
- NVIDIA Blackwell swept the new SemiAnalysis InferenceMAX v1 benchmarks, delivering the highest performance and best overall efficiency.
- The NVIDIA Blackwell architecture lowered cost per million tokens by 15x versus the previous generation.
- InferenceMax v1 is the first independent benchmark to measure total cost of compute across diverse models and real-world scenarios.
- Best return on investment: NVIDIA GB200 NVL72 delivers unmatched AI factory economics — a $5 million investment generates $75 million in DSR1 token revenue, a 15x return on investment.
- Lowest total cost of ownership: NVIDIA B200 software optimizations achieve two cents per million tokens on gpt-oss, delivering 5x lower cost per token in just 2 months.
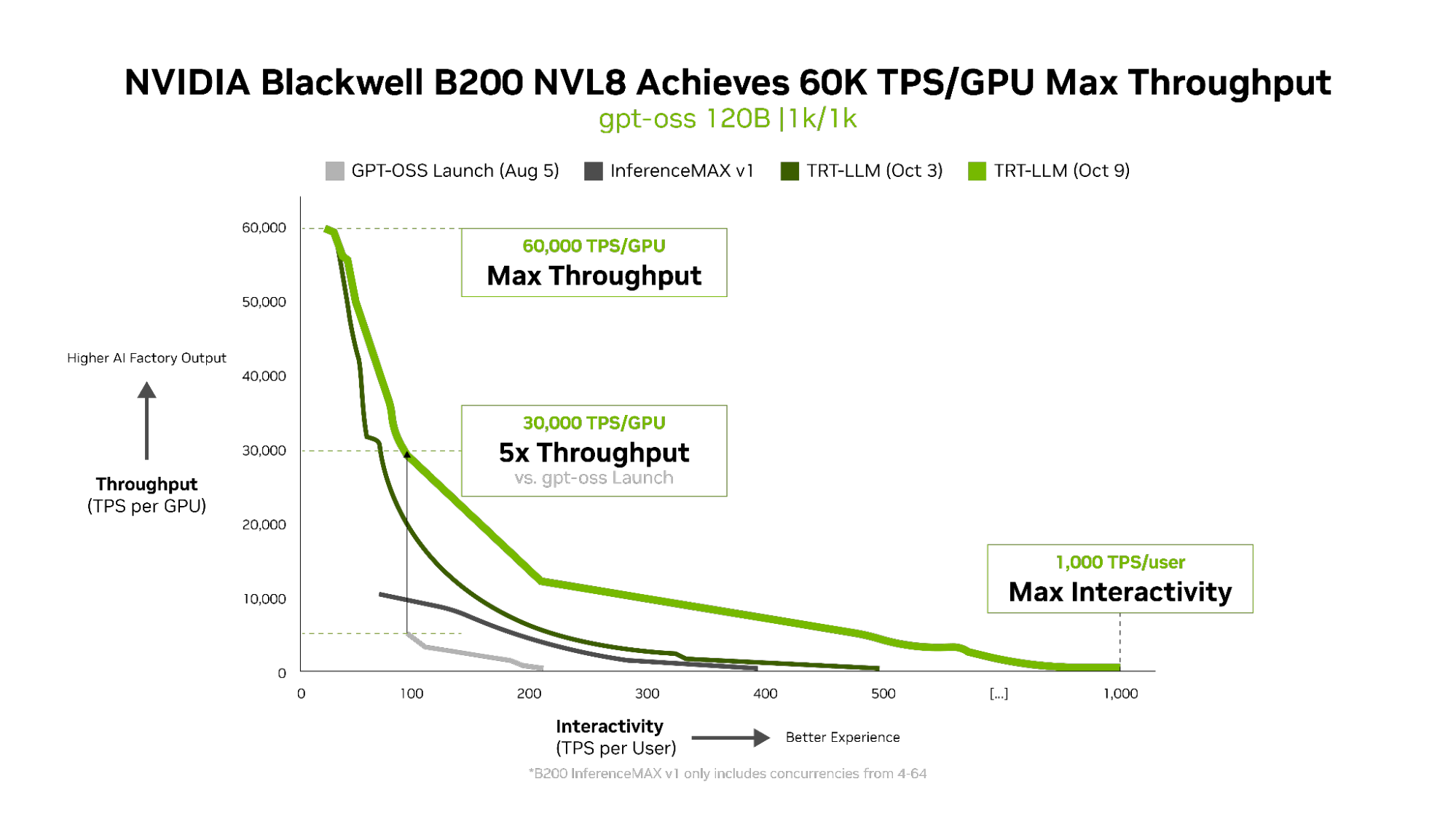
- Best throughput and interactivity: NVIDIA B200 sets the pace with 60,000 tokens per second per GPU and 1,000 tokens per second per user on gpt-oss with the latest NVIDIA TensorRT-LLM stack.
As AI shifts from one-shot answers to complex reasoning, the demand for inference — and the economics behind it — is exploding.
The new independent InferenceMAX v1 benchmarks are the first to measure total cost of compute across real-world scenarios. The results? The NVIDIA Blackwell platform swept the field — delivering unmatched performance and best overall efficiency for AI factories.
A $5 million investment in an NVIDIA GB200 NVL72 system can generate $75 million in token revenue. That’s a 15x return on investment (ROI) — the new economics of inference.
“Inference is where AI delivers value every day,” said Ian Buck, vice president of hyperscale and high-performance computing at NVIDIA. “These results show that NVIDIA’s full-stack approach gives customers the performance and efficiency they need to deploy AI at scale.”
What Is InferenceMAX v1 and Why Does It Matter for AI Economics?
InferenceMAX v1, a new benchmark from SemiAnalysis released Monday, is the latest to highlight Blackwell’s inference leadership. It runs popular models across leading platforms, measures performance for a wide range of use cases and publishes results anyone can verify.
Why do benchmarks like this matter?
Because modern AI isn’t just about raw speed — it’s about efficiency and economics at scale. As models shift from one-shot replies to multistep reasoning and tool use, they generate far more tokens per query, dramatically increasing compute demands.
NVIDIA’s open-source collaborations with OpenAI (gpt-oss 120B), Meta (Llama 3 70B), and DeepSeek AI (DeepSeek R1) highlight how community-driven models are advancing state-of-the-art reasoning and efficiency.
Partnering with these leading model builders and the open-source community, NVIDIA ensures the latest models are optimized for the world’s largest AI inference infrastructure. These efforts reflect a broader commitment to open ecosystems — where shared innovation accelerates progress for everyone.
Deep collaborations with the FlashInfer, SGLang and vLLM communities enable codeveloped kernel and runtime enhancements that power these models at scale.
How Did NVIDIA Double Blackwell Performance Through Continuous Software Optimizations to Lower Token Cost?
NVIDIA doubled Blackwell performance through continuous software optimization, refining kernels, compiler paths, and inference runtimes so the same hardware delivers significantly more useful AI throughput over time. Initial gpt-oss-120b performance on an NVIDIA DGX Blackwell B200 system with the NVIDIA TensorRT LLM library was market-leading, but NVIDIA’s teams and the community have significantly optimized TensorRT LLM for open-source large language models.
The TensorRT LLM v1.0 release is a major breakthrough in making large AI models faster and more responsive for everyone.
Through advanced parallelization techniques, it uses the B200 system and NVIDIA NVLink Switch’s 1,800 GB/s bidirectional bandwidth to dramatically improve the performance of the gpt-oss-120b model.
The innovation doesn’t stop there. The newly released gpt-oss-120b-Eagle3-v2 model introduces speculative decoding, a clever method that predicts multiple tokens at a time.
This reduces lag and delivers even quicker results, tripling throughput at 100 tokens per second per user (TPS/user) — boosting per-GPU speeds from 6,000 to 30,000 tokens.
For dense AI models like Llama 3.3 70B, which demand significant computational resources due to their large parameter count and the fact that all parameters are utilized simultaneously during inference, NVIDIA Blackwell B200 sets a new performance standard in InferenceMAX v1 benchmarks.
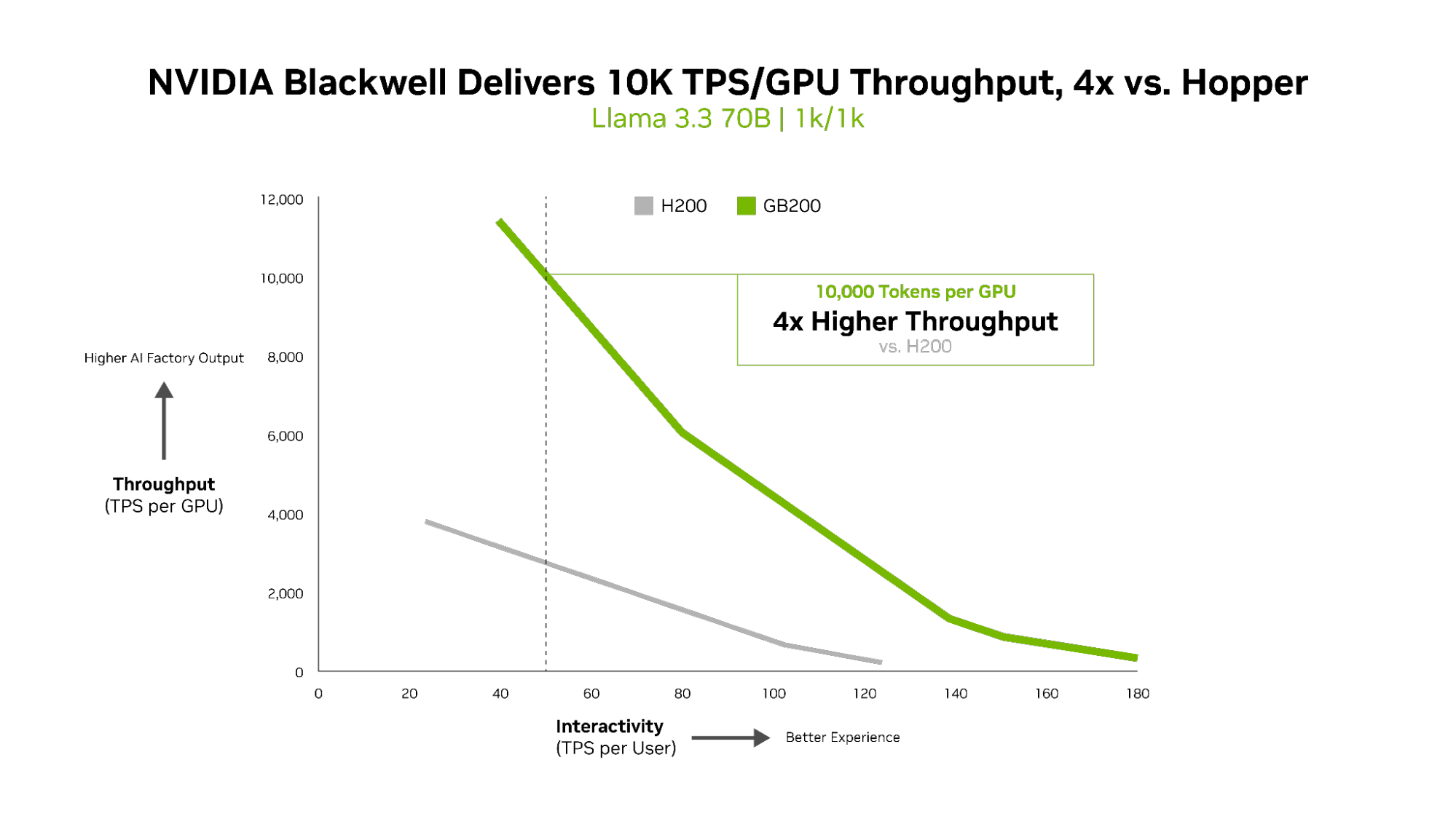
Blackwell delivers over 10,000 TPS per GPU at 50 TPS per user interactivity — 4x higher per-GPU throughput compared with the NVIDIA H200 GPU.
How Does Blackwell Achieve 15x Lower Cost Per Token and 10x Higher Efficiency?
Metrics like tokens per watt, cost per million tokens and TPS/user matter as much as throughput. In fact, for power-limited AI factories, Blackwell delivers 10x throughput per megawatt for mixture-of-experts models compared with the previous generation, which translates into higher token revenue.
The cost per token is crucial for evaluating AI model efficiency, directly impacting operational expenses. The NVIDIA Blackwell architecture lowered cost per million tokens by 15x versus the previous generation, leading to substantial savings and fostering wider AI deployment and innovation.
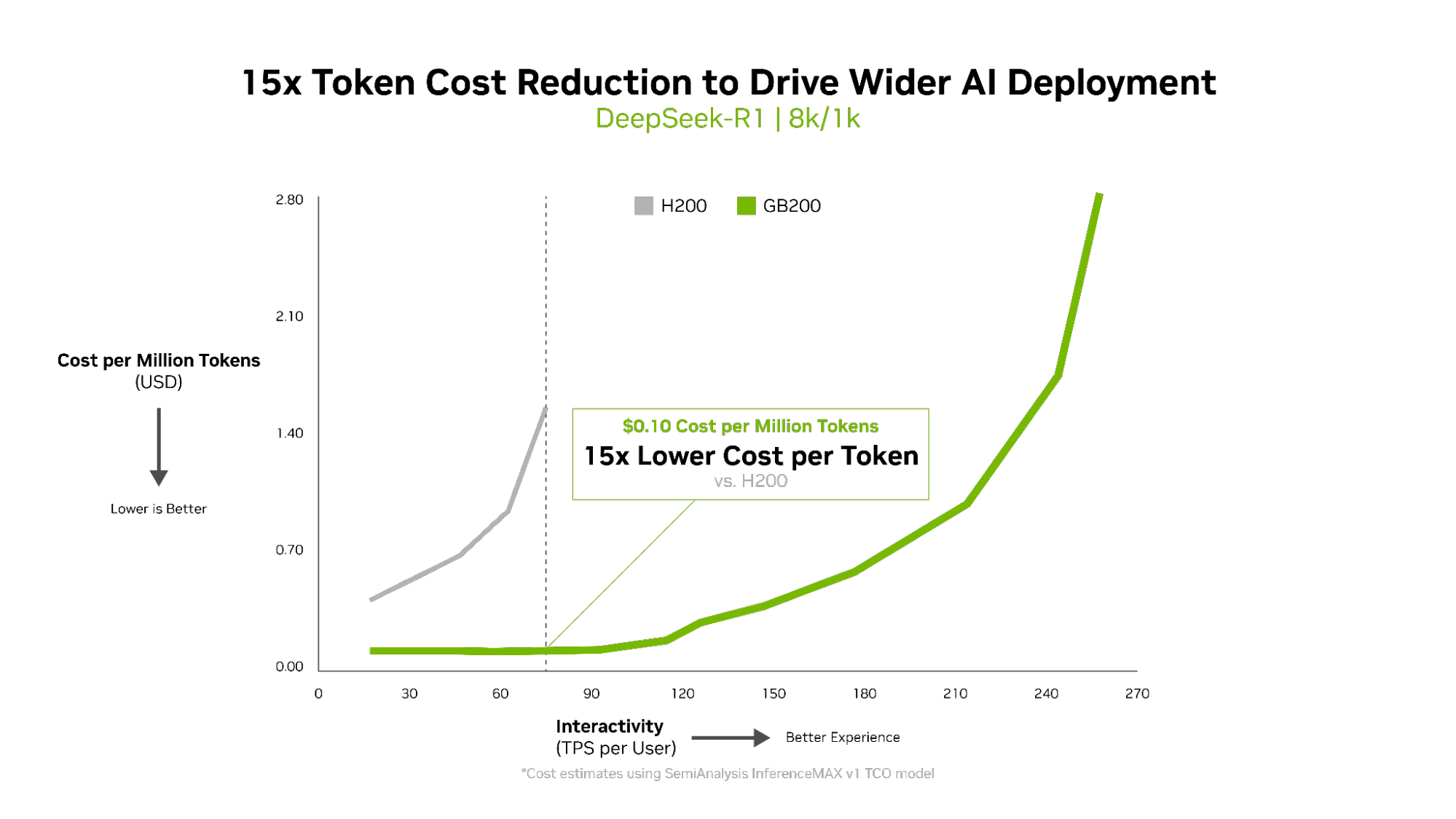
How Does Blackwell Balance Cost, Throughput, Efficiency and Responsiveness?
InferenceMAX uses the Pareto frontier — a curve that shows the best trade-offs between different factors, such as data center throughput and responsiveness — to map performance.
But it’s more than a chart. It reflects how NVIDIA Blackwell balances the full spectrum of production priorities: cost, energy efficiency, throughput and responsiveness. That balance enables the highest ROI across real-world workloads.
Systems that optimize for just one mode or scenario may show peak performance in isolation, but the economics of that doesn’t scale. Blackwell’s full-stack design delivers efficiency and value where it matters most: in production.
For a deeper look at how these curves are built — and why they matter for total cost of ownership and service-level agreement planning — read this technical deep dive on Blackwell on InferenceMAX benchmarks.
What Hardware-Software Innovations Power Blackwell’s Leadership?
Blackwell’s leadership comes from extreme hardware-software codesign. It’s a full-stack architecture built for speed, efficiency and scale:
- The Blackwell architecture features include:
- NVFP4 low-precision format for efficiency without loss of accuracy
- Fifth-generation NVIDIA NVLink that connects 72 Blackwell GPUs to act as one giant GPU
- NVLink Switch, which enables high concurrency through advanced tensor, expert and data parallel attention algorithms
- Annual hardware cadence plus continuous software optimization — NVIDIA has more than doubled Blackwell performance since launch using software alone
- NVIDIA TensorRT-LLM, NVIDIA Dynamo, SGLang and vLLM open-source inference frameworks optimized for peak performance
- A massive ecosystem, with hundreds of millions of GPUs installed, 7 million CUDA developers and contributions to over 1,000 open-source projects
How Is AI Shifting from Pilots to AI Factories and What’s Next?
AI is moving from pilots to AI factories — infrastructure that manufactures intelligence by turning data into tokens and decisions in real time.
Open, frequently updated benchmarks help teams make informed platform choices, tune for cost per token, latency service-level agreements and utilization across changing workloads.
Learn more about how to calculate lowest cost per token and how the NVIDIA Think SMART framework drives cost efficient inference.


