Editor’s note: This article, originally published on March 13, 2023, has been updated.
The mics were live and tape was rolling in the studio where the Miles Davis Quintet was recording dozens of tunes in 1956 for Prestige Records.
When an engineer asked for the next song’s title, Davis shot back, “I’ll play it, and tell you what it is later.”
Like the prolific jazz trumpeter and composer, researchers have been generating AI models at a feverish pace, exploring new architectures and use cases. According to the 2024 AI Index report from the Stanford Institute for Human-Centered Artificial Intelligence, 149 foundation models were published in 2023, more than double the number released in 2022.
They said transformer models, large language models (LLMs), vision language models (VLMs) and other neural networks still being built are part of an important new category they dubbed foundation models.
Foundation Models Defined
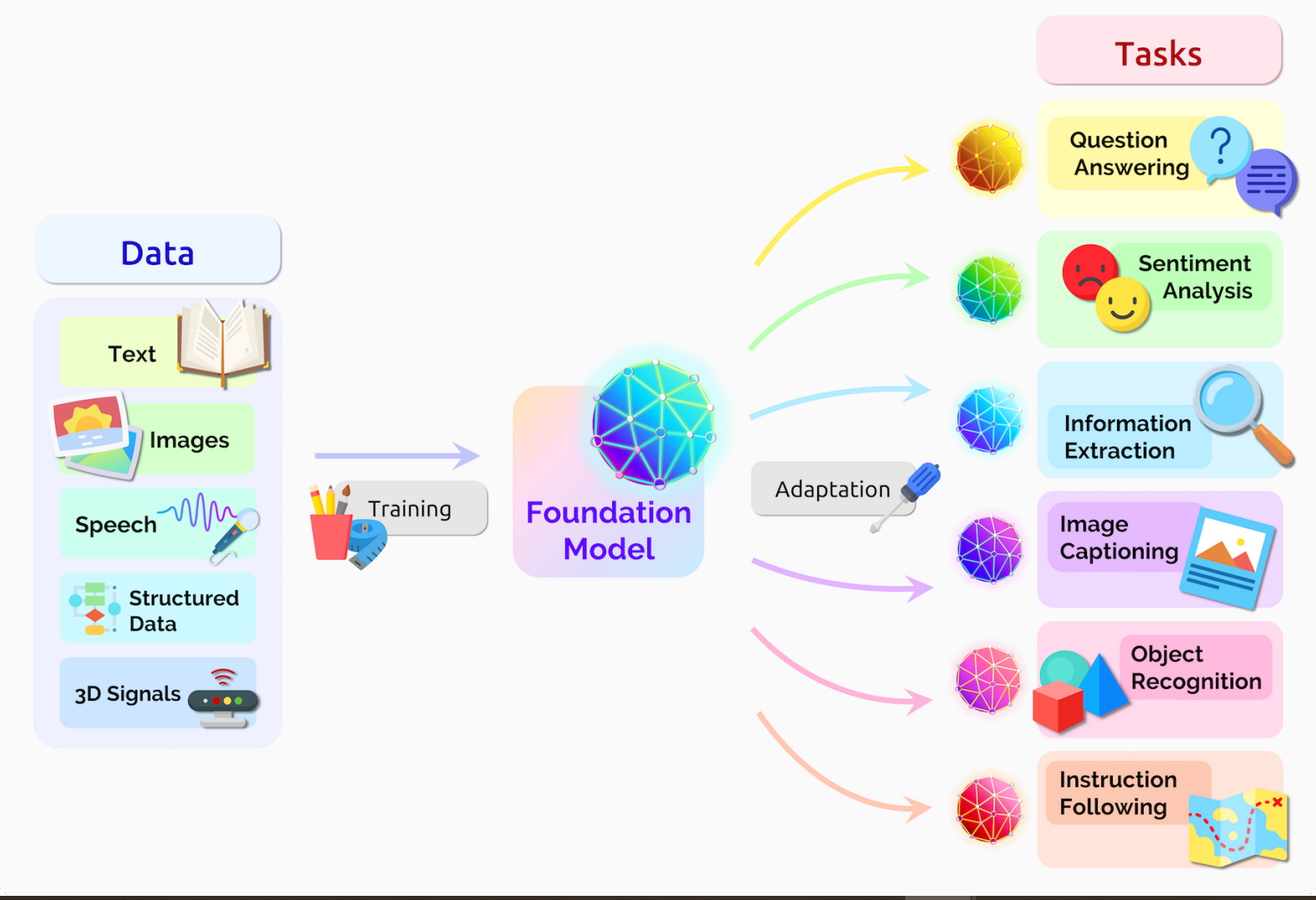
A foundation model is an AI neural network — trained on mountains of raw data, generally with unsupervised learning — that can be adapted to accomplish a broad range of tasks.
Two important concepts help define this umbrella category: Data gathering is easier, and opportunities are as wide as the horizon.
No Labels, Lots of Opportunity
Foundation models generally learn from unlabeled datasets, saving the time and expense of manually describing each item in massive collections.
Earlier neural networks were narrowly tuned for specific tasks. With a little fine-tuning, foundation models can handle jobs from translating text to analyzing medical images to performing agent-based behaviors.
“I think we’ve uncovered a very small fraction of the capabilities of existing foundation models, let alone future ones,” said Percy Liang, the center’s director, in the opening talk of the first workshop on foundation models.
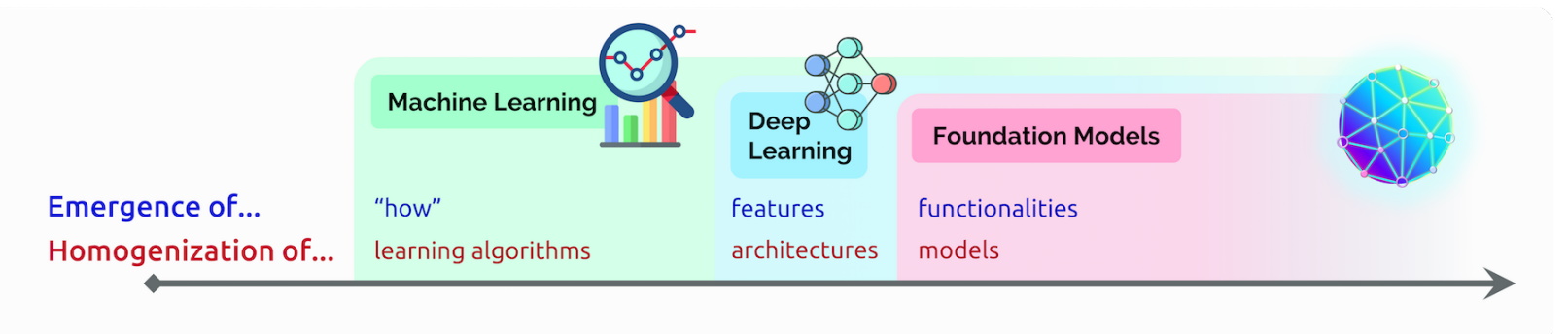
AI’s Emergence and Homogenization
In that talk, Liang coined two terms to describe foundation models:
Emergence refers to AI features still being discovered, such as the many nascent skills in foundation models. He calls the blending of AI algorithms and model architectures homogenization, a trend that helped form foundation models. (See chart below.)
 The field continues to move fast.
The field continues to move fast.
A year after the group defined foundation models, other tech watchers coined a related term — generative AI. It’s an umbrella term for transformers, large language models, diffusion models and other neural networks capturing people’s imaginations because they can create text, images, music, software, videos and more.
Generative AI has the potential to yield trillions of dollars of economic value, said executives from the venture firm Sequoia Capital who shared their views in a recent AI Podcast.
A Brief History of Foundation Models
“We are in a time where simple methods like neural networks are giving us an explosion of new capabilities,” said Ashish Vaswani, an entrepreneur and former senior staff research scientist at Google Brain who led work on the seminal 2017 paper on transformers.
That work inspired researchers who created BERT and other large language models, making 2018 “a watershed moment” for natural language processing, a report on AI said at the end of that year.
Google released BERT as open-source software, spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs. Then it applied the technology to its search engine so users could ask questions in simple sentences.
In 2020, researchers at OpenAI announced another landmark transformer, GPT-3. Within weeks, people were using it to create poems, programs, songs, websites and more.
“Language models have a wide range of beneficial applications for society,” the researchers wrote.
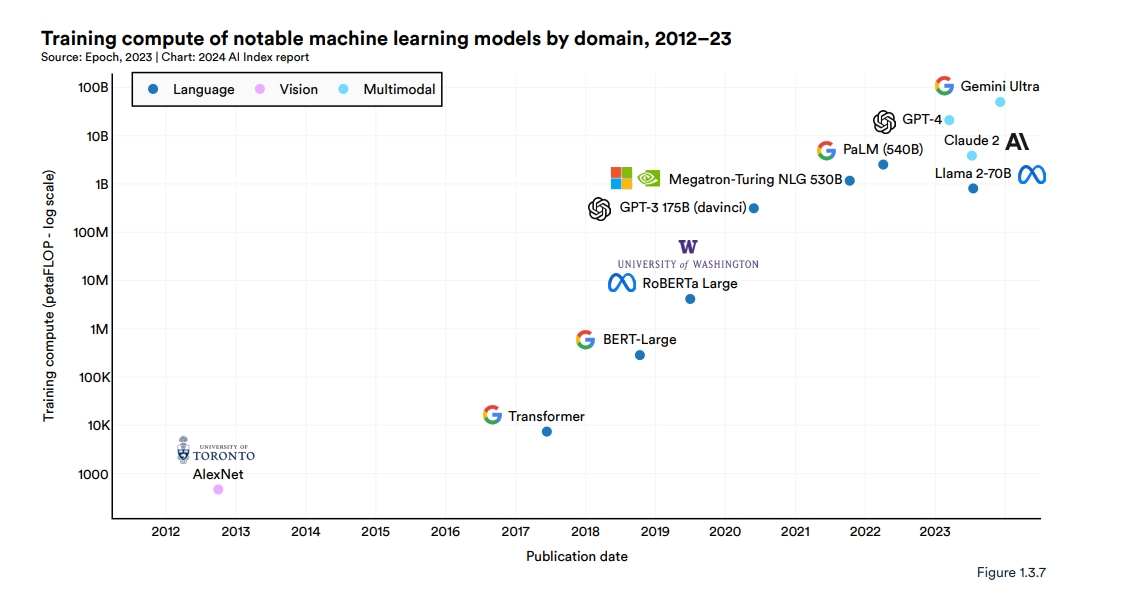
Their work also showed how large and compute-intensive these models can be. GPT-3 was trained on a dataset with nearly a trillion words, and it sports a whopping 175 billion parameters, a key measure of the power and complexity of neural networks. In 2024, Google released Gemini Ultra, a state-of-the-art foundation model that requires 50 billion petaflops.
“I just remember being kind of blown away by the things that it could do,” said Liang, speaking of GPT-3 in a podcast.
The latest iteration, ChatGPT — trained on 10,000 NVIDIA GPUs — is even more engaging, attracting over 100 million users in just two months. Its release has been called the iPhone moment for AI because it helped so many people see how they could use the technology.

Going Multimodal
Foundation models have also expanded to process and generate multiple data types, or modalities, such as text, images, audio and video. VLMs are one type of multimodal models that can understand video, image and text inputs while producing text or visual output.
Trained on 355,000 videos and 2.8 million images,
Cosmos Nemotron 34B is a leading VLM that enables the ability to query and summarize images and video from the physical or virtual world.
From Text to Images
About the same time ChatGPT debuted, another class of neural networks, called diffusion models, made a splash. Their ability to turn text descriptions into artistic images attracted casual users to create amazing images that went viral on social media.
The first paper to describe a diffusion model arrived with little fanfare in 2015. But like transformers, the new technique soon caught fire.
In a tweet, Midjourney CEO David Holz revealed that his diffusion-based, text-to-image service has more than 4.4 million users. Serving them requires more than 10,000 NVIDIA GPUs mainly for AI inference, he said in an interview (subscription required).
Toward Models That Understand the Physical World
The next frontier of artificial intelligence is physical AI, which enables autonomous machines like robots and self-driving cars to interact with the real world.
AI performance for autonomous vehicles or robots requires extensive training and testing. To ensure physical AI systems are safe, developers need to train and test their systems on massive amounts of data, which can be costly and time-consuming.
World foundation models, which can simulate real-world environments and predict accurate outcomes based on text, image, or video input, offer a promising solution.
Physical AI development teams are using NVIDIA Cosmos world foundation models, a suite of pre-trained autoregressive and diffusion models trained on 20 million hours of driving and robotics data, with the NVIDIA Omniverse platform to generate massive amounts of controllable, physics-based synthetic data for physical AI. Awarded the Best AI And Best Overall Awards at CES 2025, Cosmos world foundation models are open models that can be customized for downstream use cases or improve precision on a specific task using use case-specific data.
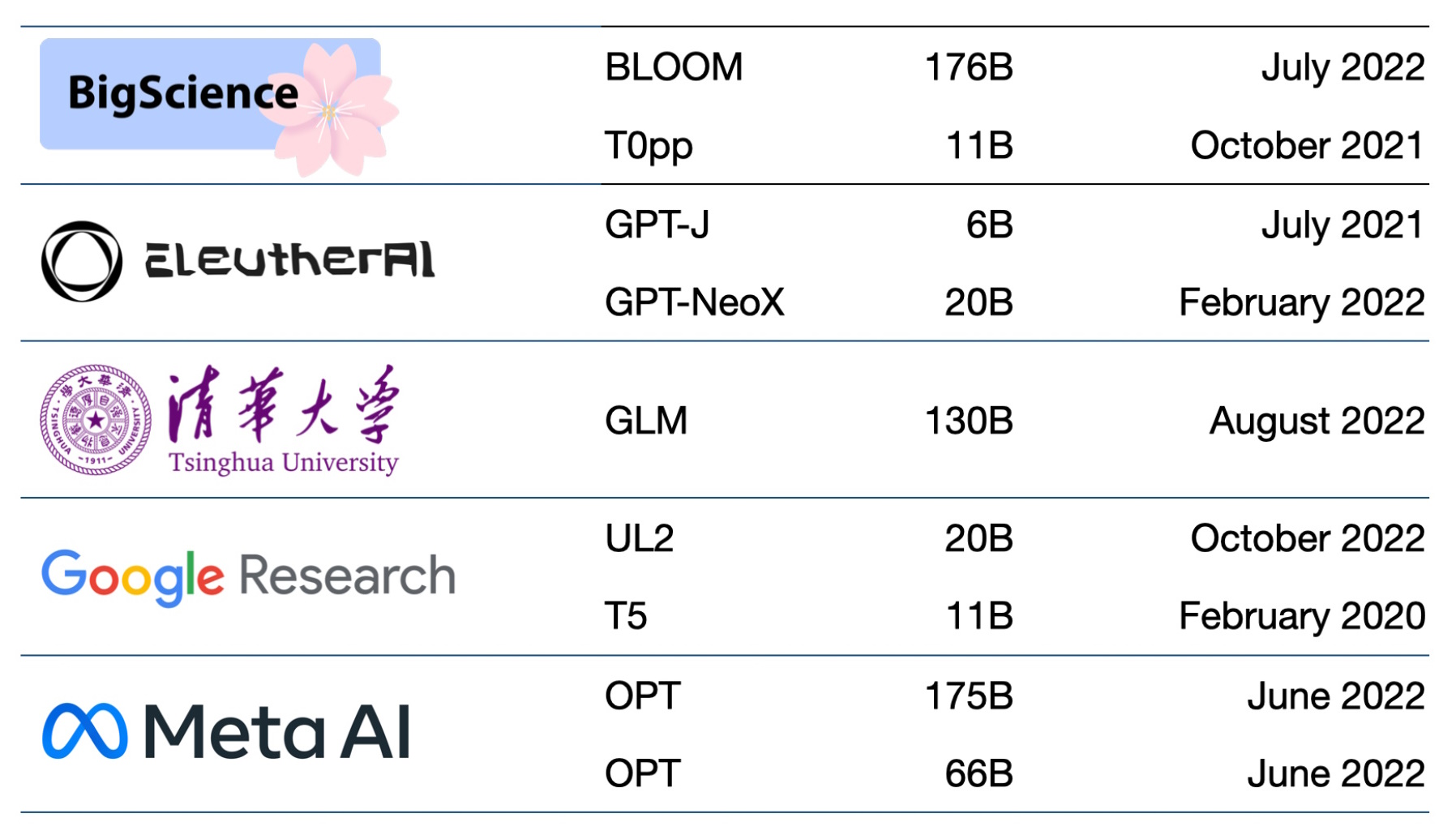
Dozens of Models in Use
Hundreds of foundation models are now available. One paper catalogs and classifies more than 50 major transformer models alone (see chart below).
The Stanford group benchmarked 30 foundation models, noting the field is moving so fast they did not review some new and prominent ones.
Startup NLP Cloud, a member of the NVIDIA Inception program that nurtures cutting-edge startups, says it uses about 25 large language models in a commercial offering that serves airlines, pharmacies and other users. Experts expect that a growing share of the models will be made open source on sites like Hugging Face’s model hub.
Foundation models keep getting larger and more complex, too.
That’s why — rather than building new models from scratch — many businesses are already customizing pretrained foundation models to turbocharge their journeys into AI, using online services like NVIDIA AI Foundation Models.
The accuracy and reliability of generative AI is increasing thanks to techniques like retrieval-augmented generation, aka RAG, that lets foundation models tap into external resources like a corporate knowledge base.
AI Foundations for Business
Another new framework, the NVIDIA NeMo framework, aims to let any business create its own billion- or trillion-parameter transformers to power custom chatbots, personal assistants and other AI applications.
It created the 530-billion parameter Megatron-Turing Natural Language Generation model (MT-NLG) that powers TJ, the Toy Jensen avatar that gave part of the keynote at NVIDIA GTC last year.
Foundation models — connected to 3D platforms like NVIDIA Omniverse — will be key to simplifying development of the metaverse, the 3D evolution of the internet. These models will power applications and assets for entertainment and industrial users.
Factories and warehouses are already applying foundation models inside digital twins, realistic simulations that help find more efficient ways to work.
Foundation models can ease the job of training autonomous vehicles and robots that assist humans on factory floors and logistics centers. They also help train autonomous vehicles by creating realistic environments like the one below.
New uses for foundation models are emerging daily, as are challenges in applying them.
Several papers on foundation and generative AI models describing risks such as:
- amplifying bias implicit in the massive datasets used to train models,
- introducing inaccurate or misleading information in images or videos, and
- violating intellectual property rights of existing works.
“Given that future AI systems will likely rely heavily on foundation models, it is imperative that we, as a community, come together to develop more rigorous principles for foundation models and guidance for their responsible development and deployment,” said the Stanford paper on foundation models.
Current ideas for safeguards include filtering prompts and their outputs, recalibrating models on the fly and scrubbing massive datasets.
“These are issues we’re working on as a research community,” said Bryan Catanzaro, vice president of applied deep learning research at NVIDIA. “For these models to be truly widely deployed, we have to invest a lot in safety.”
It’s one more field AI researchers and developers are plowing as they create the future.