An AI factory is computing infrastructure designed to create value from data by managing the entire AI lifecycle, from data ingestion to AI model training, post-training and fine-tuning and high-volume AI inference. The primary product is intelligence, how efficiently the AI factory can produce the lowest cost per token, which drives decisions, automation and new AI solutions.
AI is creating value for everyone — from researchers in drug discovery to quantitative analysts navigating financial market changes.
The faster an AI system can produce tokens, a unit of data used to string together outputs, the greater its impact. That’s why AI factories are key, providing the most efficient path from “time to first token” to “time to first value.”
AI factories are redefining the economics of modern infrastructure. They produce intelligence by transforming data into valuable outputs — whether tokens, predictions, images, proteins or other forms — at massive scale.
They help enhance three key aspects of the AI journey — data ingestion, model training and high-volume inference. AI factories are being built to generate tokens faster and more accurately, using three critical technology stacks: AI models, accelerated computing infrastructure and enterprise-grade software.
Read on to learn how AI factories are helping enterprises and organizations around the world convert the most valuable digital commodity — data — into revenue potential.
How Does Inference Drive Revenue in an AI Factory?
Before building an AI factory, it’s important to understand the economics of inference — how to balance costs, energy efficiency and an increasing demand for AI.
Throughput refers to the volume of tokens that a model can produce. Latency is the amount of tokens that the model can output in a specific amount of time, which is often measured in time to first token — how long it takes before the first output appears — and time per output token, or how fast each additional token comes out. Goodput is a newer metric, measuring how much useful output a system can deliver while hitting key latency targets.
User experience is key for any software application, and the same goes for AI factories. High throughput means smarter AI, and lower latency ensures timely responses. When both of these measures are balanced properly, AI factories can provide engaging user experiences by quickly delivering helpful outputs.
For example, an AI-powered customer service agent that responds in half a second is far more engaging and valuable than one that responds in five seconds, even if both ultimately generate the same number of tokens in the answer.
Companies can take the opportunity to place competitive prices on their inference output, resulting in more revenue potential per token.
Measuring and visualizing this balance can be difficult — which is where the concept of a Pareto frontier comes in.
How Does Token Efficiency Impact AI Factory Profitability?
The Pareto frontier, represented in the figure below, helps visualize the most optimal ways to balance trade-offs between competing goals — like faster responses vs. serving more users simultaneously — when deploying AI at scale.
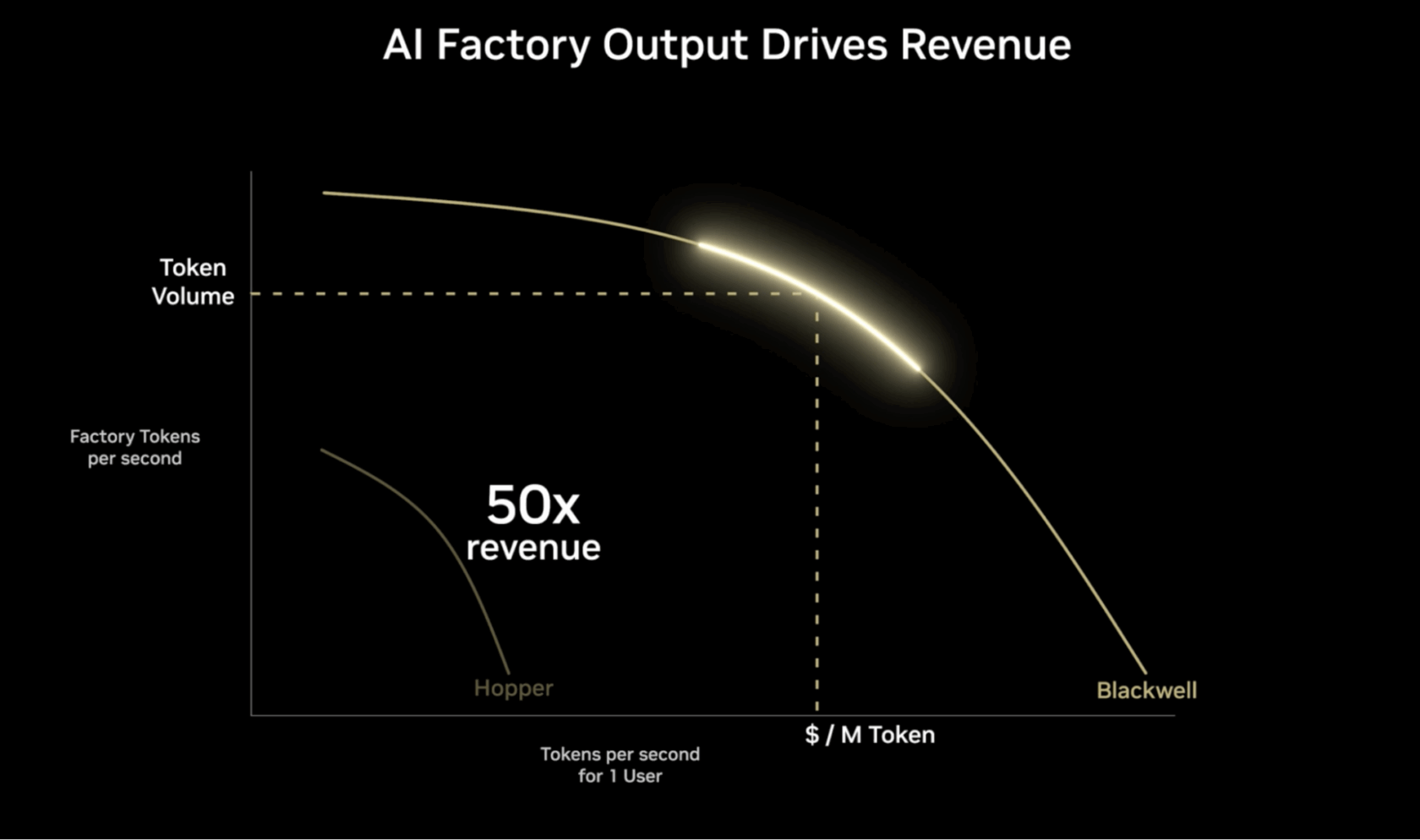
The vertical axis represents throughput efficiency, measured in tokens per second (TPS), for a given amount of energy used. The higher this number, the more requests an AI factory can handle concurrently.
The horizontal axis represents the TPS for a single user, representing how long it takes for a model to give a user the first answer to a prompt. The higher the value, the better the expected user experience. Lower latency and faster response times are generally desirable for interactive applications like chatbots and real-time analysis tools.
The Pareto frontier’s maximum value — shown as the top value of the curve — represents the best output for given sets of operating configurations. The goal is to find the optimal balance between throughput and user experience for different AI workloads and applications.
The best AI factories use accelerated computing to increase tokens per watt — optimizing AI performance while dramatically increasing energy efficiency across AI factories and applications.
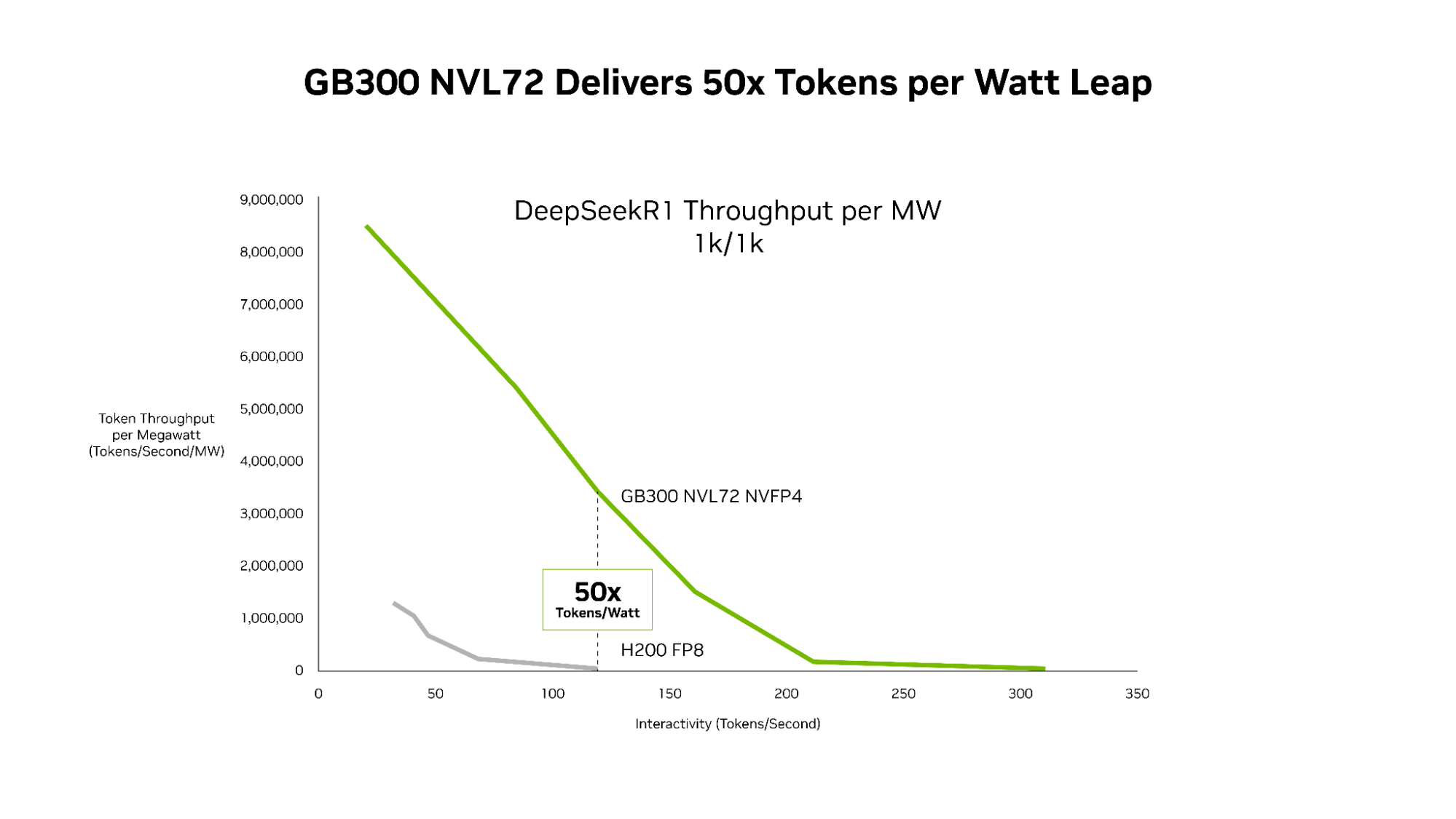
GB300 NVL72 — which features the Blackwell Ultra GPU — pushes the throughput-per-megawatt frontier to 50x compared with the Hopper platform. And NVIDIA GB300 NVL72 and the codesigned software stack, including NVIDIA Dynamo and TensorRT-LLM, deliver 35x lower cost per token compared with the NVIDIA Hopper platform.
What Does an AI Factory Look Like in Real-World Deployment?
An AI factory is a system of components that come together to turn data into intelligence. It doesn’t necessarily take the form of a high-end, on-premises data center, but could be an AI-dedicated cloud or hybrid model running on accelerated compute infrastructure. Or it could be a telecom infrastructure that can both optimize the network and perform inference at the edge.
Any dedicated accelerated computing infrastructure paired with software turning data into intelligence through AI is, in practice, an AI factory.
The components include accelerated computing, networking, software, storage, systems, and tools and services.
When a person prompts an AI system, the full stack of the AI factory goes to work. The factory tokenizes the prompt, turning data into small units of meaning — like fragments of images, sounds and words.
Each token is put through a GPU-powered AI model, which performs compute-intensive reasoning on the AI model to generate the best response. Each GPU performs parallel processing — enabled by high-speed networking and interconnects — to crunch data simultaneously.
An AI factory will run this process for different prompts from users across the globe. This is real-time inference, producing intelligence at industrial scale.
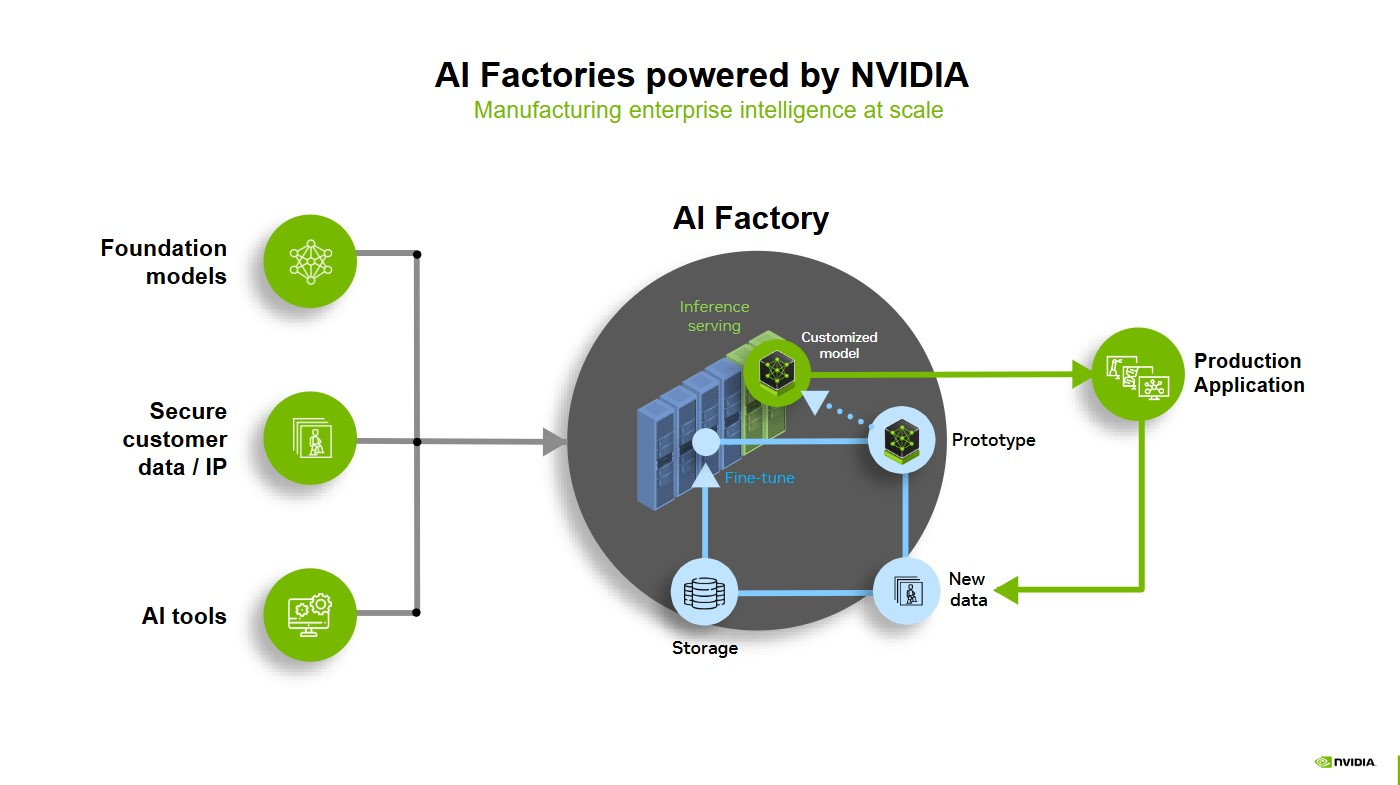
Because AI factories unify the full AI lifecycle, this system is continuously improving: inference is logged, edge cases are flagged for retraining and optimization loops tighten over time — all without manual intervention, an example of goodput in action.
Leading global security technology company Lockheed Martin has built its own AI factory to support diverse uses across its business. Through its Lockheed Martin AI Center, the company centralized its generative AI workloads on the NVIDIA DGX SuperPOD to train and customize AI models, use the full power of specialized infrastructure and reduce the overhead costs of cloud environments.
“With our on-premises AI factory, we handle tokenization, training and deployment in house,” said Greg Forrest, director of AI foundations at Lockheed Martin. “Our DGX SuperPOD helps us process over 1 billion tokens per week, enabling fine-tuning, retrieval-augmented generation or inference on our large language models. This solution avoids the escalating costs and significant limitations of fees based on token usage.”
Which NVIDIA Technologies Optimize AI Factory Performance?
An AI factory transforms AI from a series of isolated experiments into a scalable, repeatable and reliable engine for innovation and business value.
NVIDIA provides all the components needed to build AI factories, including accelerated computing, high-performance GPUs, high-bandwidth networking and optimized software.
NVIDIA Blackwell GPUs, for example, can be connected via networking, liquid-cooled for energy efficiency and orchestrated with AI software.
The NVIDIA Dynamo open-source inference platform offers an operating system for AI factories. It’s built to accelerate and scale AI with maximum efficiency and minimum cost. By intelligently routing, scheduling and optimizing inference requests, Dynamo ensures that every GPU cycle ensures full utilization, driving token production with peak performance.
NVIDIA Blackwell GB200 NVL72 systems and NVIDIA InfiniBand networking are tailored to maximize token throughput per watt, making the AI factory highly efficient from both total throughput and low latency perspectives.
By validating optimized, full-stack solutions, organizations can build and maintain cutting-edge AI systems efficiently. A full-stack AI factory supports enterprises in achieving operational excellence, enabling them to harness AI’s potential faster and with greater confidence.
Learn more about how to calculate the lowest cost per token and why it’s the AI business metric that matters most.