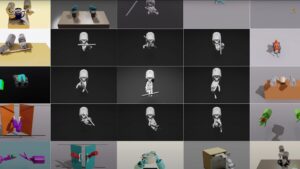
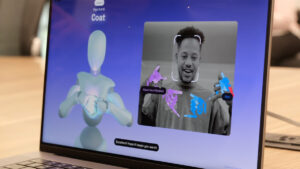
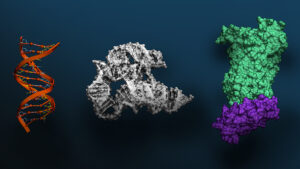
NVIDIA Rubin Platform, Open Models, Autonomous Driving: NVIDIA Presents Blueprint for the Future at CES
NVIDIA founder and CEO Jensen Huang took the stage at the Fontainebleau Las Vegas to open CES 2026, declaring that AI is scaling into every domain and every device. “Computing...