Skip to content
Artificial Intelligence Computing Leadership from NVIDIA
Search for:
Toggle Search
Home
AI
Data Center
Driving
Gaming
Pro Graphics
Robotics
Healthcare
Startups
AI Podcast
NVIDIA Life
Tag:
Telecommunications
Indonesia on Track to Achieve Sovereign AI Goals With NVIDIA, Cisco and IOH
NVIDIA and Deutsche Telekom Partner to Advance Germany’s Sovereign AI
Calling on LLMs: New NVIDIA AI Blueprint Helps Automate Telco Network Configuration
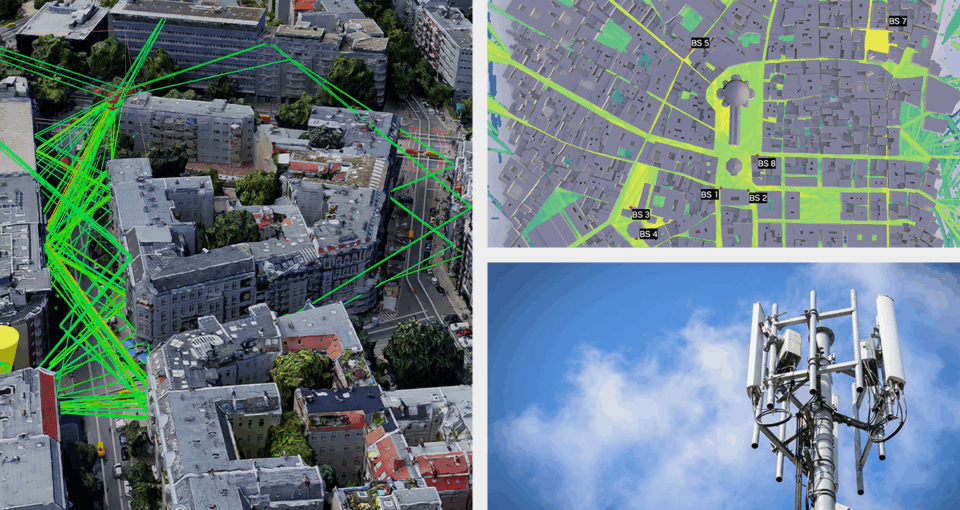
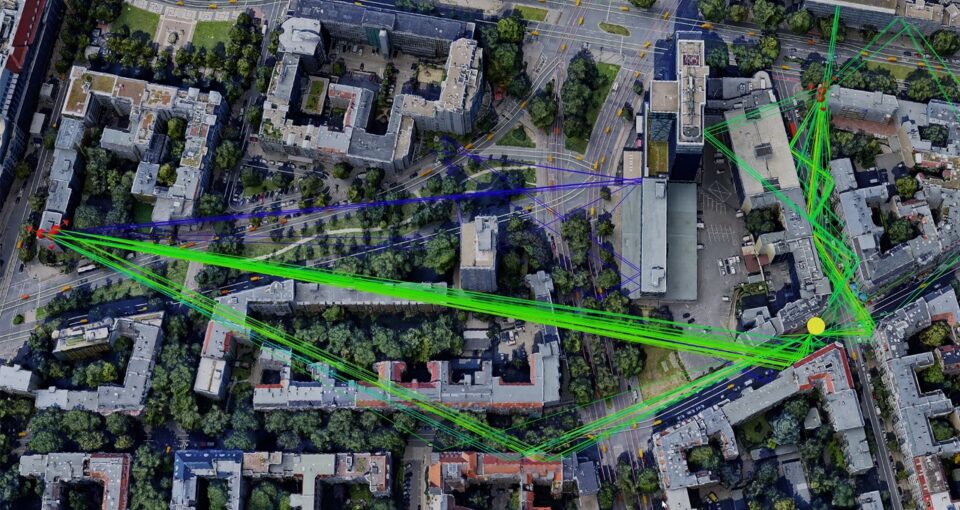
European Researchers Develop AI-Native Wireless Networks With NVIDIA 6G Research Portfolio
France Bolsters National AI Strategy With NVIDIA Infrastructure
Leading European Telcos Build AI Infrastructure With NVIDIA for Regional Enterprises
NVIDIA Aerial Expands With New Tools for Building AI-Native Wireless Networks
Telecom Leaders Call Up Agentic AI to Improve Network Operations
Telcos Dial Up AI: NVIDIA Survey Unveils Industry’s AI Trends
Load More Articles
Share This
Facebook
LinkedIn
Email
Share on Mastodon
Enter your Mastodon instance URL (optional)
Share