NVIDIA today announced at Microsoft Build new AI performance optimizations and integrations for Windows that help deliver maximum performance on NVIDIA GeForce RTX AI PCs and NVIDIA RTX workstations.
Large language models (LLMs) power some of the most exciting new use cases in generative AI and now run up to 3x faster with ONNX Runtime (ORT) and DirectML using the new NVIDIA R555 Game Ready Driver. ORT and DirectML are high-performance tools used to run AI models locally on Windows PCs.
WebNN, an application programming interface for web developers to deploy AI models, is now accelerated with RTX via DirectML, enabling web apps to incorporate fast, AI-powered capabilities. And PyTorch will support DirectML execution backends, enabling Windows developers to train and infer complex AI models on Windows natively. NVIDIA and Microsoft are collaborating to scale performance on RTX GPUs.
These advancements build on NVIDIA’s world-leading AI platform, which accelerates more than 500 applications and games on over 100 million RTX AI PCs and workstations worldwide.
RTX AI PCs — Enhanced AI for Gamers, Creators and Developers
NVIDIA introduced the first PC GPUs with dedicated AI acceleration, the GeForce RTX 20 Series with Tensor Cores, along with the first widely adopted AI model to run on Windows, NVIDIA DLSS, in 2018. Its latest GPUs offer up to 1,300 trillion operations per second of dedicated AI performance.
In the coming months, Copilot+ PCs equipped with new power-efficient systems-on-a-chip and RTX GPUs will be released, giving gamers, creators, enthusiasts and developers increased performance to tackle demanding local AI workloads, along with Microsoft’s new Copilot+ features.
For gamers on RTX AI PCs, NVIDIA DLSS boosts frame rates by up to 4x, while NVIDIA ACE brings game characters to life with AI-driven dialogue, animation and speech.
For content creators, RTX powers AI-assisted production workflows in apps like Adobe Premiere, Blackmagic Design DaVinci Resolve and Blender to automate tedious tasks and streamline workflows. From 3D denoising and accelerated rendering to text-to-image and video generation, these tools empower artists to bring their visions to life.
For game modders, NVIDIA RTX Remix, built on the NVIDIA Omniverse platform, provides AI-accelerated tools to create RTX remasters of classic PC games. It makes it easier than ever to capture game assets, enhance materials with generative AI tools and incorporate full ray tracing.
For livestreamers, the NVIDIA Broadcast application delivers high-quality AI-powered background subtraction and noise removal, while NVIDIA RTX Video provides AI-powered upscaling and auto-high-dynamic range to enhance streamed video quality.
Enhancing productivity, LLMs powered by RTX GPUs execute AI assistants and copilots faster, and can process multiple requests simultaneously.
And RTX AI PCs allow developers to build and fine-tune AI models directly on their devices using NVIDIA’s AI developer tools, which include NVIDIA AI Workbench, NVIDIA cuDNN and CUDA on Windows Subsystem for Linux. Developers also have access to RTX-accelerated AI frameworks and software development kits like NVIDIA TensorRT, NVIDIA Maxine and RTX Video.
The combination of AI capabilities and performance deliver enhanced experiences for gamers, creators and developers.
Faster LLMs and New Capabilities for Web Developers
Microsoft recently released the generative AI extension for ORT, a cross-platform library for AI inference. The extension adds support for optimization techniques like quantization for LLMs like Phi-3, Llama 3, Gemma and Mistral. ORT supports different execution providers for inferencing via various software and hardware stacks, including DirectML.
ORT with the DirectML backend offers Windows AI developers a quick path to develop AI capabilities, with stability and production-grade support for the broad Windows PC ecosystem. NVIDIA optimizations for the generative AI extension for ORT, available now in R555 Game Ready, Studio and NVIDIA RTX Enterprise Drivers, help developers get up to 3x faster performance on RTX compared to previous drivers.
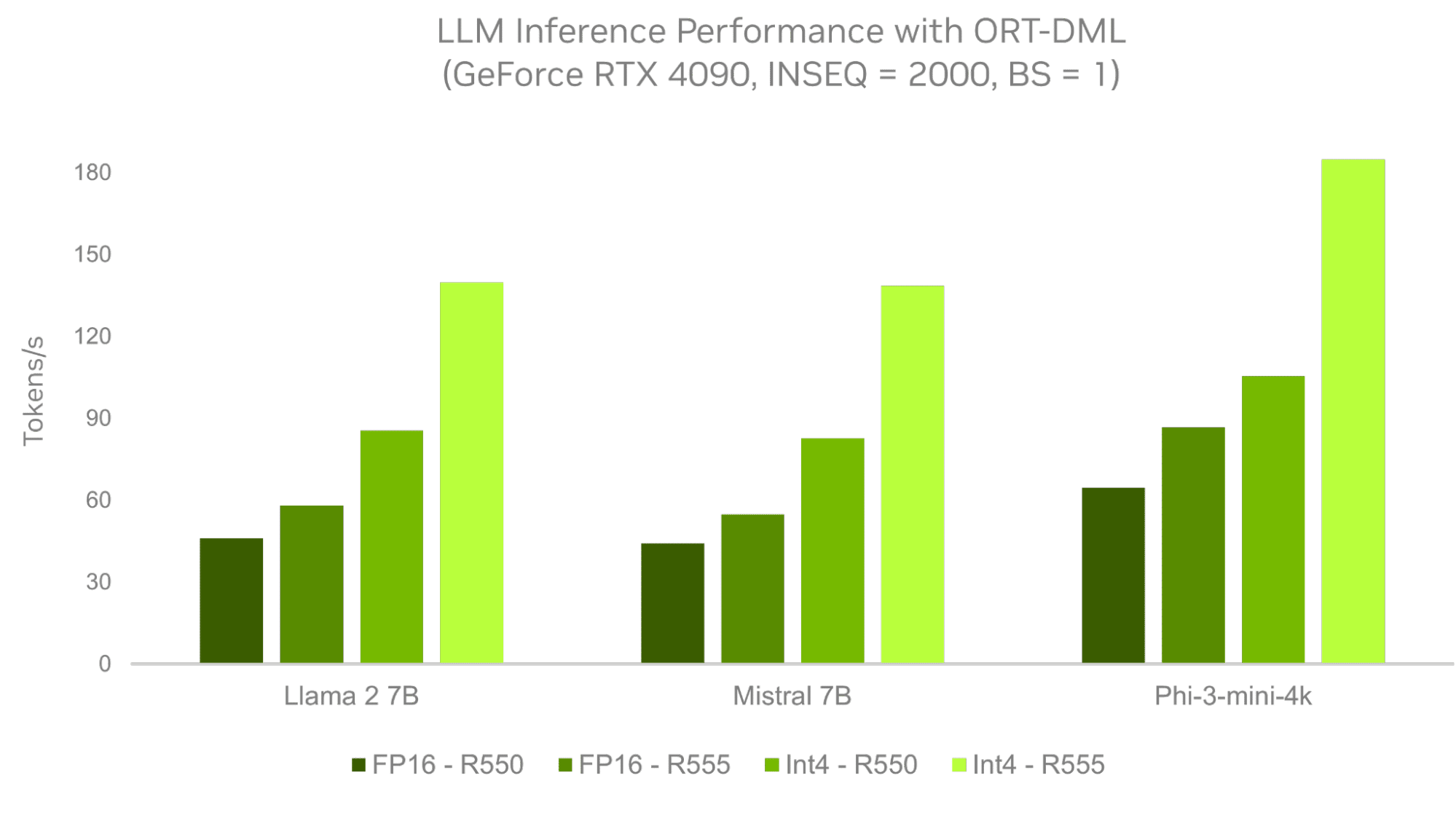
Developers can unlock the full capabilities of RTX hardware with the new R555 driver, bringing better AI experiences to consumers, faster. It includes:
- Support for DQ-GEMM metacommand to handle INT4 weight-only quantization for LLMs
- New RMSNorm normalization methods for Llama 2, Llama 3, Mistral and Phi-3 models
- Group and multi-query attention mechanisms, and sliding window attention to support Mistral
- In-place KV updates to improve attention performance
- Support for GEMM of non-multiple-of-8 tensors to improve context phase performance
Additionally, NVIDIA has optimized AI workflows within WebNN to deliver the powerful performance of RTX GPUs directly within browsers. The WebNN standard helps web app developers accelerate deep learning models with on-device AI accelerators, like Tensor Cores.
Now available in developer preview, WebNN uses DirectML and ORT Web, a Javascript library for in-browser model execution, to make AI applications more accessible across multiple platforms. With this acceleration, popular models like Stable Diffusion, SD Turbo and Whisper run up to 4x faster on WebNN compared to WebGPU and are now available for developers to use. Microsoft Build attendees can learn more about developing on RTX in the Accelerating development on Windows PCs with RTX AI in-person session on Wednesday, May 22, at 11 a.m. PT.