
In the age of AI reasoning, training smarter, more capable models is critical to scaling intelligence. Delivering the massive performance to meet this new age requires breakthroughs across GPUs, CPUs, NICs, scale-up and scale-out networking, system architectures, and mountains of software and algorithms.
In MLPerf Training v5.1 — the latest round in a long-running series of industry-standard tests of AI training performance — NVIDIA swept all seven tests, delivering the fastest time to train across large language models (LLMs), image generation, recommender systems, computer vision and graph neural networks.
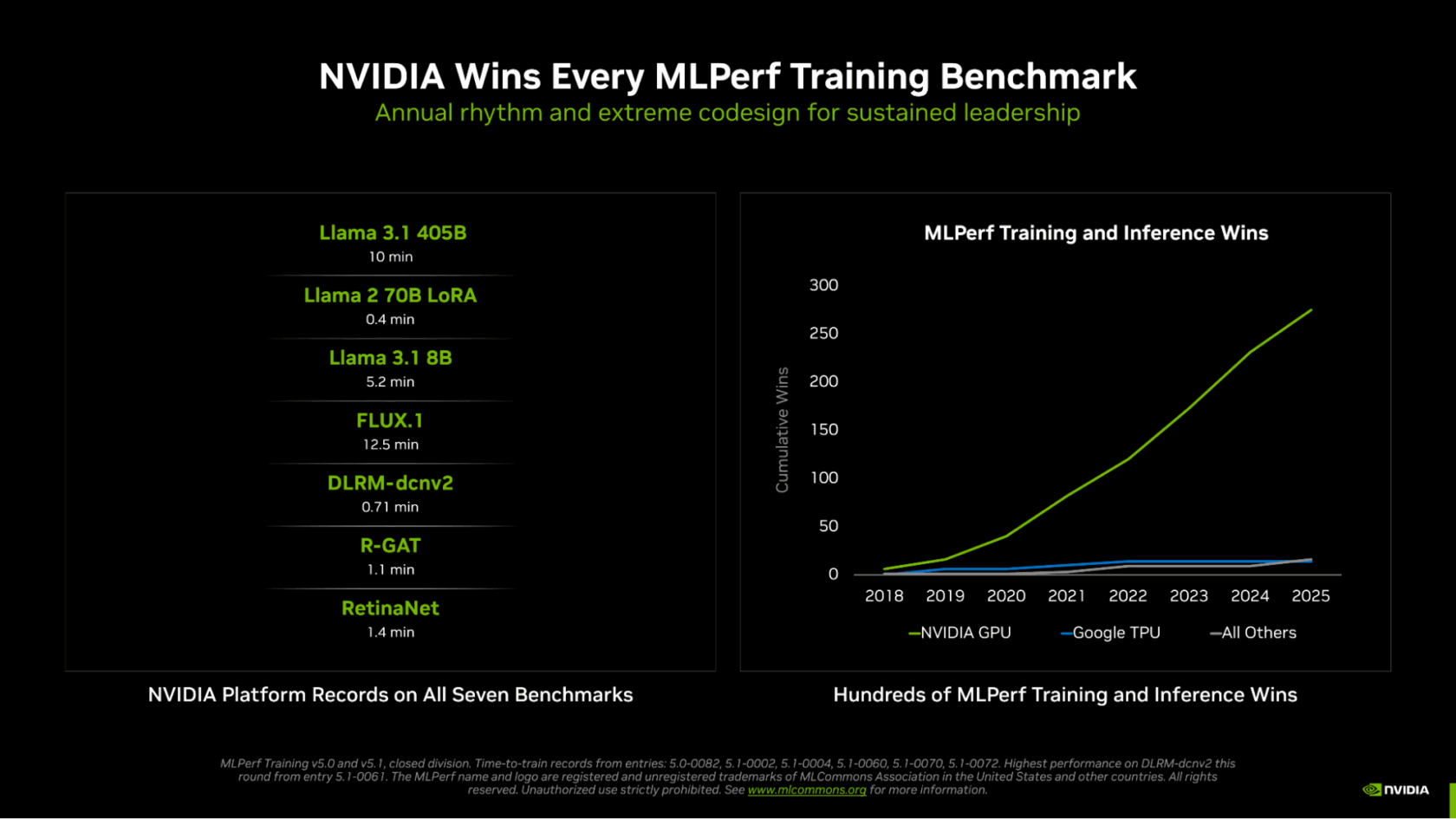
NVIDIA was also the only platform to submit results on every test, underscoring the rich programmability of NVIDIA GPUs, and the maturity and versatility of its CUDA software stack.
NVIDIA Blackwell Ultra Doubles Down
The GB300 NVL72 rack-scale system, powered by the NVIDIA Blackwell Ultra GPU architecture, made its debut in MLPerf Training this round, following a record-setting showing in the most recent MLPerf Inference round.
Compared with the prior-generation Hopper architecture, the Blackwell Ultra-based GB300 NVL72 delivered more than 4x the Llama 3.1 405B pretraining and nearly 5x the Llama 2 70B LoRA fine-tuning performance using the same number of GPUs.
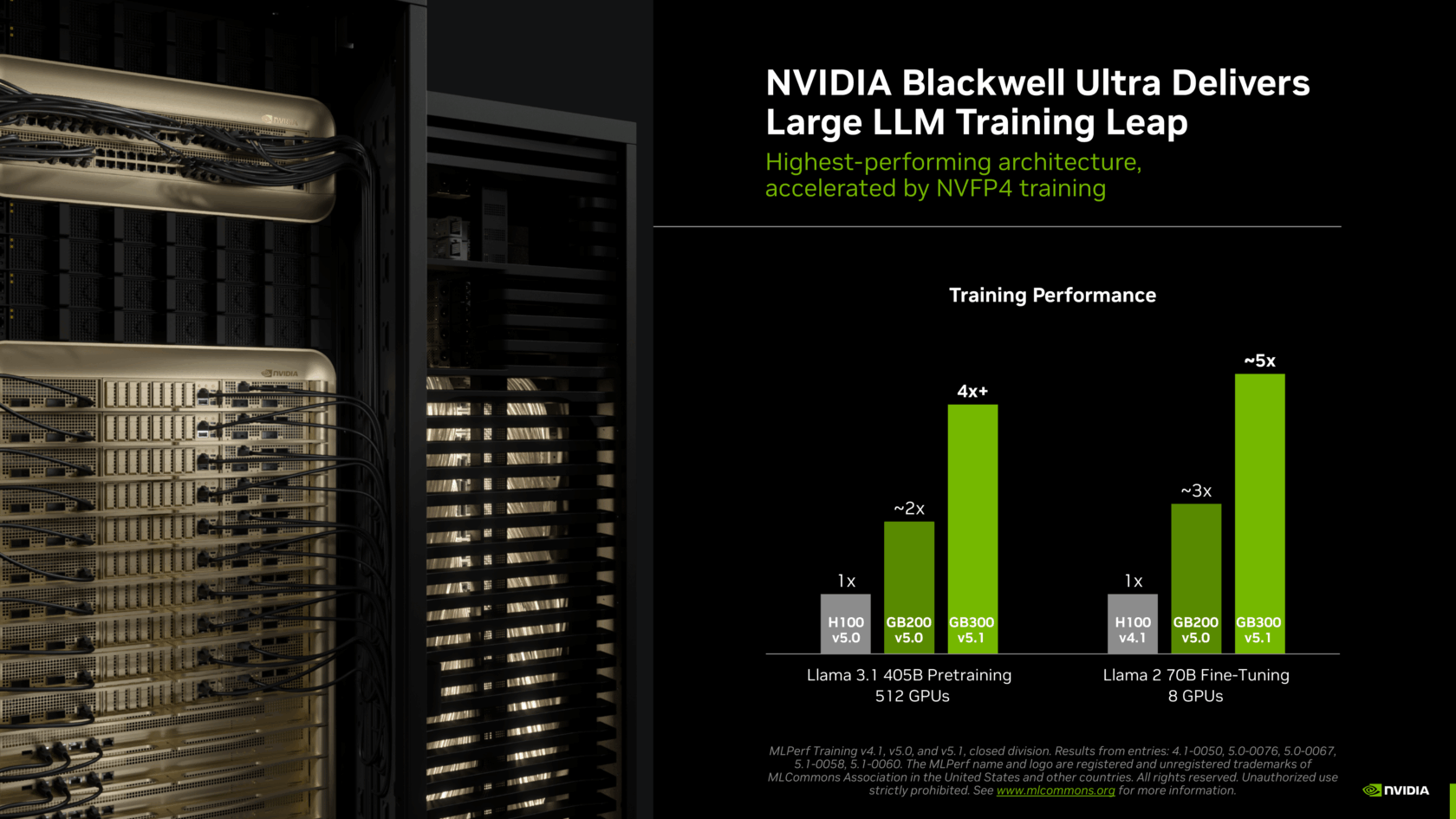
These gains were fueled by Blackwell Ultra’s architectural improvements — including new Tensor Cores that offer 15 petaflops of NVFP4 AI compute, twice the attention-layer compute and 279GB of HBM3e memory — as well as new training methods that tapped into the architecture’s enormous NVFP4 compute performance.
Connecting multiple GB300 NVL72 systems, the NVIDIA Quantum-X800 InfiniBand platform — the industry’s first end-to-end 800 Gb/s networking platform — also made its MLPerf debut, doubling scale-out networking bandwidth compared with the prior generation.
Performance Unlocked: NVFP4 Accelerates LLM Training
Key to the outstanding results this round was performing calculations using NVFP4 precision — a first in the history of MLPerf Training.
One way to increase compute performance is to build an architecture capable of performing computations on data represented with fewer bits, and then to perform those calculations at a faster rate. However, lower precision means less information is available in each calculation. This means using low-precision calculations in the training process calls for careful design decisions to keep results accurate.
NVIDIA teams innovated at every layer of the stack to adopt FP4 precision for LLM training. The NVIDIA Blackwell GPU can perform FP4 calculations — including the NVIDIA-designed NVFP4 format as well as other FP4 variants — at double the rate of FP8. Blackwell Ultra boosts that to 3x, enabling the GPUs to deliver substantially greater AI compute performance.
NVIDIA is the only platform to date that has submitted MLPerf Training results with calculations performed using FP4 precision while meeting the benchmark’s strict accuracy requirements.
NVIDIA Blackwell Scales to New Heights
NVIDIA set a new Llama 3.1 405B time-to-train record of just 10 minutes, powered by more than 5,000 Blackwell GPUs working together efficiently. This entry was 2.7x faster than the best Blackwell-based result submitted in the prior round, resulting from efficient scaling to more than twice the number of GPUs, as well as the use of NVFP4 precision to dramatically increase the effective performance of each Blackwell GPU.
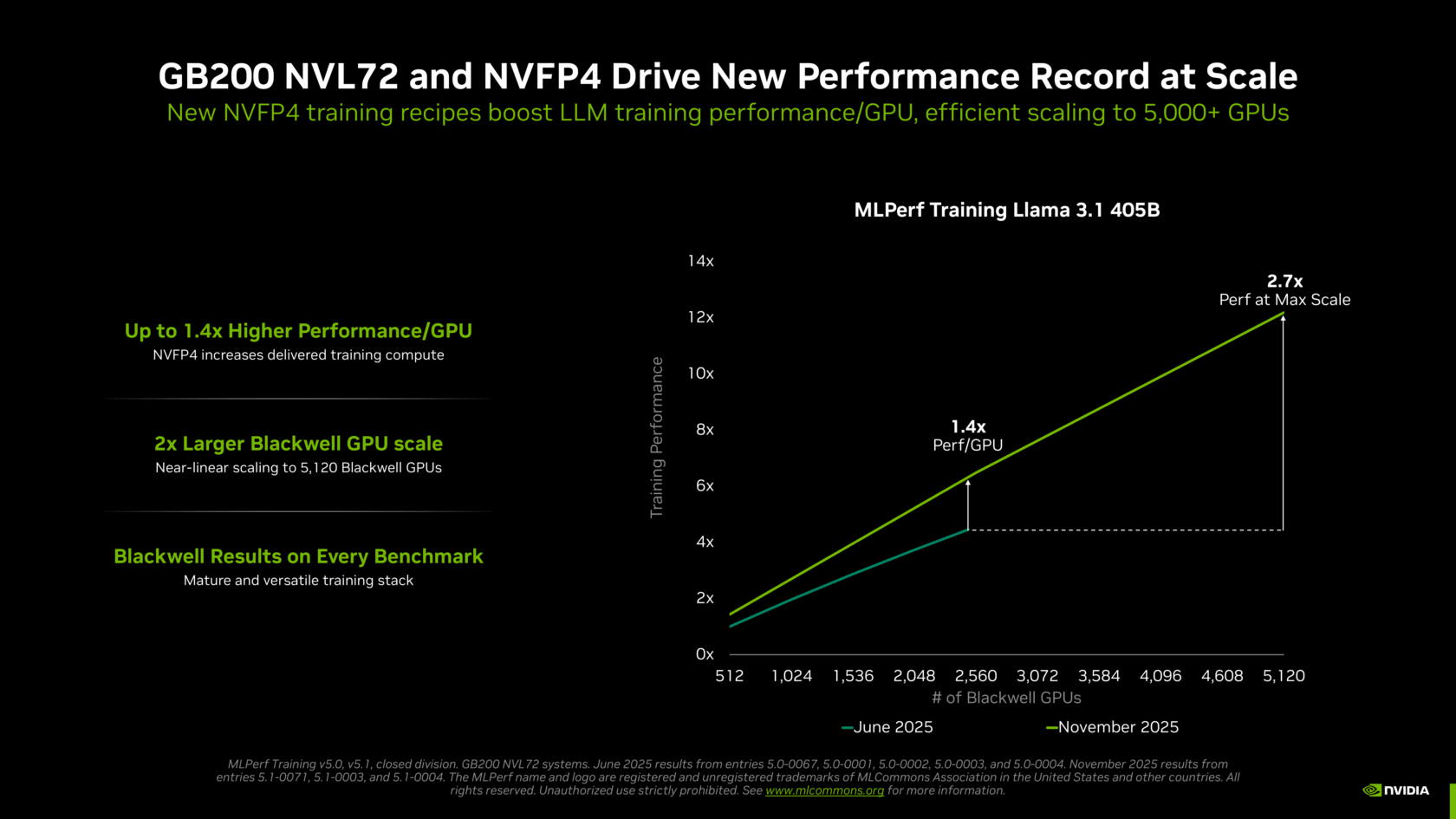
To illustrate the performance increase per GPU, NVIDIA submitted results this round using 2,560 Blackwell GPUs, achieving a time to train of 18.79 minutes — 45% faster than the submission last round using 2,496 GPUs.
New Benchmarks, New Records
NVIDIA also set performance records on the two new benchmarks added this round: Llama 3.1 8B and FLUX.1.
Llama 3.1 8B — a compact yet highly capable LLM — replaced the long-running BERT-large model, adding a modern, smaller LLM to the benchmark suite. NVIDIA submitted results with up to 512 Blackwell Ultra GPUs, setting the bar at 5.2 minutes to train.
In addition, FLUX.1 — a state-of-the-art image generation model — replaced Stable Diffusion v2, with only the NVIDIA platform submitting results on the benchmark. NVIDIA submitted results using 1,152 Blackwell GPUs, setting a record time to train of 12.5 minutes.
NVIDIA continued to hold records on the existing graph neural network, object detection and recommender system tests.
A Broad and Deep Partner Ecosystem
The NVIDIA ecosystem participated extensively this round, with compelling submissions from 15 organizations including ASUS, Dell Technologies, Giga Computing, Hewlett Packard Enterprise, Krai, Lambda, Lenovo, Nebius, Quanta Cloud Technology, Supermicro, University of Florida, Verda (formerly DataCrunch) and Wiwynn.
NVIDIA is innovating at a one-year rhythm, driving significant and rapid performance increases across pretraining, post-training and inference — paving the way to new levels of intelligence and accelerating AI adoption.
See more NVIDIA performance data on the Data Center Deep Learning Product Performance Hub and Performance Explorer pages.


