Editor’s note: The name of the NVIDIA Transfer Learning Toolkit was changed to NVIDIA TAO Toolkit in August 2021. All references to the name have been updated in this blog.
You probably have a career. But hit the books for a graduate degree or take online certificate courses by night, and you could start a new career building on your past experience.
Transfer learning is the same idea. This deep learning technique enables developers to harness a neural network used for one task and apply it to another domain.
Take image recognition. Let’s say that you want to identify horses, but there aren’t any publicly available algorithms that do an adequate job. With transfer learning, you begin with an existing convolutional neural network commonly used for image recognition of other animals, and you tweak it to train with horses.
ResNet to the Rescue
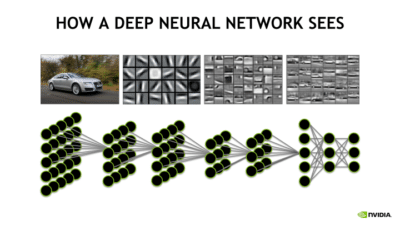 Developers might start with ResNet-50 — a pre-trained deep learning model consisting of 50 layers — because it has a high accuracy level for identifying cats or dogs. Within the neural network are layers that are used to identify outlines, curves, lines and other identifying features of these animals. The layers required a lot of labeled training data, so using them saves a lot of time.
Developers might start with ResNet-50 — a pre-trained deep learning model consisting of 50 layers — because it has a high accuracy level for identifying cats or dogs. Within the neural network are layers that are used to identify outlines, curves, lines and other identifying features of these animals. The layers required a lot of labeled training data, so using them saves a lot of time.
Those layers can be applied to the task of carrying out the same identification on some horse features. You might be able to identify eyes, ears, legs and outlines of horses with ResNet-50, but to determine it was a horse and not a dog might require some additional training data.
And with additional training by feeding labeled training data for horses — more horse-specific features can be built into the model.
Transfer Learning Explained
Here’s how it works: First, you delete what’s known as the “loss output” layer, which is the final layer used to make predictions, and replace it with a new loss output layer for horse prediction. This loss output layer is a fine-tuning node for determining how training penalizes deviations from the labeled data and the predicted output.
Next, you would take your smaller dataset for horses and train it on the entire 50-layer neural network or the last few layers or just the loss layer alone. By applying these transfer learning techniques, your output on the new CNN will be horse identification.
Word Up, Speech!
Transfer learning isn’t just for image recognition. Recurrent neural networks, often used in speech recognition, can take advantage of transfer learning, as well. However, you’ll need two similar speech-related datasets, such as a million hours of speech from a pre-existing model and 10 hours of speech specific to the new task.
Similar to techniques used on a CNN, this new neural network’s loss layer is removed. Next, you might create two or more layers in its place that use your new speech data to help train the network and feed into a new loss layer for making predictions about speech.
Baidu’s Deep Speech neural network offers a jump start for speech-to-text models, for example, allowing an opportunity to use transfer learning to bake in special speech features.
Why Transfer Learning?
Transfer learning is useful when you have insufficient data for a new domain you want handled by a neural network and there is a big pre-existing data pool that can be transferred to your problem.
So you might have only 1,000 images of horses, but by tapping into an existing CNN such as ResNet, trained with more than 1 million images, you can gain a lot of low-level and mid-level feature definitions.
For developers and data scientists interested in accelerating their AI training workflow with transfer learning capabilities, the NVIDIA TAO Toolkit offers GPU-accelerated pre-trained models and functions to fine-tune your model for various domains such as intelligent video analytics and medical imaging.
Pretrained models are available on NVIDIA NGC, making high-performing AI development easy, quick and accessible by applying concepts of transfer learning and helping to minimize model building from scratch.
And when it’s time for deployment, you can roll out your application with an end-to-end deep learning workflow using TAO Toolkit for IVA and medical imaging.
Plus, with just a few online courses, you could become your company’s expert — and launch yourself into an entirely new career path.