Large language models (LLMs), trained on datasets with billions of tokens, can generate high-quality content. They’re the backbone for many of the most popular AI applications, including chatbots, assistants, code generators and much more.
One of today’s most accessible ways to work with LLMs is with AnythingLLM, a desktop app built for enthusiasts who want an all-in-one, privacy-focused AI assistant directly on their PC.
With new support for NVIDIA NIM microservices on NVIDIA GeForce RTX and NVIDIA RTX PRO GPUs, AnythingLLM users can now get even faster performance for more responsive local AI workflows.
What Is AnythingLLM?
AnythingLLM is an all-in-one AI application that lets users run local LLMs, retrieval-augmented generation (RAG) systems and agentic tools.
It acts as a bridge between a user’s preferred LLMs and their data, and enables access to tools (called skills), making it easier and more efficient to use LLMs for specific tasks like:
- Question answering: Getting answers to questions from top LLMs — like Llama and DeepSeek R1 — without incurring costs.
- Personal data queries: Use RAG to query content privately, including PDFs, Word files, codebases and more.
- Document summarization: Generating summaries of lengthy documents, like research papers.
- Data analysis: Extracting data insights by loading files and querying it with LLMs.
- Agentic actions: Dynamically researching content using local or remote resources, running generative tools and actions based on user prompts.
AnythingLLM can connect to a wide variety of open-source local LLMs, as well as larger LLMs in the cloud, including those provided by OpenAI, Microsoft and Anthropic. In addition, the application provides access to skills for extending its agentic AI capabilities via its community hub.
With a one-click install and the ability to launch as a standalone app or browser extension — wrapped in an intuitive experience with no complicated setup required — AnythingLLM is a great option for AI enthusiasts, especially those with GeForce RTX and NVIDIA RTX PRO GPU-equipped systems.
RTX Powers AnythingLLM Acceleration
GeForce RTX and NVIDIA RTX PRO GPUs offer significant performance gains for running LLMs and agents in AnythingLLM — speeding up inference with Tensor Cores designed to accelerate AI.
AnythingLLM runs LLMs with Ollama for on-device execution accelerated through Llama.cpp and ggml tensor libraries for machine learning.
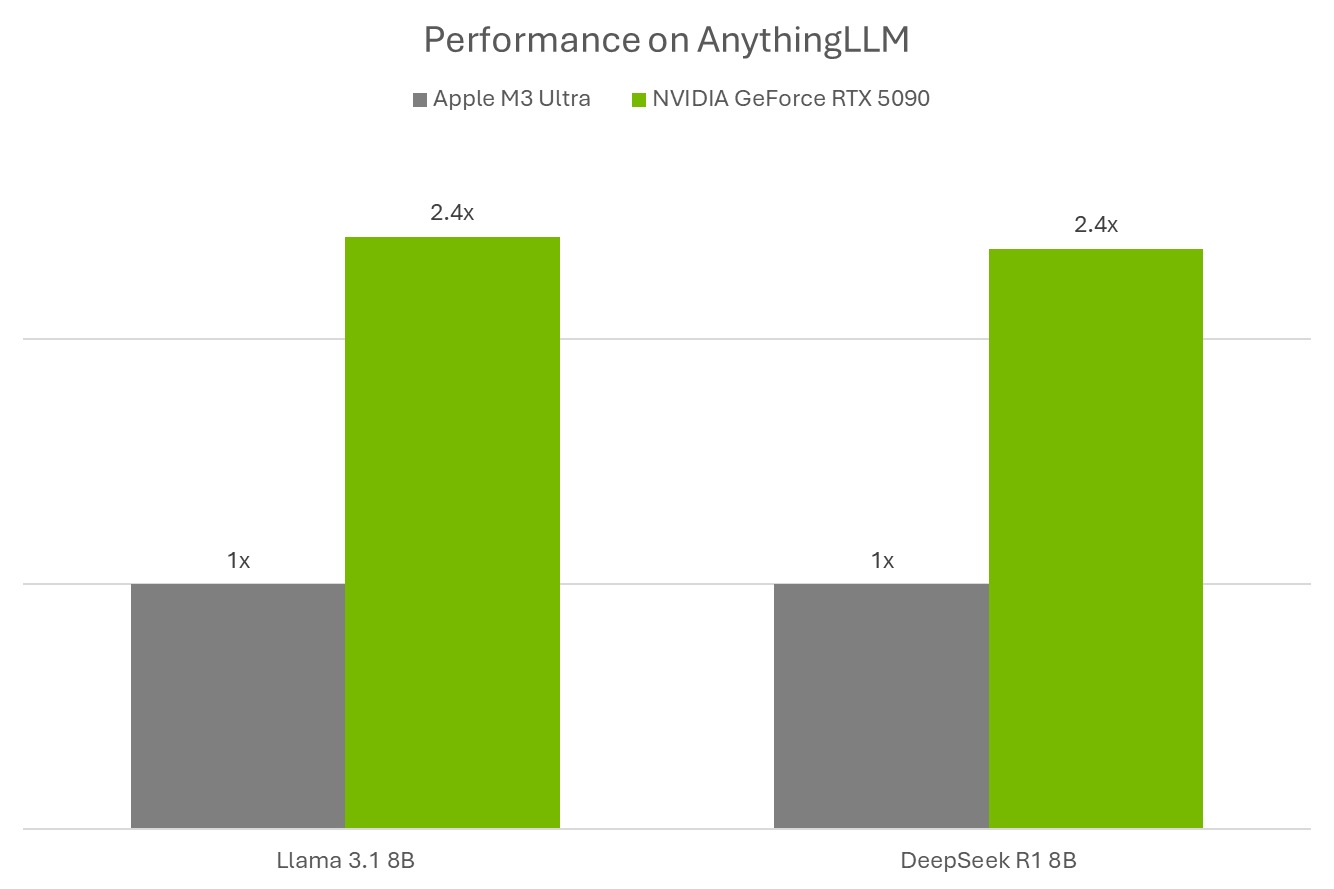
Ollama, Llama.cpp and GGML are optimized for NVIDIA RTX GPUs and the fifth-generation Tensor Cores. Performance on GeForce RTX 5090 is 2.4X compared to an Apple M3 Ultra.
As NVIDIA adds new NIM microservices and reference workflows — like its growing library of AI Blueprints — tools like AnythingLLM will unlock even more multimodal AI use cases.
AnythingLLM — Now With NVIDIA NIM
AnythingLLM recently added support for NVIDIA NIM microservices — performance-optimized, prepackaged generative AI models that make it easy to get started with AI workflows on RTX AI PCs with a streamlined API.
NVIDIA NIMs are great for developers looking for a quick way to test a Generative AI model in a workflow. Instead of having to find the right model, download all the files and figure out how to connect everything, they provide a single container that has everything you need. And they can run both on Cloud and PC, making it easy to prototype locally and then deploy on the cloud.
By offering them within AnythingLLM’s user-friendly UI, users have a quick way to test them and experiment with them. And then they can either connect them to their workflows with AnythingLLM, or leverage NVIDIA AI Blueprints and NIM documentation and sample code to plug them directly to their apps or projects.
Explore the wide variety of NIM microservices available to elevate AI-powered workflows, including language and image generation, computer vision and speech processing.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, digital humans, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.
Follow NVIDIA Workstation on LinkedIn and X. See notice regarding software product information.



