
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and showcases new hardware, software, tools and accelerations for RTX PC users.
Large language models are driving some of the most exciting developments in AI with their ability to quickly understand, summarize and generate text-based content.
These capabilities power a variety of use cases, including productivity tools, digital assistants, non-playable characters in video games and more. But they’re not a one-size-fits-all solution, and developers often must fine-tune LLMs to fit the needs of their applications.
The NVIDIA RTX AI Toolkit makes it easy to fine-tune and deploy AI models on RTX AI PCs and workstations through a technique called low-rank adaptation, or LoRA. A new update, available today, enables support for using multiple LoRA adapters simultaneously within the NVIDIA TensorRT-LLM AI acceleration library, improving the performance of fine-tuned models by up to 6x.
Fine-Tuned for Performance
LLMs must be carefully customized to achieve higher performance and meet growing user demands.
These foundational models are trained on huge amounts of data but often lack the context needed for a developer’s specific use case. For example, a generic LLM can generate video game dialogue, but it will likely miss the nuance and subtlety needed to write in the style of a woodland elf with a dark past and a barely concealed disdain for authority.
To achieve more tailored outputs, developers can fine-tune the model with information related to the app’s use case.
Take the example of developing an app to generate in-game dialogue using an LLM. The process of fine-tuning starts with using the weights of a pretrained model, such as information on what a character may say in the game. To get the dialogue in the right style, a developer can tune the model on a smaller dataset of examples, such as dialogue written in a more spooky or villainous tone.
In some cases, developers may want to run all of these different fine-tuning processes simultaneously. For example, they may want to generate marketing copy written in different voices for various content channels. At the same time, they may want to summarize a document and make stylistic suggestions — as well as draft a video game scene description and imagery prompt for a text-to-image generator.
It’s not practical to run multiple models simultaneously, as they won’t all fit in GPU memory at the same time. Even if they did, their inference time would be impacted by memory bandwidth — how fast data can be read from memory into GPUs.
Lo(RA) and Behold
A popular way to address these issues is to use fine-tuning techniques such as low-rank adaptation. A simple way of thinking of it is as a patch file containing the customizations from the fine-tuning process.
Once trained, customized LoRA adapters can integrate seamlessly with the foundation model during inference, adding minimal overhead. Developers can attach the adapters to a single model to serve multiple use cases. This keeps the memory footprint low while still providing the additional details needed for each specific use case.
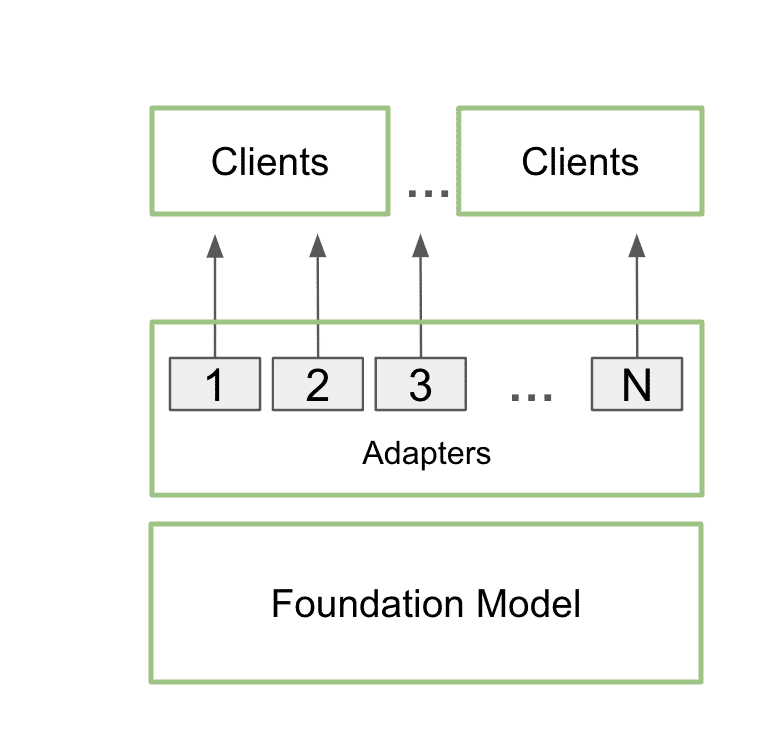
In practice, this means that an app can keep just one copy of the base model in memory, alongside many customizations using multiple LoRA adapters.
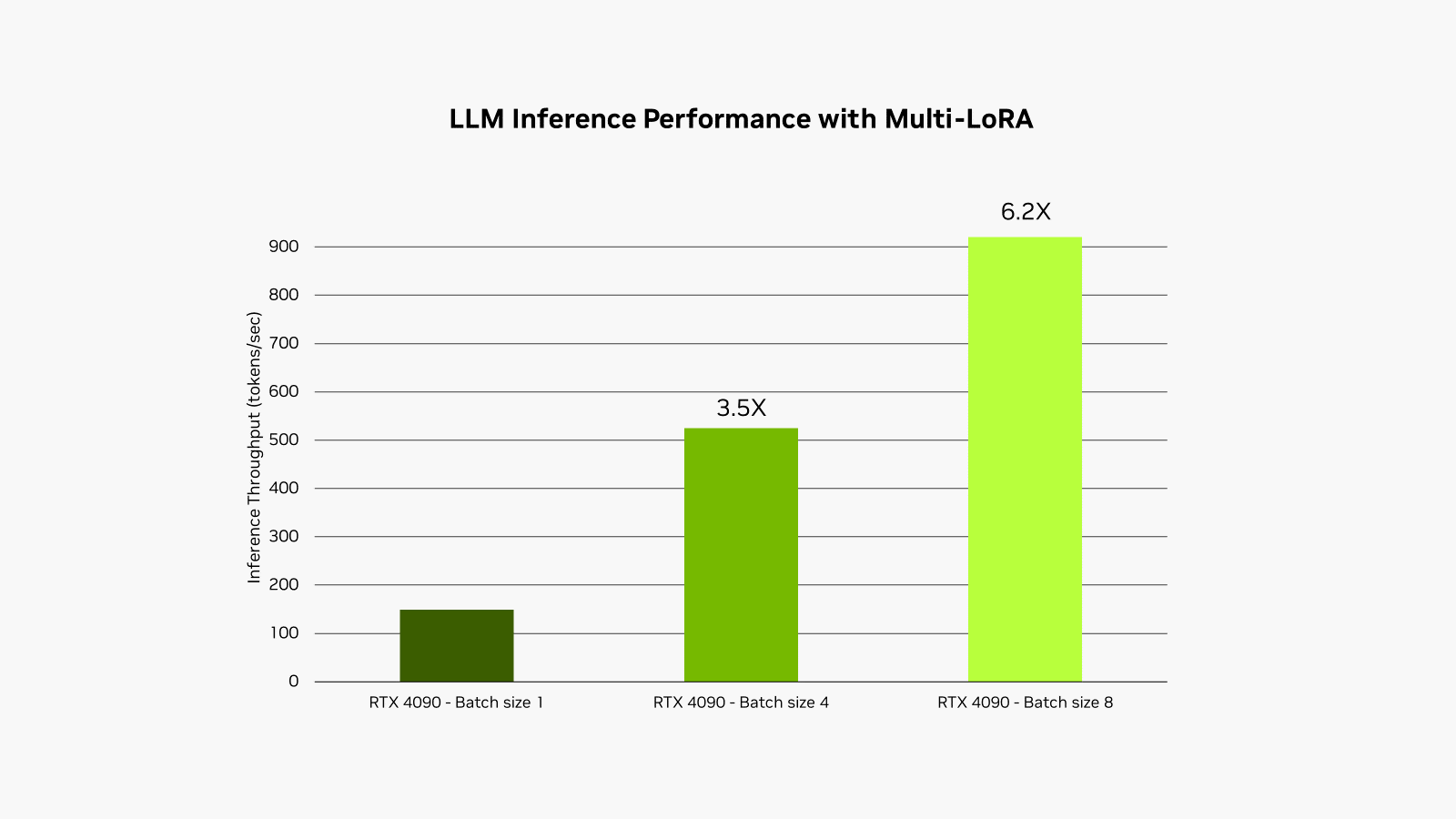
This process is called multi-LoRA serving. When multiple calls are made to the model, the GPU can process all of the calls in parallel, maximizing the use of its Tensor Cores and minimizing the demands of memory and bandwidth so developers can efficiently use AI models in their workflows. Fine-tuned models using multi-LoRA adapters perform up to 6x faster.
In the example of the in-game dialogue application described earlier, the app’s scope could be expanded, using multi-LoRA serving, to generate both story elements and illustrations — driven by a single prompt.
The user could input a basic story idea, and the LLM would flesh out the concept, expanding on the idea to provide a detailed foundation. The application could then use the same model, enhanced with two distinct LoRA adapters, to refine the story and generate corresponding imagery. One LoRA adapter generates a Stable Diffusion prompt to create visuals using a locally deployed Stable Diffusion XL model. Meanwhile, the other LoRA adapter, fine-tuned for story writing, could craft a well-structured and engaging narrative.
In this case, the same model is used for both inference passes, ensuring that the space required for the process doesn’t significantly increase. The second pass, which involves both text and image generation, is performed using batched inference, making the process exceptionally fast and efficient on NVIDIA GPUs. This allows users to rapidly iterate through different versions of their stories, refining the narrative and the illustrations with ease.
This process is outlined in more detail in a recent technical blog.
LLMs are becoming one of the most important components of modern AI. As adoption and integration grows, demand for powerful, fast LLMs with application-specific customizations will only increase. The multi-LoRA support added today to the RTX AI Toolkit gives developers a powerful new way to accelerate these capabilities.