Yann LeCun invited me to speak at this week’s inaugural symposium on “The Future of AI” at NYU. It’s an amazing gathering of leaders in the field to discuss the state of AI and its continued advancement. Here’s what I talked about — how deep learning is a new software model that needs a new computing model; why AI researchers have adopted GPU-accelerated computing; and NVIDIA’s ongoing efforts to advance AI as we enter into its exponential adoption. And why, after all these years, AI has taken off.

The Big Bang
For as long as we have been designing computers, AI has been the final frontier. Building intelligent machines that can perceive the world as we do, understand our language, and learn from examples has been the life’s work of computer scientists for over five decades. Yet, it took the combination of Yann LeCun’s work in convolutional neural nets, Geoff Hinton’s back-propagation and Stochastic Gradient Descent approach to training, and Andrew Ng’s large-scale use of GPUs to accelerate deep neural networks (DNNs) to ignite the big bang of modern AI — deep learning.
At the time, NVIDIA was busy advancing GPU-accelerated computing, a new computing model that uses massively parallel graphics processors to accelerate applications also parallel in nature. Scientists and researchers jumped on to GPUs to do molecular-scale simulations to determine the effectiveness of a life-saving drug, to visualize our organs in 3D (reconstructed from light doses of a CT scan), or to do galactic-scale simulations to discover the laws that govern our universe. One researcher, using our GPUs for quantum chromodynamics simulations, said to me: “Because of NVIDIA’s work, I can now do my life’s work, in my lifetime.” This is wonderfully rewarding. It has always been our mission to give people the power to make a better future. NVIDIA GPUs have democratized supercomputing and researchers have now discovered that power.
By 2011, AI researchers around the world had discovered NVIDIA GPUs. The Google Brain project had just achieved amazing results — it learned to recognize cats and people by watching movies on YouTube. But it required 2,000 CPUs in servers powered and cooled in one of Google’s giant data centers. Few have computers of this scale. Enter NVIDIA and the GPU. Bryan Catanzaro in NVIDIA Research teamed with Andrew Ng’s team at Stanford to use GPUs for deep learning. As it turned out, 12 NVIDIA GPUs could deliver the deep-learning performance of 2,000 CPUs. Researchers at NYU, the University of Toronto, and the Swiss AI Lab accelerated their DNNs on GPUs. Then, the fireworks started.
Deep Learning Performs Miracles
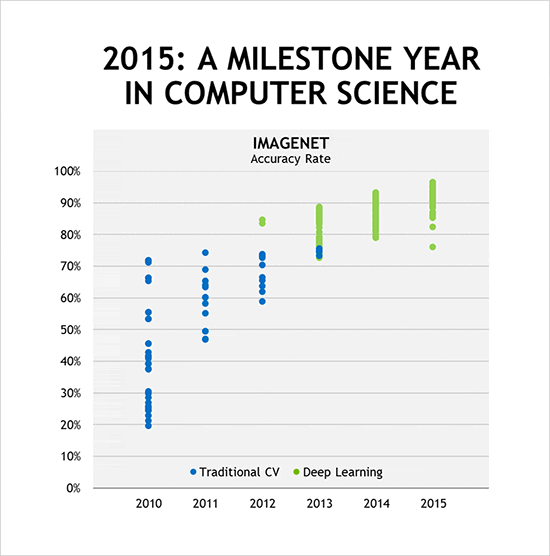
Alex Krizhevsky of the University of Toronto won the 2012 ImageNet computer image recognition competition.(1) Krizhevsky beat — by a huge margin — handcrafted software written by computer vision experts. Krizhevsky and his team wrote no computer vision code. Rather, using deep learning, their computer learned to recognize images by itself. They designed a neural network called AlexNet and trained it with a million example images that required trillions of math operations on NVIDIA GPUs. Krizhevksy’s AlexNet had beaten the best human-coded software.
 The AI race was on. By 2015, another major milestone was reached.
The AI race was on. By 2015, another major milestone was reached.
Using deep learning, Google and Microsoft both beat the best human score in the ImageNet challenge.(2,3) Not a human-written program, but a human. Shortly thereafter, Microsoft and the China University of Science and Technology announced a DNN that achieved IQ test scores at the college post-graduate level.(4) Then Baidu announced that a deep learning system called Deep Speech 2 had learned both English and Mandarin with a single algorithm.(5) And all top results of the 2015 ImageNet competition were based on deep learning, running on GPU-accelerated deep neural networks, and many beating human-level accuracy.
In 2012, deep learning had beaten human-coded software. By 2015, deep learning had achieved “superhuman” levels of perception.
A New Computing Platform for a New Software Model
Computer programs contain commands that are largely executed sequentially. Deep learning is a fundamentally new software model where billions of software-neurons and trillions of connections are trained, in parallel. Running DNN algorithms and learning from examples, the computer is essentially writing its own software. This radically different software model needs a new computer platform to run efficiently. 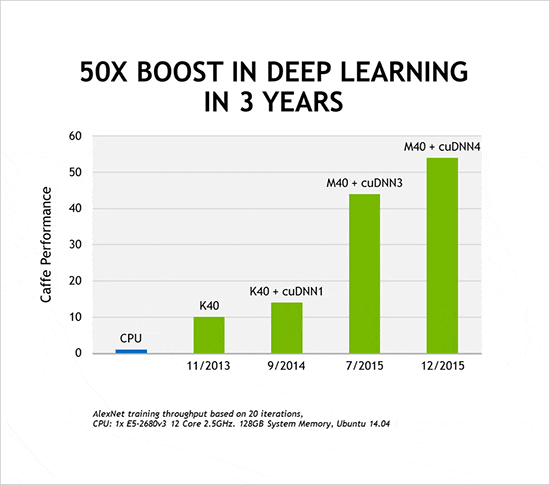 Accelerated computing is an ideal approach and the GPU is the ideal processor. As Nature recently noted, early progress in deep learning was “made possible by the advent of fast graphics processing units (GPUs) that were convenient to program and allowed researchers to train networks 10 or 20 times faster.”(6) A combination of factors is essential to create a new AI computing — performance, programming productivity, and open accessibility.
Accelerated computing is an ideal approach and the GPU is the ideal processor. As Nature recently noted, early progress in deep learning was “made possible by the advent of fast graphics processing units (GPUs) that were convenient to program and allowed researchers to train networks 10 or 20 times faster.”(6) A combination of factors is essential to create a new AI computing — performance, programming productivity, and open accessibility.
Performance. NVIDIA GPUs are naturally great at parallel workloads and speed up DNNs by 10-20x, reducing each of the many training iterations from weeks to days. We didn’t stop there. By collaborating with AI developers, we continued to improve our GPU designs, system architecture, compilers, and algorithms, and sped up training deep neural networks by 50x in just three years — a much faster pace than Moore’s Law. We expect another 10x boost in the next few years.
Programmability. AI innovation is on a breakneck pace. Ease of programming and developer productivity are paramount. The programmability and richness of NVIDIA’s CUDA platform allow researchers to innovate quickly — building new configurations of CNNs, DNNs, deep inception networks, RNNs, LSTMs, and reinforcement learning networks.

Accessibility. Developers want to create anywhere and deploy everywhere. NVIDIA GPUs are available all over the world, from every PC OEM; in desktops, notebooks, servers, or supercomputers; and in the cloud from Amazon, IBM, and Microsoft. All major AI development frameworks are NVIDIA GPU accelerated — from internet companies, to research, to startups. No matter the AI development system preferred, it will be faster with GPU acceleration. We have also created GPUs for just about every computing form-factor so that DNNs can power intelligent machines of all kinds. GeForce is for PC. Tesla is for cloud and supercomputers. Jetson is for robots and drones. And DRIVE PX is for cars. All share the same architecture and accelerate deep learning.
Every Industry Wants Intelligence
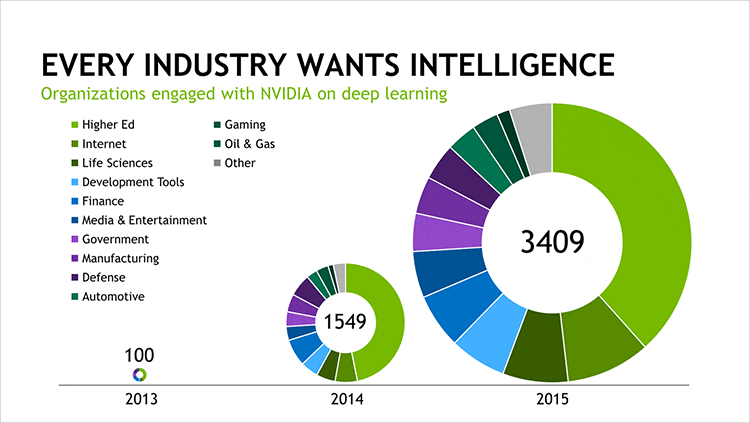
Baidu, Google, Facebook, Microsoft were the first adopters of NVIDIA GPUs for deep learning. This AI technology is how they respond to your spoken word, translate speech or text to another language, recognize and automatically tag images, and recommend newsfeeds, entertainment, and products that are tailored to what each of us likes and cares about. Startups and established companies are now racing to use AI to create new products and services, or improve their operations. In just two years, the number of companies NVIDIA collaborates with on deep learning has jumped nearly 35x to over 3,400 companies. Industries such as healthcare, life sciences, energy, financial services, automotive, manufacturing, and entertainment will benefit by inferring insight from mountains of data. And, with Facebook, Google, and Microsoft opening their deep-learning platforms for all to use, AI-powered applications will spread fast. In light of this trend, Wired recently heralded the “rise of the GPU.”
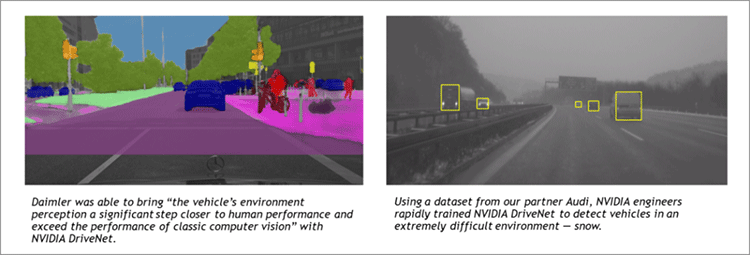
Self-driving cars. Whether to augment humans with a superhuman co-pilot, or revolutionize personal mobility services, or reduce the need for sprawling parking lots within cities, self-driving cars have the potential to do amazing social good. Driving is complicated. Unexpected things happen. Freezing rain turns the road into a skating rink. The road to your destination is closed. A child runs out in front of the car. You can’t write software that anticipates every possible scenario a self-driving car might encounter. That’s the value of deep learning; it can learn, adapt, and improve. We are building an end-to-end deep learning platform called NVIDIA DRIVE PX for self-driving cars — from the training system to the in-car AI computer. The results are very exciting. A future with superhuman computer co-pilots and driverless shuttles is no longer science fiction.
Robots. FANUC, a leading manufacturing robot maker, recently demonstrated an assembly-line robot that learned to “pick” randomly oriented objects out of a bin. The GPU-powered robot learned by trial and error. This deep-learning technology was developed by Preferred Networks, which was recently featured in a The Wall Street Journal article headlined, “Japan Seeks Tech Revival with Artificial Intelligence.”
Healthcare and Life Sciences. Deep Genomics is applying GPU-based deep learning to understand how genetic variations can lead to disease. Arterys uses GPU-powered deep learning to speed analysis of medical images. Its technology will be deployed in GE Healthcare MRI machines to help diagnose heart disease. Enlitic is using deep learning to analyze medical images to identify tumors, nearly invisible fractures, and other medical conditions.
These are just a handful of examples. There are literally thousands.
Accelerating AI with GPUs: A New Computing Model
Deep-learning breakthroughs have sparked the AI revolution. Machines powered by AI deep neural networks solve problems too complex for human coders. They learn from data and improve with use. The same DNN can be trained by even non-programmers to solve new problems. Progress is exponential. Adoption is exponential. And we believe the impact to society will also be exponential. A recent study by KPMG predicts that computerized driver assistance technologies will help reduce car accidents 80% in 20 years — that’s nearly 1 million lives a year saved. Deep-learning AI will be its cornerstone technology.
The impact to the computer industry will also be exponential. Deep learning is a fundamentally new software model. So we need a new computer platform to run it — an architecture that can efficiently execute programmer-coded commands as well as the massively parallel training of deep neural networks. We are betting that GPU-accelerated computing is the horse to ride. Popular Science recently called the GPU “the workhorse of modern A.I.” We agree.
Looking for a crash course in AI? Check out our cheat sheet to find the top courses to learn AI and machine learning, fast.
REFERENCES
- A. Krizhevsky, I. Sutskever, G. Hinton. ImageNet classification with deep convolutional neural networks. In Proc. Advances in Neural Information Processing Systems 25 1090–1098 (2012).
- K. He, X. Zhang, S. Ren, J. Sun. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. arXiv:1502.01852 [cs] (2015).
- S. Ioffe, C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning (ICML) 448–456 (2015).
- H. Wang, B. Gao, J. Bian, F. Tian, T.Y. Liu. Solving Verbal Comprehension Questions in IQ Test by Knowledge-Powered Word Embedding. arXiv:1505.07909 [cs.CL] (2015).
- D. Amodei, R. Anubhai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, J. Chen, M. Chrzanowski, A. Coates, G. Diamos, E. Elsen, J. Engel, L. Fan, C. Fougner, T. Han, A. Hannun, B. Jun, P. LeGresley, L. Lin, S. Narang, A. Ng, S. Ozair, R. Prenger, J. Raiman, S. Satheesh, D. Seetapun, S. Sengupta, Y. Wang, Z. Wang, C. Wang, B. Xiao, D. Yogatama, J. Zhan, Z. Zhu. “Deep speech 2: End-to-end speech recognition in English and Mandarin,” arXiv preprint arXiv:1512.02595 (2015).
- Y. LeCun, Y. Bengio, G. Hinton. Deep Learning – Review. Nature (2015).