
The NVIDIA Blackwell architecture is the reigning leader of the AI revolution.
Many think of Blackwell as a chip, but it may be better to think of it as a platform powering large-scale AI infrastructure.
Surging Demand and Model Complexity
Blackwell is the core of an entire system architecture designed specifically to power AI factories that produce intelligence using the largest and most complex AI models.
Today’s frontier AI models have hundreds of billions of parameters and are estimated to serve nearly a billion users per week. The next generation of models are expected to have well over a trillion parameters — and are being trained on tens of trillions of tokens of data drawn from text, image and video datasets.
Scaling out a data center — harnessing up to thousands of computers to share the work — is necessary to meet this demand. But far greater performance and energy efficiency can come from first scaling up: by making a bigger computer.
Blackwell redefines the limits of just how big we can go.
Exponential growth of parameters in notable AI models over time.
Data Source: Epoch (2025), with major processing by Our World In Data
Today’s Most Challenging Form of Computing
AI factories are the machines of the next industrial revolution. Their work is AI inference — the most challenging form of computing known today — and their product is intelligence.
These factories require infrastructure that can adapt, scale out and maximize every bit of compute resource available.
What does that look like?
A symphony of compute, networking, storage, power and cooling — with integration at the silicon and systems levels, up and down racks — orchestrated by software that sees tens of thousands of Blackwell GPUs as one.
The new unit of the data center is NVIDIA GB200 NVL72, a rack-scale system that acts as a single, massive GPU.

NVIDIA CEO Jensen Huang shows off the NVIDIA GB200 NVL72 system and the NVIDIA Grace Blackwell superchip during his keynote at CES 2025.
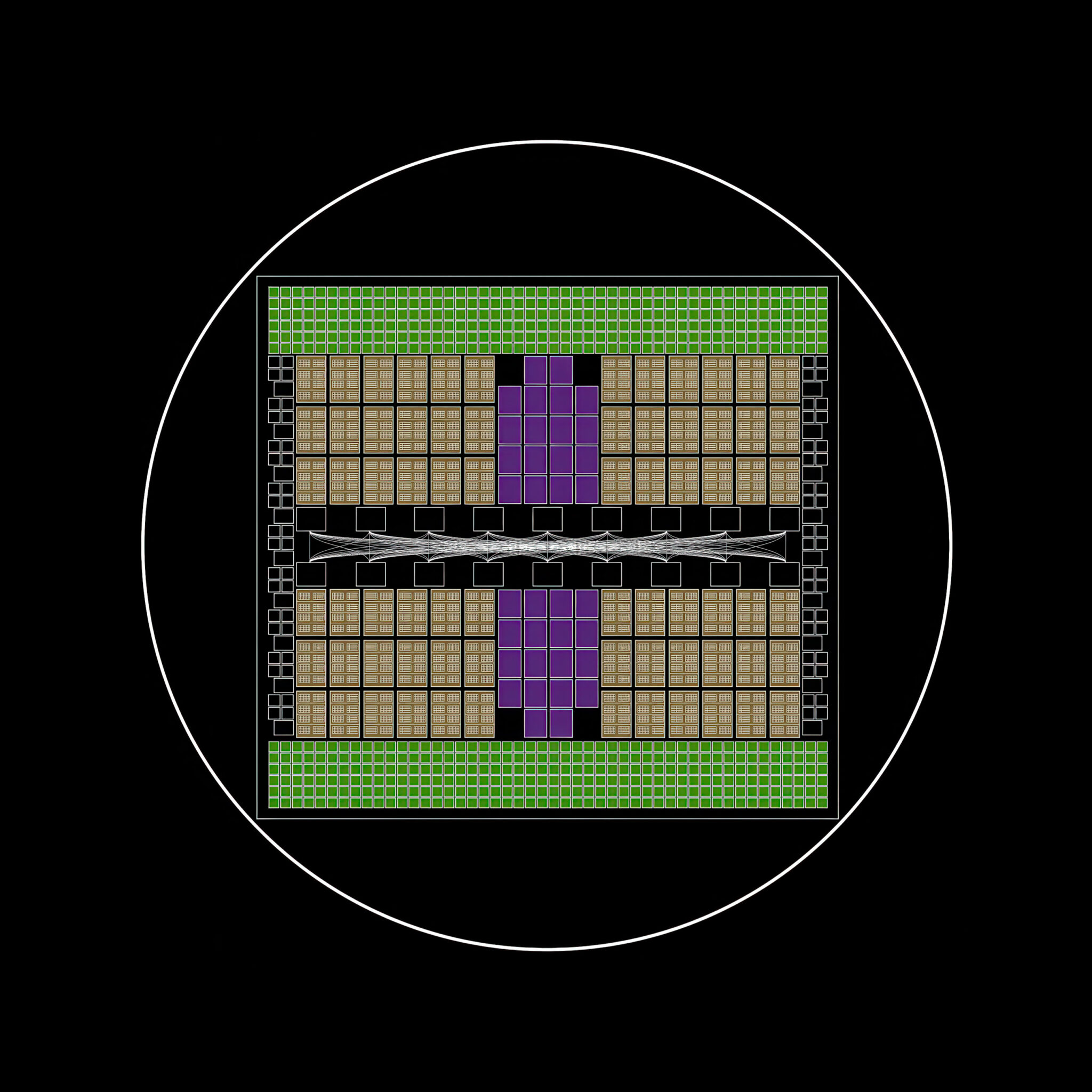
Birth of a Superchip
At the core, the NVIDIA Grace Blackwell superchip unites two Blackwell GPUs with one NVIDIA Grace CPU.
Fusing them into a unified compute module — a superchip — boosts performance by an order of magnitude. To do so requires a new high-speed interconnect technology introduced with the NVIDIA Hopper architecture: NVIDIA NVLink chip-to-chip.
This technology unlocks seamless communication between the CPU and GPUs, enabling them to share memory directly, resulting in lower latency and higher throughput for AI workloads.


It takes a symphony of creation, cutting, assembly and inspection to build a superchip.
A New Interconnect for the Superchip Era
Scaling this performance across multiple superchips without bottlenecks was impossible with previous networking technology. So NVIDIA created a new kind of interconnect to keep performance bottlenecks from emerging and enable AI at scale.

A Backbone That Clears Bottlenecks
The NVIDIA NVLink Switch spine anchors GB200 NVL72 with a precisely engineered web of over 5,000 high-performance copper cables, connecting 72 GPUs across 18 compute trays to move data at a staggering 130 TB/s.
That’s fast enough to transfer the entire internet’s peak traffic in less than a second.

Two miles of copper wire is precisely cut, measured, assembled and tested to create the blisteringly fast NVIDIA NVLink Switch spine.

The spine cartridge is inspected before installation.
The spine, powered up, can move an entire internet’s worth of data in less than a second.
Building One Giant GPU for Inference
The integration of all this advanced hardware and software, compute and networking enables GB200 NVL72 systems to unlock new possibilities for AI at scale.
Each rack weighs one-and-a-half tons — featuring more than 600,000 parts, two miles of wire and millions of lines of code converged.
It acts as one giant virtual GPU, making factory-scale AI inference possible, where every nanosecond and watt matters.


GB200 NVL72 Everywhere
NVIDIA then deconstructed GB200 NVL72 so that partners and customers can configure and build their own NVL72 systems.
Each NVL72 system is a two-ton, 1.2-million-part supercomputer. NVL72 systems are manufactured across more than 150 factories worldwide with 200 technology partners.










From cloud giants to system builders, partners worldwide are producing NVIDIA Blackwell NVL72 systems.
Time to Scale Out
Tens of thousands of Blackwell NVL72 systems converge to create AI factories.
Working together isn’t enough. They must work as one.
NVIDIA Spectrum-X Ethernet and Quantum-X800 InfiniBand switches make this unified effort possible at the data center level.
Each GPU in an NVL72 system is connected directly to the factory’s data network, and to every other GPU in the system. GB200 NVL72 systems offer 400 Gbps of Ethernet or InfiniBand interconnect using NVIDIA ConnectX-7 NICs.

NVIDIA Quantum-X800 Switch, NVLink Switch, and Spectrum-X Ethernet unify one or many NVL72 systems to function as one.


Opening Lines of Communication
Scaling out AI factories requires many tools, each in service of one thing: unrestricted, parallel communication for every AI workload in the factory.
NVIDIA BlueField-3 DPUs do their part to boost AI performance by offloading and accelerating the non-AI tasks that keep the factory running: the symphony of networking, storage and security.

NVIDIA GB200 NVL72 powers an AI factory by CoreWeave, an NVIDIA Cloud Partner.

The AI Factory Operating System
The data center is now the computer. NVIDIA Dynamo is its operating system.
Dynamo orchestrates and coordinates AI inference requests across a large fleet of GPUs to ensure that AI factories run at the lowest possible cost to maximize productivity and revenue.
It can add, remove and shift GPUs across workloads in response to surges in customer use, and route queries to the GPUs best fit for the job.

Colossus, xAI’s AI supercomputer. Created in 122 days, it houses over 200,000 NVIDIA GPUs — an example of a full-stack, scale-out architecture.
Blackwell is more than a chip. It’s the engine of AI factories.
The world’s largest-planned computing clusters are being built on the Blackwell and Blackwell Ultra architectures — with approximately 1,000 racks of NVIDIA GB300 systems produced each week.
Related News


