
The real world is always in motion. To operate autonomously, physical AI systems — including robots, autonomous vehicles (AVs) and smart spaces — need to understand not just what they see and what caused that to happen, but what’s likely to happen next.
In a warehouse, a robot may encounter object configurations it’s never seen before. On the road, an AV may need to respond when a pedestrian steps out from between parked cars. And in a factory, a safety system must predict where a forklift is heading, not just detect that it’s there.
Capturing and recreating those scenarios in the real world is slow, expensive and often impossible to repeat at scale.
NVIDIA Cosmos 3 is built for that loop. The new world foundation model — announced today at NVIDIA GTC Taipei at COMPUTEX — combines vision reasoning and multimodal generation across text, video, images, ambient sound and action in a single model to help developers create world data with physical context.

Cosmos 3 powers perception, prediction and action.
Learn more about how Cosmos 3’s mixture-of-transformers architecture enables a reasoning block to first interpret what is happening in a scene, then harnesses a generation block to use that context to create physically grounded outputs, from synthetic video to robot-task data.
Generating Action Data for Real-World Robot Tasks
Cosmos 3 is a generalist foundation model trained on diverse data that gives it a broad understanding of how scenes, motion and robotic actions relate. It’s an omnimodel with native action generation, meaning it can produce numerical action data, such as joint angles, gripper positions and trajectory points, that describe how a robot should move to complete a task.
In order to learn, robots need more than images or videos of a scene. For pick-and-place tasks, for example, they need action signals that guide how to reach, grasp, move and place objects in their environment. Developers can fine-tune Cosmos 3 to specialize their robots for a particular embodiment, camera layout, workspace or task.
The NVIDIA GEAR team is using Cosmos 3 to develop video action models that help embodied agents learn how to reason, move and act across games, simulations and real-world robotics environments.

Audio prompt: Put all the bananas on the plate.
Agile Robots is building humanoids and other embodiments like Thor 3 or FR3 that handle industrial tasks autonomously, precisely and efficiently. It’s using Cosmos 3 to generate action-conditioned robot data for its policy development to create diverse task trajectories at scale.
Prompt: Pick the Core Electric Wire and put it in the bin using both arms.
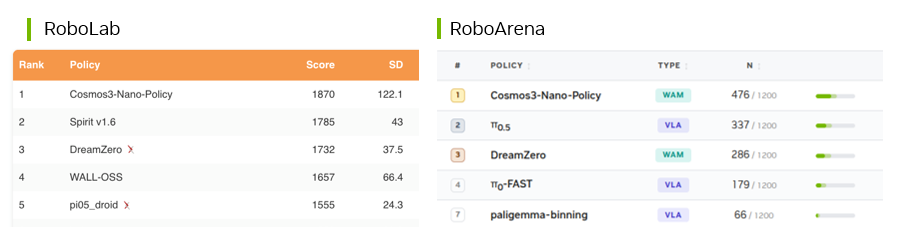
Cosmos 3 Nano post-trained policy leads on RoboLab that tests policies in simulation across language-guided tasks and RoboArena that compares policies on DROID robots in real-world environments.
Reasoning Over Smart Cities and Spaces in Motion
Cosmos 3 can reason across the scene and identify which objects are moving, where paths may intersect and what future state is likely to follow. It can then generate dense captions, predicted scene changes or scenario variations, helping developers connect understanding, prediction and alerts in vision AI agents for industrial and infrastructure environments.
Robot action planning trace using Cosmos 3 for reasoning.
For traffic systems, factories, warehouses and public spaces, this means video systems can help interpret activity over time, surface anomalies and give operators richer context about what’s happening across complex environments.
Linker Vision uses Vision AI to Optimize City Operations, powered by Cosmos.
Linker Vision uses NVIDIA’s physical AI and digital twin technologies to build intelligent smart city and industrial solutions. As part of the workflow, it’s using Cosmos’ vision language reasoning capabilities to analyze live camera streams, understand spatial contexts, extract valuable insights and perform root-cause analysis across thousands of feeds.
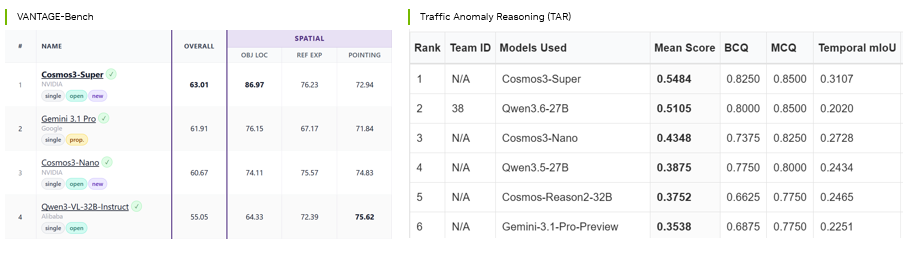
Cosmos 3 is the top-ranked open vision language model on VANTAGE-Bench that tests smart-infrastructure scene understanding and TAR challenge that tests traffic anomaly reasoning.
Generating Rare, Long-Tail Scenarios Over Time
Collisions and long-tail edge cases are among the most important examples to prepare humanoids, arm robots and even surgical robots for the real world, but they’re difficult to capture safely, repeatedly and at scale.
Cosmos 3 can help generate physically plausible video sequences as a video foundation model to teach how the real world changes over time.
Image to Video Prompt: A high-speed racing event where a car navigates multiple winding turns.
For physical AI developers, these generated examples can support synthetic data workflows and future-state prediction alongside real-world driving data — even as conditions evolve frame by frame.
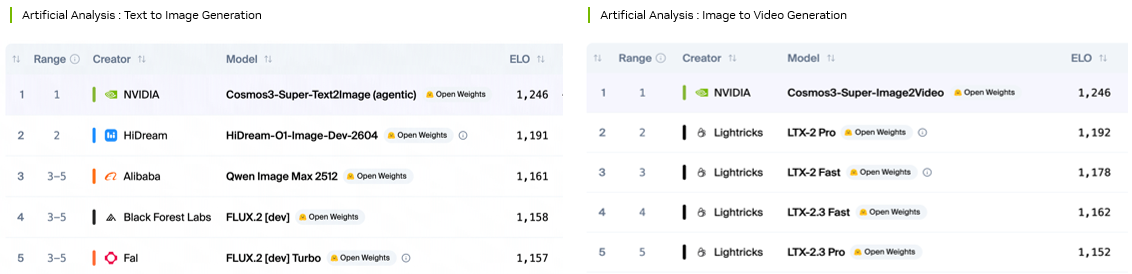
Cosmos 3 variants are ranking first on open weights leaderboards on Artificial Analysis. Cosmos 3 is also topping the Physics-IQ, R-Bench and PAI-Bench leaderboards, among other benchmarks for world generation.
Get Started With Cosmos 3
Developers can try Cosmos 3 on build.nvidia.com, download open models from Hugging Face, customize models and generate synthetic data with resources on GitHub, and deploy with NVIDIA NIM microservices.
With the OpenMDW 1.1 license from Linux Foundation, developers can use Cosmos model materials across physical AI workflows under a single, model-centric license. The license makes it easier to train, modify, contribute, redistribute and deploy resources including weights, architecture, documentation, datasets, benchmarks and code.

Watch the GTC Taipei keynote from NVIDIA founder and CEO Jensen Huang and explore these physical AI sessions.
See notice regarding software product information.
Related News



