, physical AI and robotics — then handed the stage to a musical ensemble: singing robots, a digital Jensen avatar and an animated lobster, performing a campfire song.
“All right, have a great GTC,” Huang said, exiting stage left as Olaf lingered, hamming it up for the crowd as he sank back beneath the stage through a trap door.
Read all NVIDIA news from GTC on the online press kit.
Build an agent of your own at NVIDIA’s build-a-claw event in the GTC Park, March 16-19 — 1-5 p.m. on Monday, and 8 a.m.-5 p.m. on Tuesday through Thursday — to customize and deploy a proactive, always-on AI assistant.
Wednesday, March 11, 9 a.m. PT 🔗
Build-a-Claw at GTC Park
GTC attendees can be among the first to get their hands on a “claw” — or long-running agent — using OpenClaw, the fastest-growing open source project in history.

Stop by NVIDIA’s build-a-claw event in the GTC Park March 16-19, between 1 p.m.-5 p.m. Monday and anytime between 8 a.m.-5 p.m. Tuesday through Thursday, to customize and deploy a proactive, always-on AI assistant.
With support from NVIDIA experts, GTC attendees can quickly have an AI agent at their fingertips. Whether technical or just curious, participants will name an agent, define its personality and grant it access to the tools it needs. Think of it as the personal assistant you’ve always wanted, reachable via your preferred messaged app.
To run the custom agent, use cloud compute provided onsite, or harness local accelerated computing by bringing your NVIDIA DGX Spark or GeForce RTX laptop, with no personal data on the device. DGX Spark systems will also be available to buy on site from the NVIDIA Gear Store and Micro Center.
These always-on AI assistants can be applied to virtually any task, including managing a calendar, suggesting vacation destinations, recommending new workout routines and coding a useful app. Make it a specialist or a generalist: it’ll continuously learn new skills that it’s directed toward and prompt the user with new findings.
Sidney Knowles, a machine learning engineer at NVIDIA who staffed the event, said “there’s been a range of perspectives here,” — from the technical folks who came with DGX Sparks in their backpacks, ready to build, to the nontechnical enthusiasts eager to see an OpenClaw demo for the first time.
Developers at the event built AI agents across a slew of industries, she said, from market research and advertising to telecommunications, financial services and physical AI.
But everyone came in with similar levels of excitement, curiosity and one question Knowles said it all kept coming back to: “What can AI do for me?”
Clayton Littlejohn, software engineering consultant at Nationwide, brought his DGX Spark to the build-a-claw event and created an AI agent for evaluating physical AI-readiness in the insurance industry.
“The best thing about the DGX Spark is it’s quick to prototype the problem with emerging technology … especially full-stack technology,” Littlejohn said.
The beauty of the DGX Spark, he went on, is that it enables showcasing the art of the possible, while keeping it all local.
“NVIDIA NemoClaw is able to take that and make it enterprise-fashion, where we can trust and use those guardrails and apply them to our workflows,” he added. “This is unlocking things that we’ve never seen before — the possibilities are limitless.”


Knowles (left) and Littlejohn (right).
To learn more, explore NVIDIA’s new OpenClaw Playbook: a step‑by‑step guide to run OpenClaw on DGX Spark. This playbook helps developers build always-on, local‑first AI agents that work directly with their files, apps and workflows without relying on the cloud.
Check back for updates and see the full lineup of events and activities at GTC.
Thursday, March 19, 5:30 p.m. PT 🔗
Holographic AI Agent of Toy Jensen, aka TJ, Hits the GTC Show Floor
If it seemed that NVIDIA founder and CEO Jensen Huang was everywhere at GTC, he was; at least the holographic AI agent of Toy Jensen — aka TJ, to his friends — was.
Built on LiveX.ai’s fully agentic platform using NVIDIA hardware and software — including NVIDIA Nemotron open models, NVIDIA NIM microservices and more — 18 TJ avatars stood at the ready inside their transparent vessels to answer attendee questions about the conference, as well as about the latest in physical AI, accelerated computing and AI agents.
And, of course, agent TJ was game to pose for as many photos as attendees could want. Among them was the original TJ inspiration, Huang himself, getting a selfie with his other holographic self.
Learn more about how LiveX.ai is developing physical AI agents to transform retail venues, sporting events and other consumer experiences by listening to the NVIDIA AI Podcast with LiveX founder Jia Li.

Wednesday, March 18, 10 a.m. PT 🔗
NVIDIA Celebrates Americas Partners Leading the Next Wave of AI
NVIDIA is honoring the 2026 Americas NVIDIA Partner Network (NPN) award winners, who are leading the next wave of AI innovation, execution and industry impact across the region. These partners are helping customers move from pilots to production with NVIDIA’s full-stack platform — spanning accelerated computing, networking and NVIDIA AI Enterprise software.
This year’s Americas honorees include rising stars, AI excellence and advanced technology partners, as well as leaders in networking, consulting and global systems integrators. They’re modernizing infrastructure, streamlining operations and unlocking new products and services for customers across the Americas.
Partners recognized this year are driving transformation in key industries such as higher education, government, healthcare, financial services, retail, telecommunications, energy and utilities. With NVIDIA, they’re helping organizations apply AI to improve efficiency, enhance experiences and tackle complex challenges that matter to businesses and communities.
Regional and distribution partners further extend this impact by bringing NVIDIA AI infrastructure and partner solutions to customers of all sizes, with local expertise and services that help accelerate time to value.
NVIDIA congratulates all of the 2026 Americas NPN award winners and thanks them for their continued collaboration in leading the next wave of AI across the Americas.
Physical AI 🔗
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA IGX Thor Now Generally Available, Bringing Real-Time Physical AI to the Industrial Edge

As industries move beyond rigid automation toward physical AI, they need a new class of intelligent edge computing devices capable of real-time sensing and inference to power autonomous, safety-critical machines in complex environments.
To meet this demand, NVIDIA IGX Thor — a powerful, industrial-grade platform that delivers real-time physical AI at the edge with high-speed sensor processing, enterprise-grade reliability and functional safety — is now generally available.
Industry Leaders Scale Physical AI With IGX Thor
NVIDIA IGX Thor boosts edge applications in construction, manufacturing, logistics, healthcare and life sciences, and even space exploration.
Caterpillar is developing an in-cabin conversational AI assistant, powered by IGX Thor, to enhance worker productivity and safety, and Hitachi Rail is using IGX Thor to deploy advanced predictive maintenance and autonomous inspection systems on rail networks.
KION Group, the supply chain solutions company, is harnessing IGX Thor and the NVIDIA Halos Outside-In Safety workflow to enable “outside-in” perception — meaning an AI agent augments autonomous robot functional safety mechanisms by using infrastructure-mounted cameras and dynamic virtual safety fences. Ecosystem partners like SICK are accelerating certification of autonomous industrial robots with sensor competence safety critical applications.
Agility and Hexagon Robotics are adopting IGX Thor for real-time AI reasoning and multimodal sensor fusion for their safe, humanoid robots.
Johnson & Johnson is adopting IGX Thor to power its Polyphonic digital surgery platform, bringing real-time AI inference to the operating room. KARL STORZ is using IGX Thor to develop next-generation endoscopy and imaging tools for more accurate diagnoses. Medtronic is evaluating IGX Thor, and LEM Surgical and Horizon Surgical Systems are adopting IGX Thor to deliver precision and functional safety in surgical robot systems.
Built on the NVIDIA Holoscan platform, these systems can process and orchestrate multimodal sensor data — including video, imaging and device telemetry — enabling low-latency AI pipelines required for next-generation, software-defined medical devices and intelligent operating rooms.
Planet Labs is adopting IGX Thor to transform terabytes of multidimensional satellite data into actionable intelligence in orbit, at lower costs. And researchers at CERN are using IGX Thor to run advanced physics-inspired AI models, processing massive data streams at high throughput.
Expanding Ecosystem, Faster Time to Deployment in Physical AI
Beyond performance and safety, industrial AI requires production-ready systems, multimodal sensors and reliable actuators.
Analog Devices, Infineon, NXP Semiconductors, STMicroelectronics and Texas Instruments are integrating radar devices, sensors and motor controllers into the NVIDIA Isaac Sim framework and using NVIDIA Holoscan Sensor Bridge to accelerate the integration of next-generation sensors and actuators for faster, safer and smarter physical AI systems.
Leopard Imaging, D3 Embedded, Sensing and e-con Systems have introduced Ethernet-based camera modules powered by Holoscan Sensor Bridge, enabling low-latency sensor data streaming directly to the GPU for real-time AI processing.
Advantech, ASRockRack, NEXCOM, Connect Tech, Onyx, Inventec and Yuan are building industrial-grade and medical-grade IGX Thor systems with enterprise performance, flexible input-output and custom configurations for different applications.
Barco, Cosmo and XRlabs are adopting IGX Thor and NVIDIA Holoscan to build medical-grade, off-the-shelf edge AI platforms for the medtech industry, enabling device manufacturers to accelerate development and deploy production-ready, medical certified clinical solutions using NVIDIA’s full-stack accelerated computing and AI software.
IGX Thor Developer Kits are available for purchase from worldwide distribution partners. The IGX T5000 module for embedded systems with functional safety and IGX 7000 board kit for high-performance workstations will be available later.
Watch the GTC keynote from NVIDIA founder and CEO Jensen Huang and explore physical AI, robotics and vision AI sessions.
Thursday, March 19, 1:00 p.m. PT 🔗
Robots Rove GTC in Droves
GTC isn’t just a gathering place for AI developers and innovators — it’s a popular destination for robots of all kinds, from humanoids and robotic arms to quadrupeds and autonomous mobile robots (AMRs).
Helpful Humanoids
The AGIBOT humanoid greeted GTC attendees in the convention center. It was trained using NVIDIA Isaac Sim and Isaac Lab.

In the exhibit hall, Agile Robots’ Agile ONE humanoid demonstrated its dexterity in picking and placing items. The company uses Isaac Sim and Isaac Lab to train its robots in simulation.
Humanoid showcased an NVIDIA Jetson Thor-based robot, developed with Isaac Sim, Isaac Lab and NVIDIA Omniverse libraries, that handed attendees the items they requested.
Hexagon Robotics brought its AEON humanoid, trained in Isaac Sim and Isaac Lab, to the show floor to demonstrate various manipulation and teleoperation tasks.


Arms in the Air
ABB Robotics brought a DJ robot that entertained the crowd with its record-spinning skills. The company is integrating NVIDIA Omniverse libraries directly into its RobotStudio programming and simulation suite.
WORKR demonstrated how its robotics technology is automating strenuous, repetitive tile-picking work for ceramics manufacturer Fireclay Tile. Deployed on ABB Robotics hardware, its robotics pipeline is developed with Isaac Sim and Omniverse.
Universal Robots unveiled its UR AI Trainer with Scale AI software, which allows human operators to guide robots through tasks in a leader-follower setup, while the system records synchronized motion, force and visual data to train vision language action models. The company uses Isaac Sim and Omniverse to train its robots in simulation.

Quadrupeds and AMRs Roam the Show
FieldAI showed how its Field Foundation Models help quadrupeds autonomously navigate and map real-world environments. It’s built on NVIDIA technology including NVIDIA Omniverse NuRec libraries and NVIDIA Cosmos world models.
Spectators gathered around Sentigent Technology’s diminutive Rovar X3 robot in the expo hall. This outdoor or indoor companion was trained in Isaac Lab and runs on NVIDIA Jetson.
Over a dozen AMRs from Serve Robotics were seen throughout the GTC campus, delivering food during the keynote pregame at SAP Center and carrying swag all week that attendees could pick out. Serve robots are simulated in Isaac Sim and powered by NVIDIA Jetson Orin.


Workstation 🔗
Monday, March 16, 1:30 p.m. PT 🔗
DGX Spark and DGX Station Paired With NVIDIA NemoClaw Deliver Full-Stack Platform for Autonomous Agents

Artificial intelligence is moving from simple, prompt-based tools to intelligent, long-running systems that reason, plan and act. These autonomous agents don’t just generate text. They can write code, call tools, analyze data, simulate outcomes and continuously improve.
To build and run always-on agents with supercomputing-intelligence, developers need the right infrastructure.
Pairing NVIDIA DGX Spark and NVIDIA DGX Station systems with the new NVIDIA NemoClaw open source stack provides the ultimate platform for locally developing and deploying autonomous, long-running agents, aka claws. The systems bring AI-factory-class performance directly to where intelligence is created — at the desk and inside the enterprise.
Securing Agentic AI With NemoClaw
NVIDIA NemoClaw is an open source stack that simplifies running always-on OpenClaw assistants — more safely and with a single command. It installs the NVIDIA OpenShell runtime, part of the NVIDIA Agent Toolkit, a secure environment for running autonomous agents, and open source models like NVIDIA Nemotron.
Enterprises deploying autonomous agents across proprietary workflows need governance, isolation and control. OpenShell defines how agents access data, use tools and operate within policy boundaries, providing the architectural foundation for secure, always-on AI systems.
Self-evolving agents need dedicated computing to build tools and software as they complete tasks autonomously. DGX Spark and DGX Station are ideal environments for running NemoClaw to build and validate agents with OpenClaw locally before scaling to data center AI factories.
DGX Spark: Scalable AI for Enterprise Teams
While DGX Station represents the most powerful deskside AI system, DGX Spark brings scalable AI infrastructure to domain teams across the enterprise.
With large local memory, strong performance and integration with NemoClaw, DGX Spark is ideal for autonomous agent development and deployment.
DGX Spark now supports clustering up to four systems in a unified configuration, creating a compact “desktop data center” with up to linear performance scaling — without the complexity of traditional rack deployments.
An upcoming software release for DGX Spark is expected to further strengthen orchestration and manageability, enabling faster iteration and smoother transitions from prototype to production.
DGX Spark supports the latest AI models, including NVIDIA Nemotron 3 and leading open models, ensuring developers can build on a modern, continuously evolving AI software stack.
Across industries, organizations are moving DGX Spark from evaluation environments into active enterprise deployment. Financial institutions are accelerating risk modeling. Healthcare researchers are compressing discovery timelines. Energy companies are optimizing operations. Media and telecommunications teams are building real-time content and communications workflows.
DGX Station: Data-Center-Class AI at the Desk
NVIDIA DGX Station — the world’s most powerful deskside supercomputer — has arrived for this new phase of long-thinking, autonomous thinking.
Powered by the NVIDIA GB300 Grace Blackwell Ultra Desktop Superchip, DGX Station provides 748 gigabytes of coherent memory and up to 20 petaflops of AI compute performance. It connects a 72-core NVIDIA Grace CPU and NVIDIA Blackwell Ultra GPU through NVIDIA NVLink-C2C, creating a unified, high-bandwidth architecture built for frontier AI workloads.
It enables developers to run open models of up to 1 trillion parameters and to develop long-thinking autonomous agents directly from their desks.
DGX Station can operate as a personal AI supercomputer or as a shared, on-demand compute node for teams. It supports air-gapped configurations, making it well suited for regulated industries and sovereign environments. Applications developed locally can move seamlessly to NVIDIA GB300 NVL72 systems in the data center or cloud without rearchitecting.
Industry leaders are already harnessing DGX Station to accelerate real-world innovation. Snowflake is using DGX Station to locally test its open source Arctic training framework. EPRI is using and testing it to advance AI-powered weather forecasting to strengthen grid reliability. Medivis is integrating vision language models with DGX Station into surgical workflows. Sungkyunkwan University is using the system to accelerate protein structure analysis. Microsoft Research and Cornell University are tapping DGX Station, enabling hands-on AI training at scale. Respo.Vision, WSP and 1X are deploying AI for advanced sports analytics, synthetic data training, autonomous agents and humanoid robotics.
Systems are available to order now and will begin shipping in the coming months from ASUS, Dell Technologies, GIGABYTE, MSI and Supermicro, and later in the year from HP.
One Architecture — From Desktop to AI Factory
DGX Station and DGX Spark ship preconfigured with the NVIDIA AI software stack, enabling developers to use familiar tools and move seamlessly between local development and large-scale infrastructure.
Developers can run and fine-tune state-of-the-art models on DGX Station — including OpenAI gpt-oss-120b, Google Gemma 3, Qwen3, Kimi K2.5, Mistral Large 3, DeepSeek V3.2 and NVIDIA Nemotron — and tap into a wide variety of familiar tools and platforms from 1x, Aible AI, Anaconda, Docker, Red Hat, JetBrains, Docker, Inc., Ollama, llama.cpp, ComfyUI, LM Studio, Llm.c, Weights & Biases (acquired by CoreWeave), Odyssey, Roboflow, VLLM, SGLang, Unsloth, Learning Machine, Quali, Lightning AI and more.
By unifying chips, systems, networking and software into a coherent architecture, NVIDIA enables enterprises to build once and scale everywhere — from a deskside DGX Station to multi-node DGX Spark clusters to full AI factories.
Learn more about DGX Spark at NVIDIA GTC. Attend sessions on scalable autonomous agents and AI infrastructure, see live NemoClaw-enabled AI agents and multi-node Spark demos in the exhibit hall, or visit this webpage to access deployment guides and beta resources.
Developers can get started quickly on DGX Station and test a large sample of AI workflows. Learn more and order a DGX Station from an NVIDIA partner.
See notice regarding software product information.
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA RTX PRO 4500 Blackwell Server Edition Brings Universal Acceleration From Data Center to the Edge

The NVIDIA RTX PRO 4500 Blackwell Server Edition brings GPU acceleration capabilities to the world’s most widely adopted enterprise data center and edge computing platforms, delivering a staggering leap in performance compared with traditional CPU-only servers: 100x performance for vision AI applications and up to 50x performance for vector databases.
Power-Efficient Performance for Enterprise Data Centers
For enterprises looking to optimize performance, efficiency and costs, RTX PRO 4500 Blackwell delivers breakthrough capabilities in a compact, 165-watt, single-slot form factor. Fifth-generation Tensor Cores, fourth-generation RTX technology and a fully integrated media pipeline make it an optimal platform for data processing, vision AI, small language model (SLM) inference, video processing and visual computing.
It’s also slated to support virtual workstations with the upcoming vGPU 20.0 release, and NVIDIA Multi-Instance GPU technology for hardware-based partitioning.
Additional highlights include:
- SLM AI Inference gets up to a 10x performance boost for the NVIDIA Nemotron Nano 9B model vs. the NVIDIA L4 GPU.
- Apache Spark accelerated by NVIDIA cuDF provides up to 5x faster query performance and 10x better total cost of ownership on 10 terabytes of data vs. CPUs.
- Vision AI with the NVIDIA Metropolis platform provides up to 4x performance for video summarization with the NVIDIA Cosmos Reason 2 model vs. the NVIDIA L4 GPU.
Industry Leader Adoption
Leaders across multiple industries including IT services, life sciences and telecommunications are adopting the NVIDIA RTX PRO 4500 Blackwell GPU to power AI and visual computing workloads.
NTT DATA is accelerating client access to secure, AI-driven data insights from video captured at edge locations. In biotech, Pacific Biosciences plans to integrate RTX PRO 4500 Blackwell into its sequencing platforms to drive breakthroughs in genomic analysis. Nokia will deploy RTX PRO 4500 Blackwell in its AI‑RAN Base Stations, creating a distributed computing network that connects billions of devices for edge AI agents.
Comprehensive Ecosystem Support
Enterprises adopting RTX PRO 4500 Blackwell will benefit from broad software ecosystem support. This includes AI infrastructure software from Broadcom, Canonical, Red Hat, Nutanix and SUSE; data platforms including Databricks and Snowflake; AI platforms such as Dataiku, DataRobot and Ray on Anyscale; security software including Cisco AI Defense; and vision AI and analytics solutions such as Ambient AI, BriefCam and Ipsotek, an Eviden Business.
NVIDIA RTX PRO Servers with the RTX PRO 4500 Blackwell Server Edition GPU are also featured as part of the updated NVIDIA Enterprise AI Factory validated design and the NVIDIA AI Data Platform, a customizable reference design for building modern storage systems for enterprise agentic AI.
Storage partners integrating RTX PRO 4500 Blackwell as a part of their AI Data Platform include Cloudian, DDN, Dell Technologies, Everpure, Hammerspace, Hitachi Vantara, IBM, NetApp, Nutanix, VAST Data and WEKA.
Availability
RTX PRO Servers with RTX PRO 4500 Blackwell GPUs are available to order from system builders including Cisco, Dell, HPE, Lenovo and Supermicro — with additional server configurations from Aivres, ASRock Rack, ASUS, Compal, Foxconn, GIGABYTE, Inventec, Lanner, MiTAC Computing, MSI, Pegatron, Quanta Cloud Technology (QCT), Sanmina, Wistron and Wiwynn.
Akamai Cloud and Amazon Web Services (AWS) will be among the first cloud service providers to offer RTX PRO 4500 Blackwell Server Edition instances.
Learn more about the RTX PRO 4500 Blackwell Server Edition GPU.
See notice regarding software product information.
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA Partners Unveil New NVIDIA RTX PRO Blackwell-Based Workstations

At GTC, NVIDIA partners unveiled a new wave of AI‑ready workstations that pair NVIDIA RTX PRO Blackwell GPUs with the Intel Xeon 600 processors for workstations. These refreshed designs power workflows from everyday AI exploration to demanding 3D design and simulation.
Lenovo is expanding its ThinkPad P series mobile workstations with — ThinkPad P14s i Gen 7, ThinkPad P16s Gen 5 AMD, ThinkPad P16s I Gen 5 and ThinkPad P1 Gen 9 — as well as its ThinkStation lineup with the powerful new ThinkStation P5 Gen 2, configurable with up to two RTX PRO 6000 Blackwell Max-Q Workstation Edition GPUs.
Dell is introducing a modernized Dell Pro Precision portfolio with Dell Pro Precision 5 and 7 Series mobile workstations and Dell Pro Precision 9 T2, T4 and T6 desktop workstations.
HP plans to future-proof HP Z desktop workstations to support future NVIDIA GPU generations. Learn more at HP Imagine on March 24.
This new generation of workstations gives enterprises more flexibility in how they refresh fleets — whether prioritizing mobility, deskside performance or maximum expandability. RTX PRO Blackwell GPUs with the latest drivers provide day-zero model readiness — including for NVIDIA Nemotron open models and key community models — so teams can begin experimenting with and deploying AI workloads right away.
Software providers such as Ollama, SGLang and LM Studio offer models and tools tuned for RTX PRO, enabling developers and creators to run advanced AI workloads directly on these new workstations using familiar workflows.
Securing Agentic AI Workflows Locally With NVIDIA NemoClaw
As AI moves from simple prompts to agentic AI — long-running systems that reason, plan and act — developers need secure infrastructure to build always-on AI assistants. These new workstations provide an ideal desktop platform for the NVIDIA NemoClaw open source stack, which is designed for safely developing and deploying autonomous, long-running agents.
Harnessing up to 4,000 TOPS of local AI compute and 96 gigabytes of GPU memory on the RTX PRO 6000 Blackwell Workstation Edition and RTX PRO 6000 Blackwell Max-Q Workstation Edition GPUs, NemoClaw simplifies running OpenClaw assistants safely. As part of the NVIDIA Agent Toolkit, it installs the NVIDIA OpenShell runtime — a secure environment for running autonomous agents and open source models like NVIDIA Nemotron. This gives enterprises the governance, control and privacy required to tackle complex business tasks entirely on premises.
Learn more and see these RTX PRO‑powered workstations in action at GTC in the NVIDIA demo booth and at partner booths (Dell 721, HP 1931 and Lenovo 431).
Tuesday, March 17, 2:30 p.m. PT 🔗
NVIDIA DGX Station GB300: The Machine on the Desk

The first NVIDIA DGX Station systems, powered by NVIDIA GB300 superchips, have arrived in the hands of AI’s pioneering developers, marking a step forward in deskside development with frontier-scale models and agents.
The first system, Dell Technologies’ Dell Pro Max with GB300, was delivered Friday, March 6, to Andrej Karpathy in Palo Alto. Karpathy was a founding member and research scientist at OpenAI from 2015 to 2017, contributing to its early foundational work in deep learning — particularly in computer vision, generative modeling and reinforcement learning — which helped establish the organization’s initial research direction.
More deliveries are in progress. The latest: Matt Berman — YouTuber, developer, AI enthusiast — has made a practice of taking AI research straight from paper to working system, shortening the path from idea to experiment.
DGX Station GB300 is built on the same NVIDIA GB300 superchip architecture used in the data center, packed into a deskside system. The system includes 748GB of coherent memory, delivers up to 20 petaflops of FP4 performance and supports AI models up to 1 trillion parameters for frontier AI development, right on users’ desktops. Work developed locally on DGX Station can scale to the cloud or data center on the same GB300 architecture.
The early placements reflect a need for deskside computing for AI development of long‑running, autonomous agents — systems that reason, plan and execute work over time with access to local tools and data.
That shift gained visibility with OpenClaw, the open source autonomous agent framework created by Peter Steinberger. OpenClaw showed how agents with access to local files and applications, capable of writing code, generating sub‑agents, retaining state and executing complex workflows, can carry work forward on their own. The project surpassed 100,000 GitHub stars and attracted more than 2 million visitors in its first week.
Complementing the hardware, NVIDIA is focusing on efforts to advance long-running autonomous agents by contributing to OpenClaw with NVIDIA NemoClaw — an open source stack that simplifies running OpenClaw always-on assistants more safely with a single command.
As part of the NVIDIA Agent Toolkit, it installs the NVIDIA OpenShell runtime — a secure environment for running autonomous agents and open source models like NVIDIA Nemotron.
The combination of NemoClaw and DGX Station provides the ultimate developer platform for building and running more secure, autonomous, long-running agents locally.
As more systems are delivered to developers, the effort points to a broader inflection point. Agentic AI is moving from experimental prompts to persistent systems, and for some of that work, high‑end compute is returning to the desk.
Build an agent of your own at NVIDIA’s build-a-claw event in the GTC Park, running daily through March 19 from 8 a.m.-5 p.m. — to customize and deploy a proactive, always-on AI assistant.
Cloud 🔗
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA and Amazon Web Services Expand Compute Capacity in the Agentic AI Era
NVIDIA and Amazon Web Services (AWS), an Amazon.com company, are announcing an expanded partnership to deploy NVIDIA AI infrastructure to support growing compute demand for every industry in the age of agentic AI. AWS will deploy NVIDIA AI infrastructure including LPUs and more than 1 million NVIDIA GPUs.
This partnership will enable the large-scale deployment of NVIDIA AI infrastructure across AWS’s compute portfolio. The expanded infrastructure will span the full NVIDIA AI computing stack, including the NVIDIA Blackwell and Rubin GPU architectures, NVIDIA RTX PRO Blackwell Server Edition GPUs for enterprise AI workloads and NVIDIA Groq 3 LPUs for ultralow-latency inference. AWS and NVIDIA are also collaborating on Spectrum networking and other infrastructure areas.
The deployment of more than 1 million NVIDIA GPUs will begin this year across AWS’s global cloud regions. Built on NVIDIA accelerated computing and AWS’s global cloud platform, these deployments will enable AWS AI factories to operate as unified compute engines — delivering unmatched efficiency, performance and security for training and deploying next-generation AI systems.
By integrating NVIDIA’s accelerated computing with AWS’s advanced cloud services and infrastructure technology, the companies aim to provide enterprises, startups and research institutions with the infrastructure needed to build and scale agentic AI systems — capable of reasoning, planning and acting autonomously across complex workflows. Together, the companies will deliver a significant leap forward in the speed, scale and reliability of AI infrastructure worldwide.
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA and AWS Collaborate to Expand GPU-Accelerated Solutions
NVIDIA and Amazon Web Services (AWS) are expanding their collaboration to extend the capabilities of NVIDIA-powered data processing on AWS, as well as adding support for the NVIDIA Nemotron family of open models.
Since 2010, NVIDIA and AWS have collaborated to deliver large-scale, cost-effective and flexible GPU-accelerated solutions spanning infrastructure, software and services to offer a full-stack suite that accelerates time to solution when building and deploying AI in production.
Accelerate Data Processing on AWS With NVIDIA RTX PRO 4500
The new NVIDIA RTX PRO 4500 Blackwell Server Edition GPU is coming soon to AWS through a new type of accelerated computing Amazon EC2, delivering NVIDIA Blackwell performance in the cloud. AWS is the first cloud provider to announce support for NVIDIA RTX PRO 4500. These Amazon EC2 instances, when used with Amazon EMR, are well-suited for data processing workloads. The new Amazon EC2 instances are built on the AWS Nitro System, which delivers the enhanced security, stability and resource efficiency that data processing workloads will require in production.
NVIDIA Nemotron Powers Salesforce Agentforce
The NVIDIA Nemotron Nano 3 model is available as a model on Amazon Bedrock for Salesforce Agentforce, expanding Agentforce to new high-throughput applications such as batch processing or high-concurrency B2C apps. According to Salesforce’s Agentic Benchmark for CRM, Nemotron 3 Nano is the most cost-efficient model for summarization and generation use cases.
Reinforcement Fine-Tuning for NVIDIA Nemotron Models Coming Soon on Amazon Bedrock
Developers will soon be able to fine-tune NVIDIA Nemotron models directly on Amazon Bedrock using reinforcement fine-tuning (RFT). This is significant for teams that need to align model behavior to specific domains, whether that’s legal, healthcare, finance or any other specialized field. Reinforcement fine-tuning lets developers shape how a model reasons and responds, not just what it knows. Nemotron Nano 3 will soon support RFT, bringing these capabilities to AWS customers.
See notice regarding software product information.
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA Open Models With Microsoft Foundry and Azure Local Power Agentic AI, Sovereign AI and Physical AI Systems
At GTC, Microsoft announced updates to its unified platform for agentic and physical AI systems, accelerating the shift from experimentation to production. Combining Microsoft Foundry with NVIDIA’s open models and accelerated computing creates a unified stack to simplify customization while meeting strict data sovereignty requirements.
To power these inference-heavy workloads, Microsoft has rapidly integrated the latest NVIDIA accelerated computing platforms into its liquid-cooled Azure data centers. This builds on a massive infrastructure expansion in which Microsoft has deployed hundreds of thousands of GPUs liquid-cooled NVIDIA Grace Blackwell GPUs across its global data centers in less than a year. Azure was also the first hyperscale cloud provider to power up the new NVIDIA Vera Rubin NVL72 systems, which will roll out globally over the coming months.
Building Specialized Enterprise Agents With NVIDIA Nemotron on Microsoft Foundry
Developers can now build and deploy specialized agents with NVIDIA Nemotron open models directly in Microsoft Foundry.
At the agent platform layer, Microsoft Foundry Agent Service is generally available to support building, deploying and operating AI agents at scale. New features include enhanced observability and voice capabilities for agents, enabling customers to move from experimentation to production fast on an agent platform that prioritizes security and governance.
Using Azure compute, accelerated by NVIDIA Blackwell and Rubin platforms, teams can easily access these models in Foundry’s model-as-a-platform environment. The lineup will expand across the latest Nemotron 3 family of reasoning, speech and vision models, including Nemotron 3 Super, as well as AI safety guardrail models. Nemotron models will also arrive on Azure as a managed application programming interface service later this year.
Microsoft Security is also working on NVIDIA Nemotron and NVIDIA NemoClaw to increase agent safety, security and efficiency.
“At Microsoft, trust and security are critical to responsible agentic AI adoption. That’s why we’ve been partnering with NVIDIA on adversarial learning that includes Nemotron and OpenShell to better protect the industry and enterprise security applications with real-time, adaptive runtime protection,” said Alexander Stojanovic, vice president of Microsoft Security’s NEXT AI team. “Early results are showing 160x improvement in finding and mitigating AI-based attacks.”
Accelerating Sovereign AI on Azure Local
For regulated industries and government customers, Azure Local is expanding sovereign AI capabilities in customer-controlled environments. Azure Local now supports the NVIDIA RTX PRO 6000 Blackwell Server Edition GPU. Support for the NVIDIA RTX PRO 4500 Blackwell Server Edition GPU is coming soon, with support for the NVIDIA Rubin platform expected later this year. Paired with Foundry Local services, customers can run models on premises while keeping data, inference and governance under their control.
Powering Physical AI on Azure
To accelerate robotics and physical AI, NVIDIA blueprints and open foundation models, including NVIDIA Cosmos world models and NVIDIA Alpamayo models for autonomous vehicle development, are now available on GitHub and Foundry. Find more on NVIDIA’s physical AI announcements from GTC.
Learn more about this strategic collaboration in the Official Microsoft Blog.
Tuesday, March 17, 9:00 a.m. PT 🔗
Oracle and NVIDIA Team to Accelerate Vector Search and Enterprise Data Processing With NVIDIA cuVS
Oracle and NVIDIA are partnering with customers to put GPU‑accelerated vector index builds into action for real‑world workloads. Oracle Private AI Services Container, initially announced with CPU execution, is designed to support NVIDIA GPUs and the NVIDIA cuVS open source library for vector search and index generation. This announcement builds on the launch of Oracle AI Database 26ai and Oracle Private AI Services Container at Oracle AI World 2025.
Companies using Oracle AI Database 26ai to manage massive unstructured and multimodal data estates can now offload vector index creation to NVIDIA accelerated computing, significantly reducing index build times.
Bolstering Healthcare Workflows
Early healthcare innovators Biofy and Sofya are among the first to explore GPU‑accelerated index builds on Oracle Database, targeting faster, more accurate AI‑powered clinical and analytics use cases.
Sofya — an AI healthcare company delivering real‑time medical transcription and structured clinical documentation, with over 1 million clinical encounters already processed — offers a real-time platform that generates clinical notes and suggests evidence‑based protocols during patient interactions. This demands fresh, searchable access to massive medical datasets.
Roughly 1.5 million new medical articles are published each year, and Sofya must keep its AI recommendations closely aligned with the latest clinical evidence. Sofya taps into a dataset of roughly 500 million vectors over 3 terabytes of U.S. health library data, originally requiring days to build vector indexes. GPU‑accelerated index builds through Oracle Private AI Services Container and NVIDIA cuVS can help Sofya vastly accelerate this process.
Biofy, a health-tech company, uses AI to rapidly identify bacterial infections, predict antibiotic resistance and recommend targeted treatments in hours instead of days. It uses Oracle Cloud Infrastructure with NVIDIA GPUs to scale training and inference, storing genomic vectors in Oracle Autonomous Database with AI Vector Search to deliver low latency, cost efficient queries. With a fine‑tuned Llama‑based model, Biofy continuously generates synthetic DNA sequences to stay ahead of evolving bacteria, so scientists don’t need to constantly run expensive wet‑lab experiments. cuVS enables Biofy to accelerate the creation of vector search indexes.
Learn more about all the latest Oracle and NVIDIA announcements at GTC, including the new OCI Supercluster with Vera Rubin, on the Oracle blog.
Tuesday, March 17, 9:00 a.m. PT 🔗
NVIDIA Cloud Partners Double Global AI Factory Footprint to Advance Sovereign AI

AI factory growth is soaring.
Announced at GTC, NVIDIA Cloud Partners (NCPs) have doubled their AI factory footprint year over year, advancing sovereign AI in the U.S., Australia, Germany, Indonesia, India and more.
NCPs have now cumulatively deployed more than 1 million NVIDIA GPUs in AI factories across the globe, representing more than 1.7 gigawatts of AI capacity.
That’s enough compute power to study the molecular interactions of billions of protein structures and pharmaceutical compounds in just weeks, or to simulate tens of billions of driving miles per day to train autonomous vehicles in hyperrealistic 3D physics engines.
The 2x growth of NCP deployments since last year’s GTC — when NCPs had deployed a cumulative 400,000 NVIDIA GPUs representing 550 megawatts of AI capacity — showcases how organizations are generating intelligence at a larger scale than ever. And being a part of the NCP program means they’re all equipped to support future generations of NVIDIA AI infrastructure.
Here are some key NCPs deploying cloud-based AI factories that bring together NVIDIA accelerated computing, networking and optimized AI software:
- Fintech startup innovation hub TechQuartier is working with sandbox-as-a-service provider NayaOne to create a sovereign Supercharged Sandbox platform in Germany. NayaOne runs on Sovereign AI Factory Frankfurt — which harnesses NVIDIA AI Enterprise software and is powered by NCP Polarise.
- Zadara and DDN are announcing a strategic partnership to deliver high-performance AI infrastructure for multi-tenant sovereign clouds and AI factories, built on NVIDIA reference architectures. Together, the companies will enable service providers, telcos and enterprises to deploy NVIDIA-powered AI infrastructure quickly, securely and efficiently while maintaining full control over compliance, cost, tenant isolation and performance service-level agreements.
- YTL, a Malaysia-based NCP and AI lab, is using Nemotron 3 technologies and data in its ILMU family of large language models, trained on local contextualized data and deployed in Malaysia.
- German research consortium SOOFI, funded by the German Federal Ministry for Economic affairs and Energy, is training new sovereign AI models as part of the Sovereign Open Source Foundation Models initiative to strengthen European AI sovereignty and build the foundation for new, widely used AI applications. SOOFI is building its foundation models using NVIDIA Nemotron 3 Nano and Super, as well as Deutsche Telekom’s industrial AI cloud, to provide the sovereign, secure, high-performance environment required to build trusted and scalable AI models.
Learn more about the NCP program.
Healthcare 🔗
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA Releases Open Physical AI Models for Healthcare Robotics
Surgical robotics leaders including CMR Surgical and Johnson & Johnson MedTech, along with surgical physical AI platform developers PeritasAI and Proximie, are among the first to adopt healthcare-specific physical AI tools unveiled at GTC.

For years, AI in healthcare has lived primarily on screens, analyzing medical images and predicting patient outcomes. Today, it moves beyond the screen and into the physical world as NVIDIA launches the first domain-specific physical AI platform for healthcare robotics.
Leaders and innovators in surgical robotics — including CMR Surgical, Johnson & Johnson MedTech, Moon Surgical and Rob Surgical — are adopting NVIDIA’s healthcare-specific physical AI tools to accelerate workflows including synthetic data generation, robotic policy evaluation and digital twin creation.
PeritasAI is integrating these technologies to build a physical AI platform for surgical operations, integrating robots and multi-agent intelligence to sense, coordinate and act in real time. Another physical AI platform developer, Proximie, is developing vision language models that can support surgical teams in the operating room.
Announced at GTC, these tools provide the robust, open infrastructure developers need to transform care delivery with a new generation of healthcare robots. They include:
- Open-H, the world’s largest healthcare robotics dataset. Built with about three dozen collaborators, Open-H represents the real-world diversity and complexity of surgical procedures, providing over 700 hours of surgical video to accelerate the development of advanced, generalizable robotic systems.
- Cosmos-H, an open model family including Cosmos-H-Surgical, based on NVIDIA Cosmos for domain-specific, physics-based synthetic data generation at scale. Featuring three models that generate surgical video from prompts, reference images or videos, and paired robot kinematics, Cosmos-H enables developers to augment real datasets with lifelike simulations — and evaluate robotic policies by predicting the future state of surgical environments.
- GR00T-H: This vision language action (VLA) model, based on NVIDIA Isaac GR00T N, processes text commands describing clinical tasks and generates motion commands, known as action tokens. Trained on Open-H, the model can be used to train and evaluate robots developed to perform complex physical actions in healthcare environments.
- Rheo: This developer blueprint, available within the Isaac for Healthcare developer framework for AI healthcare robotics, enables developers to create physically accurate simulations of hospital environments. It can be used to safely develop and test automation strategies at scale by simulating clinical workflows, medical device interactions, human movement and hospital logistics.
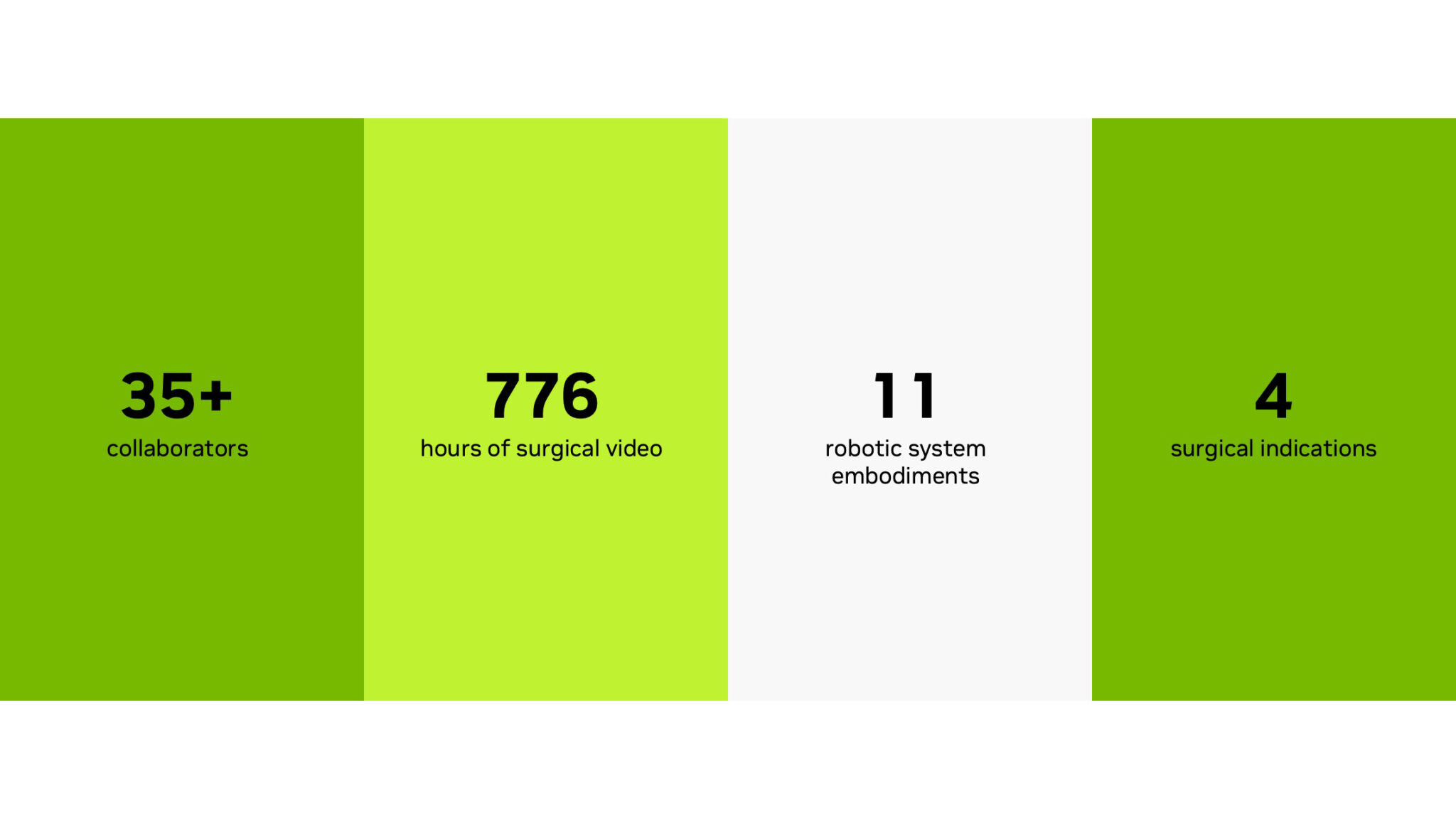
The Open-H dataset, built with 35 collaborators, includes 776 hours of surgical video, 11 robotic system embodiments and four surgical indications.
Surgical robotics, imaging and hospital automation leaders are already using NVIDIA physical AI technology for healthcare robotics:
- CMR Surgical is contributing close to 500 hours of surgical video to Open-H to help pretrain GR00T-H. The company is also using Cosmos-H to generate physically accurate synthetic surgical data and evaluate new robotic policies.
- Johnson & Johnson MedTech is using a Cosmos-based foundation model and anatomical simulation in Isaac for Healthcare to generate and enhance data for post-training workflows for the MONARCH Platform for Urology.
- PeritasAI, is using Isaac for Healthcare and Rheo to train humanoid robots and VLA models that bring embodied intelligence into surgical environments — supporting surgical teams through real-time situational awareness, sterile coordination and intelligent management of instruments, implants and operating room workflows. This work is in collaboration with Lightwheel and Advent Health Hospitals.
- Proximie is using Cosmos-H to train multimodal vision language models that combine operating room images with intraoperative video. These models power real-time AI agents that provide surgical insights and orchestration across the surgical pathway.
Additional adopters of NVIDIA healthcare robotics technology include Moon Surgical and Rob Surgical.
Open-H, Cosmos-H and GR00T-H are now available on GitHub and Hugging Face for developers to post-train and adapt for specific surgical scenarios. These tools pair with NVIDIA Isaac for Healthcare and the Rheo blueprint to power simulation pipelines for the training and evaluation of surgical robots.
Learn more about the Rheo blueprint on the NVIDIA technical blog.
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA, Google DeepMind, EMBL Unveil World’s Largest Dataset of Protein Complexes to Accelerate AI-Driven Biology and Drug Discovery

NVIDIA, Google DeepMind, EMBL’s European Bioinformatics Institute and the Seoul National University Steinegger Lab have massively expanded the AlphaFold Protein Structure Database, adding 1.7 million high-confidence predicted protein complexes to the searchable database, while making about 30 million additional predicted structures available for bulk download.
The newly added dataset — the largest of its kind — turns the database into a comprehensive resource for modeling protein-to-protein interactions at an unprecedented scale.
Google DeepMind’s AlphaFold-Multimer model provided AI-predicted protein structures for the database. It was accelerated by integrating NVIDIA computing libraries — NVIDIA TensorRT and cuEquivariance — into the OpenFold inference pipeline, achieving over 100x faster inference compared to the original.
The database provides these precomputed protein structures to serve as hypotheses, accelerating experimental testing in the discovery of new drug targets and disease biology.
This removes a massive computational barrier for researchers, particularly those in low-resource settings lacking access to advanced supercomputers.
This initiative prioritizes reference proteomes — sets of proteins that represent taxonomic diversity — and the World Health Organization priority list to bolster infectious disease research.
For the pharmaceutical industry, these predicted structures serve as powerful starting hypotheses, significantly accelerating downstream wet-lab experiments and saving crucial time and resources.
Wednesday, March 18, 9:00 a.m. PT 🔗
NVIDIA Nemotron Open Models, NeMo Libraries and AI Data Flywheel Power Next Generation of Digital Health Agents
The NVIDIA Nemotron family of open models and NVIDIA NeMo libraries are providing clinicians, researchers and developers with open weights and recipes to build and deploy customized digital health agents directly on their own infrastructure.
As multimodal healthcare data volumes explode, driven by everything from high-resolution imaging to longitudinal patient records, the industry faces a scaling challenge that traditional models struggle to meet. High-efficiency, low-latency Nemotron open models provide the specialized tools needed to process this massive data influx, enabling researchers to move away from costly, closed-system dependencies while reducing latency and operational expenses.
Using NeMo, developers can fine-tune models for medical vocabulary that general-purpose AI often misses. These efficiencies are already translating to the bottom line. In a recent study, Heidi Health reported a 75% reduction in latency and a 64% reduction in operating expense by shifting to the Nemotron Speech model for clinical documentation.
Healthcare companies are already adopting Nemotron to power their agentic solutions. Hippocratic AI is using NeMo to train large, domain-adapted models for clinical conversations with patients. Sword Health is using NeMo RL to fine-tune its AI-driven mental health support model. IQVIA is partnering with NVIDIA to develop AI agents for life sciences, building on IQVIA’s domain expertise, proprietary data and commitment to secure, responsible AI. OpenEvidence is deploying Nemotron to build agents that synthesize medical intelligence. Verily plans to integrate Nemotron to power its AI companion, Violet, which helps individuals interpret their health data and navigate symptoms.
By integrating these open models into the fabric of healthcare delivery, NVIDIA is laying the groundwork for a future where patient care is personalized, data-secure and exponentially more efficient.
NVIDIA’s latest State of AI in Healthcare and Life Sciences survey revealed that 82% of healthcare leaders now view open source as a critical part of their strategy. By adopting open models, fine-tuning them and running them in their own environment, healthcare organizations can achieve data sovereignty — ensuring control over transparency and reproducibility, while maintaining leading accuracy for complex, agentic applications.
Learn more about NVIDIA AI in healthcare and life sciences.
Wednesday, March 18, 9:00 a.m. PT 🔗
NVIDIA BioNeMo Platform Unlocks Groundbreaking Datasets to Advance Genomic Therapies and Virtual Cell Models
Decoding neural circuits: whole-brain visualization of genome-scale CRISPR perturbations. Video courtesy of PerturbAI.
Breakthrough therapies — including gene editing, immunotherapy and RNA medicines — require rapid, large-scale genomic analysis. Integrating massive genomic and single-cell data is essential to discovering targets and designing safer interventions, but traditional pipelines can slow research from months to years.
The NVIDIA BioNeMo platform is a suite of GPU-accelerated tools, frameworks and AI models — including NVIDIA Parabricks and NVIDIA CUDA-X Data Science (DS) libraries — that dramatically speeds up genomics workflows.
At GTC, NVIDIA highlighted a new wave of healthcare and life sciences companies processing data and developing models with BioNeMo to unlock therapeutic discoveries.
Basecamp Research’s Trillion Gene Atlas
Basecamp Research’s Trillion Gene Atlas (TGA) — launched in collaboration with Anthropic, Ultima Genomics and PacBio, and powered by NVIDIA AI infrastructure — is a biological data collection initiative designed to expand insights on genetic diversity a hundredfold.
At GTC, Basecamp Research, which collects novel genomic data on millions of new species from thousands of sites globally, announced a 100x expansion of its BaseData, a dataset that’s already 10x larger than all public databases combined. This expansion will allow researchers to design and develop new, curative therapies using the next generation of biological foundation models.
Using TGA, Basecamp aims to process quadrillions of DNA base pairs with NVIDIA Parabricks, which offers a speedup of 10x for data processing — meaning analyses that would have taken over 20 years could now take less than two years.
Tahoe Scales Toward Billion-Cell Scale for Virtual Cell Models
Tahoe Therapeutics built Tahoe-100M, the world’s largest individual single-cell dataset, to create a new virtual cell model architecture — an AI-powered simulation that mimics the complex, dynamic behavior of real biological cells so therapeutic discoveries can be made without having to implement large, costly wet lab experiments.
With a hundred million cells across 370+ compounds and 50 cell lines, Tahoe-100M pushes single-cell analysis to a scale only possible through GPU acceleration.
The Tahoe-100M training pipeline runs end to end on NVIDIA H200 GPUs and taps into the NVIDIA cuVS library. Tahoe plans to scale to 1 billion cells by running on an NVIDIA DGX B200 system and using the RAPIDS-singlecell framework, developed by scverse.
PerturbAI’s In-Vivo Brain Perturbation Dataset
In collaboration with the NVIDIA Biology Foundation Model Research team, PerturbAI has unveiled the world’s largest in-vivo CRISPR functional genomics atlas — a dataset of nearly 8 million brain-wide cells that establishes one of the largest causal maps of gene function in living tissue.
The company is using NVIDIA CUDA-X DS to discover new biological mechanisms underlying neurodegeneration, psychiatric and metabolic diseases. NVIDIA RTX PRO 6000 GPU-accelerated workflows and new RAPIDS-singlecell features for perturbation analysis sped up the team’s analysis from days to near real-time.
Try the NVIDIA Blueprints for single-cell analysis and genomics, and learn more from the GTC session, “Accelerate the Path to In-Silico Life Sciences and Drug Discovery.”
Research and Open Source 🔗
Wednesday, March 18, 6:00 p.m. PT 🔗
NVIDIA CEO Jensen Huang Convenes AI’s Open Model Vanguard at GTC
The CEOs of Mistral, Perplexity, Cursor, Thinking Machines Lab and others joined Huang on stage to map what comes next in the open frontier era.

This year, NVIDIA founder and CEO Jensen Huang declared, the question of return on investment in open AI stops being theoretical — it starts getting answered.
Huang hosted 11 leaders of the open model ecosystem at GTC on Wednesday — not to debate open versus closed innovation, but to map what comes next.
The 90-minute session — spanning two back-to-back panels at the San Jose Civic — brought together the CEOs of LangChain, Cursor, Reflection AI, Perplexity, Thinking Machines Lab, Mistral, OpenEvidence and Black Forest Labs, alongside Hanna Hajishirzi, senior director of natural language processing at AI2, and Anjney Midha, founder of AMP PBC.
Huang arrived with a reframe.
“Proprietary versus open is not a thing,” he told the audience. “It’s proprietary and open.”
The first panel focused on how the open model ecosystem has evolved. It included LangChain’s Harrison Chase, Perplexity’s Aravind Srinivas, Cursor’s Michael Truell, Reflection AI’s Misha Laskin and Thinking Machines Lab’s Mira Murati.

Truell argued the industry is witnessing the rise of a third type of company — neither pure foundation model lab nor pure application builder, but something in between: A company that “takes the best the market has offered at the API level, does great work on the modeling frontier and wraps them all into the best product for a vertical.”
The result is a new class of AI company, one that integrates models, systems and product into a single stack.
The conversation kept returning to agents.
Srinivas described Perplexity’s vision as building “the orchestration system of everything AI can do,” where models become instruments and the system does the conducting.
“We’re able to operate at an abstraction above models, finally,” he said. “That’s what I find very exciting.”
Laskin characterized standalone models as “brains without bodies.” He argued that the release of Open Claw provided the “limbs” necessary for AI to interact with file systems and perform autonomous work.
Chase pointed to a quieter shift underway. “There’s this new term called harness engineering,” he said — the discipline of everything around a model: how it connects to systems, what sub-agents it uses and when to invoke which tools.
“You look at Claude Code — the model is great, but the harness around that model is really great as well,” he added.
Murati pulled back to the longer arc. “We’re at an exponential, and everything is very compressed,” she said, “and it cannot be done completely in the large labs.”
Opening access — to models, infrastructure and post-training — is already accelerating research in ways the closed model world can’t.
Huang kept returning to a simple idea: AI is not a model, but a system.
And coding, he suggested, was just the beginning.
“Coding is not just software engineering,” he said. “It is the description, codified, of business processes … almost all work.”
From Systems to Stakes
The second panel brought together Mistral’s Arthur Mensch, OpenEvidence’s Daniel Nadler, AI2’s Hajishirzi, Black Forest Labs’ Robin Rombach and AMP PBC’s Midha.
Here, the conversation shifted from systems to stakes.
Huang set them plainly.
“The last three years, all of the questions are, what is the ROI of AI?” he said. “I think now … we’re going to see an inflection of real business economics taking off.”
Nadler made the case for healthcare as a proving ground for agentic systems.
Multistep, repetitive, predictable workflows — prior authorization letters, insurance appeals — are precisely where agents excel.
“You can imagine an agent responding to that insurance denial with an appeal while the physician is sleeping,” he said, “ultimately getting that patient what might be critical or even life-saving treatment.”
Mensch argued that open models confer two advantages: control and customization.
Enterprises need to govern exactly what their agents can access and execute, and adapt them to real-world systems that general-purpose models will never fully capture.
Midha framed the stakes in industrial terms.
Open models require open infrastructure: a computing grid that allows companies of any size to scale. The implication is clear: Systems that are visible and controllable are easier to trust than ones that are closed.
“At the end of the day, if you want to welcome these agents into the most mission-critical parts of our lives, you’re going to have to trust them,” Midha said. “And open models are one of the fastest ways to trust a system.”
The frontier, in other words, is no longer defined by a handful of labs — but by what gets built, deployed and put to work on top of them.
Watch the full session and start building with NVIDIA Nemotron open models.
Thursday, March 19, 12:30 p.m. PT 🔗
When AI Meets the Speed of Light: NVIDIA’s Bill Dally and Google’s Jeff Dean on What Comes Next


A GTC audience packed in as two of the most influential minds in computing took the stage: Bill Dally, NVIDIA’s chief scientist, and Jeff Dean, Google DeepMind and Google Research’s chief scientist, whose work has helped define large‑scale machine learning.
What followed was less a panel discussion than a deep learning jam session — one that traced how AI models are evolving and why hardware architecture is now inseparable from AI progress itself.
Dean opened by reflecting on just how fast model capabilities have advanced, particularly in domains with “verifiable rewards — things like math and coding.” Tasks that once stumped models now execute reliably, and agent‑based workflows are beginning to operate over hours or even days with minimal supervision. That shift, Dean noted, changes the nature of AI systems — from tools that respond to prompts into agents “operating in the background.”
For Dally, that evolution puts latency squarely in the spotlight. If agents are to reason, plan and iterate at scale, inference speed becomes a first‑order design constraint. Much of today’s latency, he explained, doesn’t come from computation at all — but from communication. Every layer transition, every off‑chip hop, every bit moved across a wire costs time and energy. NVIDIA’s response has been to push architectures toward what Dally calls “speed‑of‑light” design: minimizing routing overhead, eliminating queuing and shrinking the physical distance data must travel.
That same principle — don’t move data — surfaced repeatedly as the conversation turned to energy efficiency. A single multiply‑add operation may cost mere femtojoules (tiny units of energy), but fetching the data from external memory can cost thousands of times more. Dally described how placing computation next to memory — exploiting SRAM locality and exploring stacked DRAM technologies — could radically shift that balance. The goal isn’t just lower power, but far more performance using the same power.
The discussion also turned toward using AI to design the very chips that run AI. Dally described how reinforcement learning systems now generate standard cell libraries — a collection of pre-designed, pre-verified and fully characterized basic logic building blocks — overnight, and how internal large language models trained on NVIDIA’s design history help junior engineers navigate decades of architectural knowledge. These systems don’t replace human designers — they amplify them, collapsing timelines and expanding the space of ideas worth exploring.
Looking ahead, both speakers converged on a common theme: codesign. Breakthroughs will come from tight feedback loops between machine learning researchers and system architects. As Dean put it, sometimes you add a small experimental feature to silicon that might pay off big, and you can accelerate “10-20x in the hardware.”
The session closed on a human note. Education, healthcare and scientific discovery stood out as areas where AI’s impact could be profoundly positive — especially when systems become personalized, contextual and continuously learning. “I think the use of AI for healthcare is going to be really impactful,” said Dean.
If the future riffed on between the two industry pioneers onstage comes to pass, it won’t just be faster models running on better hardware. It will be a new computing era where intelligence, efficiency and scale advance in harmony.
AI Researchers Talk on Advances in Reasoning, Simulation and Robotics
A full house was on hand for another highly anticipated talk: a roundtable featuring four pioneering AI researchers, moderated by Two Minute Papers creator Károly Zsolnai‑Fehér.
What followed was a rapid‑fire tour through the breakthroughs shaping the next era of AI — from reasoning‑capable language models to generative simulation and zero‑shot robotics.
NVIDIA Senior Director of AI Research Yejin Choi kicked off the discussion with a look at a new training approach that injects reinforcement learning directly into pretraining. Instead of simply predicting the next token, models are encouraged to think for themselves, exploring possible reasoning paths before generating an answer. The result, she said, is a shift toward “the era of explorative learning,” where models learn to reason earlier and more effectively.
Marco Pavone, senior director of autonomous vehicle research at NVIDIA, followed with updates to NVIDIA Alpamayo, a family of open AI models, simulation tools and datasets for autonomous driving development. The latest release, the Alpamayo 1.5 reasoning vision language action model, adds navigational text‑prompt guidance and new post‑training alignment tools that tighten the link between a model’s reasoning and its actions —- allowing developers to “customize the model to their own datasets.”
From there, the conversation moved into simulation. Sanja Fidler, NVIDIA’s vice president of AI research and head of NVIDIA’s Toronto AI Lab, showcased how neural reconstruction and generative simulation are replacing hand‑authored environments. “We have entered the era of generative simulation,” Fidler said.
Her team’s new AlpaDreams system can generate multi‑camera, physics‑aware scenes in real time, enabling developers to test policies interactively. “AlpaDreams essentially simulates multiple cameras, all real time, in reaction to the policies,” she said.
Rounding out the panel, Yashraj Narang, senior robotics research manager at NVIDIA, demonstrated how neural simulators such as Neural Robot Dynamics are teaching robots complex physical skills entirely in simulation — from gear assembly to cable routing — before transferring them directly to the real world. “We can do hundreds of thousands of these environments in parallel in real time,” he said.
The conversation offered a glimpse of AI’s next frontier: models that reason, simulators that generate worlds and robots that learn in imagination before acting in reality.
Watch the full session and learn more about NVIDIA Research.
Wednesday, March 18, 5:30 p.m. PT 🔗
20 Years of CUDA: Honoring the Architects of the Accelerated Age
What began in 2006 as a bold parallel computing bet has evolved into the foundational heartbeat of modern science and AI.
At GTC, NVIDIA is marking two decades of CUDA — representing the efforts of over 6 million developers innovating across every layer of the computing stack. Today, it serves as a generational bridge between the pioneers who wrote the first kernels and the next wave of builders deploying trillion-parameter AI models.
Led by NVIDIA CUDA Architect Stephen Jones, a panel at GTC Wednesday featured a group of researchers and engineers from Jump Trading, Meta Superintelligence Labs and NVIDIA who highlighted the decades of innovation behind CUDA, how it helps developers solve some of the world’s most complex problems — and how systems like the NVIDIA DGX Spark desktop AI supercomputer will enable the next generation of CUDA developers.
The group shared memories of the early days of CUDA — when “nobody wanted GPUs,” said Paulius Micikevicius, a software engineer at Meta Superintelligence Labs. “We had to go and beg them to consider using GPUs.”
During that time, Wen-Mei Hwu, senior distinguished research scientist and senior research director at NVIDIA, then a professor at the University of Illinois Urbana-Champaign, decided to build a 200-GPU system in two months with a group of grad students.
“A couple of weeks later, 200 GPU boards arrived, and power supply and everything — but there’s no chassis. So we ended up building wood frames for each of these boards … and we ran the Green500 [benchmark] and we got No. 3,” Hwu said. “That was the moment I realized that the energy efficiency of GPUs has incredible potential.”
As the scale of accelerated computing has shifted to rack-scale systems and AI factories, the panelists see desktop AI systems like DGX Spark as a new way forward for prototyping and early development.
“As long as you have that capability to do that initial exploration and something that fits on your desk or your lap, that’s the critical thing,” said Kate Clark, distinguished devtech engineer at NVIDIA. “I don’t see that going anywhere anytime soon. We’ll always have CUDA everywhere.”
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA cuDF and cuVS Adopted by World’s Leading Data Platforms, Fueling Modern Enterprise Data Processing
Enterprises are generating hundreds of zettabytes each year, and organizations are racing to turn that information into insights. NVIDIA cuDF and cuVS — accelerated data libraries built on NVIDIA CUDA‑X — are being adopted by data platforms across industries to deliver up to 5x faster performance while reducing costs for structured and unstructured data processing.
Integrated with the world’s most widely used open source data engines — downloaded over 200 million times monthly by developers — these libraries are harnessed across enterprise data platforms, databases and data lakes. This helps organizations accelerate innovation, develop more accurate models and process more data while managing costs.
For structured data, NVIDIA cuDF accelerates open source data processing engines such as Apache Spark, Presto, DuckDB, Polars and Velox, delivering up to 5x faster processing compared with CPU-only deployments.
For unstructured data — which represents 80% of today’s enterprise data and is growing rapidly — NVIDIA cuVS accelerates leading engines including FAISS, Amazon OpenSearch Service and Milvus. This helps agents and applications extract context, facts and recommendations from vast stores of text, images and video in a fraction of the time.
Powering Enterprise Data Processing Platforms
Google Cloud integrates NVIDIA cuDF to accelerate Apache Spark within Dataproc and cuDF can be easily used within Google Kubernetes Engine (GKE) to reduce processing times for massive ETL jobs from hours to seconds while lowering compute costs.
At Snap, which serves more than 946 million active users, NVIDIA cuDF on GKE cut daily data processing costs by 76%. This enables 10 petabytes of data to be analyzed within a three-hour window — saving millions of dollars.
“Our collaboration with NVIDIA and Google Cloud helps us innovate faster for more than a billion Snapchatters worldwide,” said Saral Jain, chief information officer of Snap. “By lowering data processing costs and scaling experiments across petabytes of data, we’re delivering AI-powered experiences more quickly and efficiently.”
IBM watsonx.data is a hybrid, open data platform that includes open source analytics engines such as Apache Spark and Presto engines for structured data, and a vector engine based on OpenSearch. In early experiments with Nestlé’s Order-to-Cash mart, watsonx.data with NVIDIA cuDF accelerated workloads ran five times faster, with 83% lower cost savings.
“For a company that serves billions, data underpins decision making across our global operations,” said Chris Wright, chief information and digital officer of Nestlé. “Working with IBM and NVIDIA, a targeted proof of concept has demonstrated the ability to refresh global operations data in a few minutes and at reduced cost. Our focus now is on turning this capability into tangible business impact — further improving decision speed in areas such as manufacturing and warehousing, and scaling these capabilities across our enterprise.”
The Dell AI Data Platform with NVIDIA includes accelerated data engines that enable enterprises to quickly and securely activate their Dell AI Factory with AI-ready data. It features an Apache Spark-based processing engine accelerated with NVIDIA cuDF, delivering up to 3x faster performance, and an enterprise-grade vector database accelerated with NVIDIA cuVS, delivering up to 12x higher throughput for vector indexing compared with CPUs.
“Purpose-built for agentic AI, the Dell AI Data Platform with NVIDIA uses accelerated data processing engines to make multimodal data AI-ready in hours instead of days,” said Michael Dell, chairman and CEO of Dell Technologies.
Oracle announced that Oracle Private AI Services Container can greatly accelerate vector index creation in Oracle AI Database using NVIDIA cuVS, helping organizations speed up AI-enabled decisions with the latest information.
“Enterprise AI is moving from experimentation to production,” said Clay Magouyrk, CEO of Oracle. “Oracle AI Database with NVIDIA technology delivers AI-ready data within minutes, enabling applications that were previously impossible.”
NVIDIA cuDF and cuVS are supported by leading enterprise data platforms including EDB Postgres AI, NetApp, Snowflake, Starburst and VAST Data — setting the foundation for the AI‑powered future of data processing.
Quantum 🔗
Monday, March 16, 1:30 p.m. PT 🔗
NVIDIA Launches cuEST for Accelerated Quantum Chemistry in Semiconductor Design
NVIDIA this week launched NVIDIA cuEST, a new NVIDIA CUDA-X library that shifts electronic-structure calculations onto GPUs. Applied Materials, Samsung, Synopsys and TSMC are among the initial adopters.
A leading-edge chip now contains over 50 billion transistors. Engineering them requires answering fundamental physics questions at the atomic scale: how electrons bond, how they migrate and how they interact across films just a few atoms thick.
“As semiconductor scaling reaches the physical limits of materials, the industry requires a massive increase in computing performance to simulate the quantum mechanics of next-generation chip designs,” said Tim Costa, general manager for industrial and computational engineering at NVIDIA. “With NVIDIA cuEST, industry leaders can move past the quantum bottleneck and take high-fidelity chemical modeling directly into production to accelerate semiconductor innovation.”
Industry Impact
- Applied Materials: Applied Materials uses cuEST-accelerated density functional theory (DFT) to model challenging structures, predict material properties and study reaction pathways.
- Samsung: Samsung integrated cuEST into its internal pipeline, already accelerated on GPUs, to deliver yet another up to 5x end-to-end speedup for key quantum-chemistry workloads.
- Synopsys: Powered by cuEST and QuantumATK, Synopsys expanded its functionality to include Gaussian-basis DFT, accelerating simulations up to 30x for semiconductor workflows.
- TSMC: TSMC uses cuEST’s accelerated quantum chemistry to advance processes for next-generation silicon design.
From the Lab to the Fab
The most common method for atomistic modeling is density functional theory. DFT offers a strong balance between accuracy and scalability; however, its computational cost has limited its widespread use in industry, keeping most applications confined to research. With cuEST, NVIDIA makes high‑accuracy quantum‑chemistry feasible at an industrial scale and in real production workflows.
Historically, the industry has relied on CPU clusters to run these simulations, evaluating candidate materials, including gate dielectrics and interconnect metals, one batch at a time over hours or days.
cuEST provides optimized routines so GPUs can accelerate the core matrices of a Gaussian-basis DFT calculation, including overlap, kinetic energy, nuclear attraction, Coulomb and exchange-correlation. It also supports functional approximations ranging from standard generalized gradient approximation to hybrid functionals, allowing engineers to balance computational cost with accuracy.
NVIDIA’s goal for cuEST: moving high-fidelity material modeling from the lab to the fab.
Learn more about cuEST by joining the NVIDIA demo booth and Synopsys’ booth at GTC, and dive deeper in the GTC session, “Next-Generation Discovery: Agentic AI for Science, AI-Driven Simulation and GPU-Accelerated Chemistry.”
Retail 🔗
Tuesday, March 17, 11:00 a.m. PT 🔗
Molecular Makeover: L’Oréal Uses NVIDIA ALCHEMI to Accelerate Beauty Discovery by 100x
The future of beauty is being written with a mixture of historical scientific expertise, creativity, and code. L’Oréal and NVIDIA are expanding their collaboration to bring NVIDIA ALCHEMI — AI Lab for Chemistry and Materials Innovation — to the multibillion-dollar world of skincare.
Traditionally, creating new sunscreens has relied on meticulous, multiyear laboratory formulation, constrained by the sheer volume of possible combinations that require physical testing. Now, L’Oréal is streamlining the process.
By using ALCHEMI on NVIDIA accelerated computing, L’Oréal is speeding up and improving the accuracy of formulation property prediction performed through computer simulation.
The company’s researchers can now screen molecular combinations for sun protection 100x faster and more efficiently than with traditional simulation methods. Results show that AI decreases discovery timelines and reduces costs, accelerating research, formula screening, and product development across the chemicals and materials science industry.
Formulation is the bedrock of research at L’Oréal, which manages more than 3,400 new formulas each year across skin and haircare, makeup and fragrances, and invests more than 1.3 billion euros annually in R&D. By deploying NVIDIA ALCHEMI, L’Oréal’s scientists can explore a massive chemical space that was previously too computationally complex to navigate.
The benefits extend beyond beauty, as optimizing formulations will help L’Oreal potentialize its active ingredients for skin protection and premature aging prevention.
Beyond the complex chemistry of a bottle of sunscreen or a novel scent, NVIDIA ALCHEMI can be used to optimize formulation for items ranging from semiconductor materials to paints and coatings.
Learn more from L’Oréal’s GTC session.
Tuesday, March 17, 11:00 a.m. PT 🔗
NVIDIA Unveils Retail Agentic Commerce Blueprint in Collaboration With OpenAI
The future of online shopping lies in agentic commerce, with AI agents helping customers with product discovery, checkout, payment and post-purchase experiences.
At GTC, NVIDIA introduced the NVIDIA Blueprint for retail agentic commerce — an open source, production-ready reference architecture that enables retailers to participate in the emerging agentic commerce ecosystem by supporting agent-to-agent communication across merchants and leading generative AI platforms.
This means shoppers using ChatGPT or Gemini can complete a full purchase — with payment security, real-time promotions and personalized recommendations — all under the merchant’s control.
One Codebase, Two Major Standards
The blueprint is a complete implementation of OpenAI’s Agentic Commerce Protocol (ACP) and supports Google’s Universal Commerce Protocol (UCP), allowing it to serve both major agentic commerce standards from a single deployment. By accessing the blueprint on build.nvidia.com, retailers and partners can deploy the entire stack with a single command and start building on it immediately.
OpenAI’s ACP and Apps software development kit lets merchants embed shopping experiences directly inside ChatGPT. The company has been an active partner in the new NVIDIA blueprint’s development, providing technical guidance to ensure the implementation faithfully represents how ACP is designed to work for real-world deployments.
What’s Inside the Blueprint
Built on the NVIDIA NeMo Agent Toolkit and powered by NVIDIA Nemotron open models, the blueprint includes four agents for:
- Promotion pricing — providing dynamic, real-time offer generation.
- Agentic retrieval-augmented-generation-powered recommendations — offering contextual product suggestions grounded in available merchant inventory.
- Semantic search — powering intent-aware product discovery.
- Multilingual post-purchase messaging — enabling automated, localized customer follow-up.
A delegated payment system ties it all together, ensuring transactions remain secure and merchant-controlled from end to end.
Built on Trust
Agentic commerce is built on trust and interoperability. Every participant in a transaction, whether the merchant, payment processor or agent developer, must trust the underlying protocol layer.
By building the blueprint together, NVIDIA and OpenAI are establishing an agentic commerce foundation retailers can confidently build on. And by implementing Google’s UCP, the blueprint extends that foundation to support multiple agent ecosystems from the same platform.
Visit NVIDIA Blueprints to learn more and explore the blueprint on GitHub. See the blueprint in action at GTC by visiting NVIDIA partner booths — Cisco 1421 (presented by AIBLE), Arrow 3101 and Infosys 239.
Media and Entertainment 🔗
Tuesday, March 17, 3:00 p.m. PT 🔗
NVIDIA Unveils AI Technologies for Media Workflows
At GTC, NVIDIA announced powerful new technologies to transform live media and post-production workflows.
These include new content localization capabilities for NVIDIA Holoscan for Media, the NVIDIA Content-Localization Blueprint and NVIDIA AI for Media, a collection of software development kits and NVIDIA NIM microservices for audio, video and augmented-reality features — all providing media professionals with the tools they need to create, edit and distribute content with greater speed and flexibility.
Localizing Content at Global Scale
Holoscan for Media, a platform for real-time AI media pipelines, now supports scalable content-localization capabilities.
Delivered as a collection of NVIDIA AI for Media technologies and partner AI technologies, these capabilities translate video, audio and graphics into other languages on NVIDIA accelerated compute infrastructure, allowing live media, news and sports companies to transition from expensive, manual, multiproduction business models to software-driven localization at scale.
NVIDIA partners AI Media, Camb.AI, Chyron, Onemeta-Verbum and Panjaya have joined a growing Holoscan for Media ecosystem that supports AI captioning, graphics translation, dubbing and localized voice — adapting audio content to a specific market, region, cohort or culture to ensure it sounds natural, authentic and engaging to local users.
Combined with video super resolution and lipsync technologies, this update supports the industry in delivering high-quality, localized content to global audiences at scale.
In addition, the new NVIDIA Content-Localization Blueprint introduces methods for adapting audio, video and graphics to more languages and regions.
Driving Studio-Quality Production With AI
NVIDIA AI for Media delivers a comprehensive suite of state-of-the-art AI technologies for audio and video processing, offered through SDKs, NVIDIA NIM microservices and production-ready reference blueprints. These capabilities are engineered for seamless integration into any media application, from live video pipelines to high-performance post-production workflows. NVIDIA AI for Media provides the foundational building blocks needed to accelerate the next generation of AI-enhanced media experiences at scale.
At GTC, AI for Media introduced new performance-optimized features, including NVIDIA Studio Voice, Active Speaker Detection and Video Super Resolution — now available for download in the AI for Media SDKs.
Accelerating AI in Sports
At GTC, Lenovo and NVIDIA announced a multiyear collaboration to accelerate the adoption of enterprise-grade AI across the global sports industry.
The collaboration will deliver AI-powered solutions across sports intelligence, sports operations, and sports media and content to enhance fan engagement and drive performance, revenue and operational gains.
By combining Lenovo’s end-to-end AI expertise, Hybrid AI Advantage solution and xIQ orchestration layer with the full-stack NVIDIA AI platform — spanning accelerated infrastructure, enterprise-grade software and AI models — the companies are delivering cutting-edge technologies for sports environments while engaging a broad ecosystem of industry partners.
Learn more about NVIDIA technologies for real-time media workflows at GTC.
See notice regarding software product information.
Financial Services 🔗
Tuesday, March 17, 10:00 a.m. PT 🔗
Jump Trading to Become One of the First Trading Firms to Adopt NVIDIA Rubin Platform
Jump Trading will be among the first trading firms in financial services to adopt the NVIDIA Rubin platform, accelerating AI-powered capital markets research and financial modeling.
A key success factor for Jump is “research velocity” — the ability to explore diverse deep learning approaches, rapidly adapt models to shifting market conditions and scale trading across global markets. Financial markets generate some of the world’s most dynamic and complex datasets, with the largest U.S. stocks averaging over 10 million exchange messages per day and peak rates exceeding 200,000 messages per second.
To meet these extraordinary demands, NVIDIA Vera Rubin NVL72 delivers supercomputer-class compute density, expanded memory bandwidth and significantly increased power efficiency to enhance performance while reducing token costs.
Driving liquidity and price discovery requires relentless research and the ability to scale new ideas instantly. Equipped with NVIDIA accelerated computing, Jump can achieve massive research velocity, rapidly iterating on complex model architectures to adapt to shifting market conditions with AI.
Learn more about how Jump is using NVIDIA accelerated computing to power the next wave of capital markets research and algorithmic trading by visiting booth 189 in the FSI Pavilion at GTC.
Tuesday, March 17, 12:00 p.m. PT 🔗
Hudson River Trading Accelerates Algorithmic Trading With NVIDIA AI Factory
Hudson River Trading (HRT), a global leader in quantitative trading, is achieving significant performance gains in investment research and algorithmic trading using an AI factory powered by the NVIDIA Blackwell architecture and NVIDIA Spectrum-X Ethernet networking.
The AI factory connects HRT researchers directly to immense compute power, streamlining workflows across data ingestion, model training, simulation and deployment. With this custom solution, HRT AI Labs engineers are developing models that understand complex market microstructure and deliver faster, smarter insights that significantly boost decision confidence. This has resulted in a 1.6x improvement in HRT’s research iteration time on Blackwell compared with the NVIDIA Hopper architecture, allowing HRT to:
- Maximize returns via high-accuracy price prediction and discovery
- Safely backtest strategies using synthetic market data to reduce research costs and preparation time
- Evaluate novel strategies using electronic market digital twins to simulate global markets at microsecond fidelity
To support this effort efficiently, the firm is deploying compute-intensive model training within its AI factory at Lefdal Mine Data Centers, using the facility as one of its research and training hubs.
Located next to a fjord, the Lefdal Mine site runs entirely on renewable hydropower and wind energy, drawing in cold seawater and transferring it using a siphon effect for cooling to maintain a power cooling PUE of 1.15 or lower. Built deep inside the mountain, the facility provides a high level of physical security, and its cooling system is designed to be future-proof, capable of supporting any rack density.
Learn how AI factories are transforming financial services by watching this video and take a look inside the Lefdal AI factory:
Learn more from the GTC session led by HRT, called “The Blueprint for a Modern Resource-Responsible AI Factory.”
Tuesday, March 17, 2:00 p.m. PT 🔗
From Siloed Data to Connected Intelligence: Financial Leaders Embrace NVIDIA-Powered Transaction Foundation Models
Global financial services leaders — including Mastercard, Revolut and Adyen — are embracing NVIDIA-powered transaction foundation models to decode the complex “language” of user behavior, optimizing global commerce and helping outsmart financial crime.
Mastercard is using the NVIDIA NeMo AutoModel and NVIDIA accelerated computing together with the Databricks platform to develop its proprietary transaction foundation model, one of the first payments-specific models to understand the nuances of global commerce. The model is trained on hundreds of millions of transactions and is already showing promising signs of outperforming advanced machine learning techniques.
Revolut built a transaction foundation model using masked prediction to enforce self-learning and enable next-item forecasting. The company is using NVIDIA’s full AI stack — from NVIDIA Hopper GPUs and the NVIDIA cuDF library to the NVIDIA Nemotron family of open models — to improve performance, driving a 20% increase in fraud detection precision, better credit risk predictions and a 9.6% uptick in cross-sell accuracy.
Adyen has deployed transaction foundation models at scale — processing $1 trillion in payments — to transition from isolated models to a unified system. Using reinforcement learning, Adyen optimizes the entire payments-acquiring lifecycle simultaneously. Tapping into NVIDIA’s accelerated computing platform enables a 195x speedup for foundation model inferencing, allowing Adyen to meet strict latency requirements while maximizing conversion and minimizing risk and costs for merchants.
Learn more about Mastercard and Databricks, and attend GTC sessions led by Revolut and Adyen.
Tags:
GTC 2026
Related News