
It can take a puppy weeks to learn that certain kinds of behaviors will result in a yummy treat, extra cuddles or a belly rub — and that other behaviors won’t. With a system of positive reinforcement, a pet pooch will in time anticipate that chasing squirrels is less likely to be rewarded than staying by their human’s side.
Deep reinforcement learning, a technique used to train AI models for robotics and complex strategy problems, works off the same principle.
In reinforcement learning, a software agent interacts with a real or virtual environment, relying on feedback from rewards to learn the best way to achieve its goal. Like the brain of a puppy in training, a reinforcement learning model uses information it’s observed about the environment and its rewards, and determines which action the agent should take next.
To date, most researchers have relied on a combination of CPUs and GPUs to run reinforcement learning models. This means different parts of the computer tackle different steps of the process — including simulating the environment, calculating rewards, choosing what action to take next, actually taking action, and then learning from the experience.
But switching back and forth between CPU cores and powerful GPUs is by nature inefficient, requiring data to be transferred from one part of the system’s memory to another at multiple points during the reinforcement learning training process. It’s like a student who has to carry a tall stack of books and notes from classroom to classroom, plus the library, before grasping a new concept.
With Isaac Gym, NVIDIA developers have made it possible to instead run the entire reinforcement learning pipeline on GPUs — enabling significant speedups and reducing the hardware resources needed to develop these models.
Here’s what this breakthrough means for the deep reinforcement learning process, and how much acceleration it can bring developers.
Reinforcement Learning on GPUs: Simulation to Action
When training a reinforcement learning model for a robotics task — like a humanoid robot that walks up and down stairs — it’s much faster, safer and easier to use a simulated environment than the physical world. In a simulation, developers can create a sea of virtual robots that can quickly rack up thousands of hours of experience at a task.
If tested solely in the real world, a robot in training could fall down, bump into or mishandle objects — causing potential damage to its own machinery, the object it’s interacting with or its surroundings. Testing in simulation provides the reinforcement learning model a space to practice and work out the kinks, giving it a head start when shifting to the real world.
In a typical system today, the NVIDIA PhysX simulation engine runs this experience-gathering phase of the reinforcement learning process on NVIDIA GPUs. But for other steps of the training application, developers have traditionally still used CPUs.
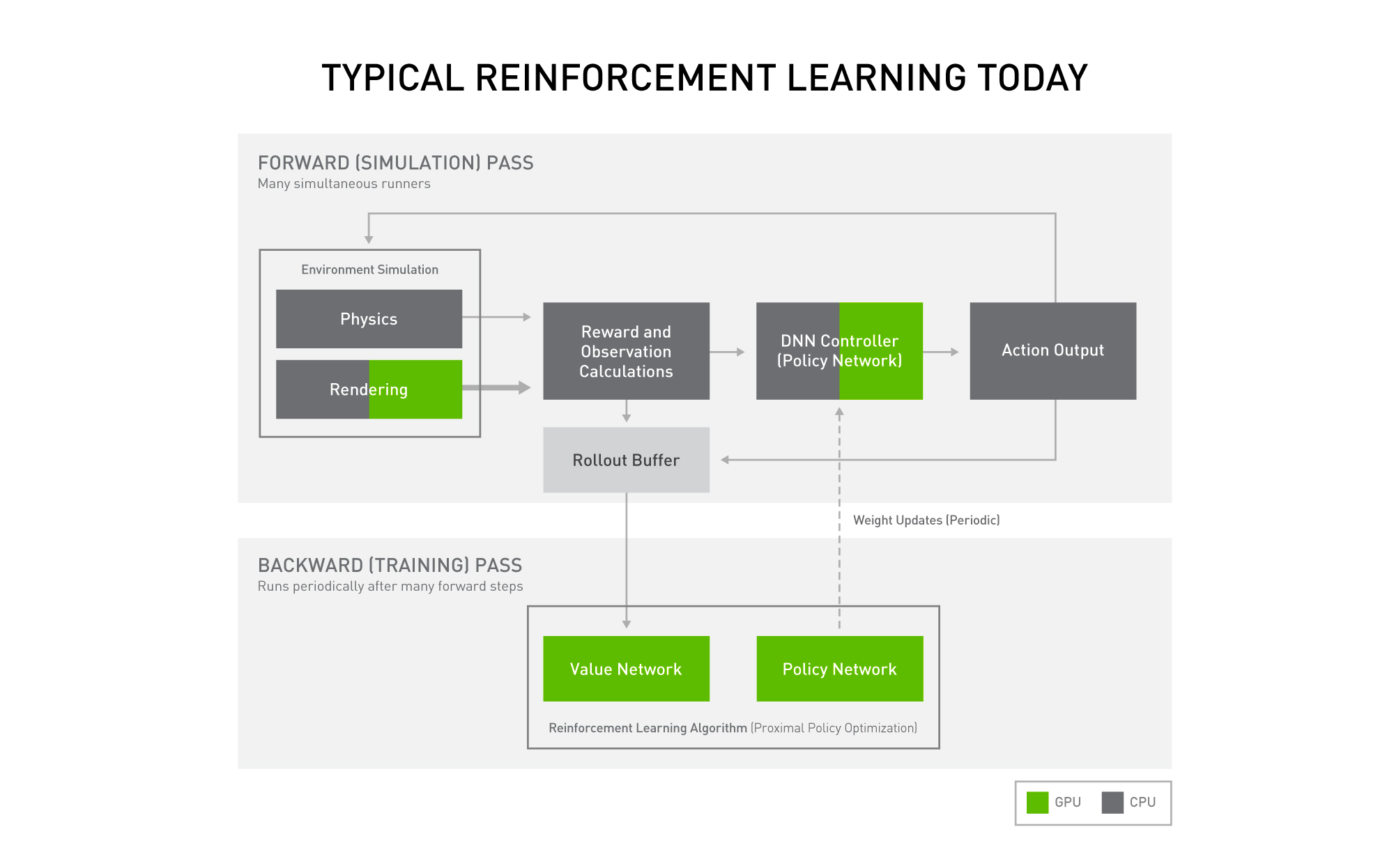
A key part of reinforcement learning training is conducting what’s known as the forward pass: First, the system simulates the environment, records a set of observations about the state of the world and calculates a reward for how well the agent did.
The recorded observations become the input to a deep learning “policy” network, which chooses an action for the agent to take. Both the observations and the rewards are stored for use later in the training cycle.
Finally, the action is sent back to the simulator so that the rest of the environment can be updated in response.
After several rounds of these forward passes, the reinforcement learning model takes a look back, evaluating whether the actions it chose were effective or not. This information is used to update the policy network, and the cycle begins again with the improved model.
GPU Acceleration with Isaac Gym
To eliminate the overhead of transferring data back and forth from CPU to GPU during this reinforcement learning training cycle, NVIDIA researchers have developed an approach to run every step of the process on GPUs. This is Isaac Gym, an end-to-end training environment, which includes the PhysX simulation engine and a PyTorch tensor-based API.
Isaac Gym makes it possible for a developer to run tens of thousands of environments simultaneously on a single GPU. That means experiments that previously required a data center with thousands of CPU cores can in some cases be trained on a single workstation.

Decreasing the amount of hardware required makes reinforcement learning more accessible to individual researchers who don’t have access to large data center resources. It can also make the process a lot faster.
A simple reinforcement learning model tasked with getting a humanoid robot to walk can be trained in just a few minutes with Isaac Gym. But the impact of end-to-end GPU acceleration is most useful for more challenging tasks, like teaching a complex robot hand to manipulate a cube into a specific position.
This problem requires significant dexterity by the robot, and a simulation environment that involves domain randomization, a mechanism that allows the learned policy to more easily transfer to a real-world robot.
Research by OpenAI tackled this task with a cluster of more than 6,000 CPU cores plus multiple NVIDIA Tensor Core GPUs — and required about 30 hours of training for the reinforcement learning model to succeed at the task 20 times in a row using a feed-forward network model.
Using just one NVIDIA A100 GPU with Isaac Gym, NVIDIA developers were able to achieve the same level of success in around 10 hours — a single GPU outperforming an entire cluster by a factor of 3x.
To learn more about Isaac Gym, visit our developer news center.
Video above shows a cube manipulation task trained by Isaac Gym on a single NVIDIA A100 GPU and rendered in NVIDIA Omniverse.


