
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and which showcases new hardware, software, tools and accelerations for RTX PC users.
As generative AI advances and becomes widespread across industries, the importance of running generative AI applications on local PCs and workstations grows. Local inference gives consumers reduced latency, eliminates their dependency on the network and enables more control over their data.
NVIDIA GeForce and NVIDIA RTX GPUs feature Tensor Cores, dedicated AI hardware accelerators that provide the horsepower to run generative AI locally.
Stable Video Diffusion is now optimized for the NVIDIA TensorRT software development kit, which unlocks the highest-performance generative AI on the more than 100 million Windows PCs and workstations powered by RTX GPUs.
Now, the TensorRT extension for the popular Stable Diffusion WebUI by Automatic1111 is adding support for ControlNets, tools that give users more control to refine generative outputs by adding other images as guidance.
TensorRT acceleration can be put to the test in the new UL Procyon AI Image Generation benchmark, which internal tests have shown accurately replicates real-world performance. It delivered speedups of 50% on a GeForce RTX 4080 SUPER GPU compared with the fastest non-TensorRT implementation.
More Efficient and Precise AI
TensorRT enables developers to access the hardware that provides fully optimized AI experiences. AI performance typically doubles compared with running the application on other frameworks.
It also accelerates the most popular generative AI models, like Stable Diffusion and SDXL. Stable Video Diffusion, Stability AI’s image-to-video generative AI model, experiences a 40% speedup with TensorRT.
The optimized Stable Video Diffusion 1.1 Image-to-Video model can be downloaded on Hugging Face.
Plus, the TensorRT extension for Stable Diffusion WebUI boosts performance by up to 2x — significantly streamlining Stable Diffusion workflows.
With the extension’s latest update, TensorRT optimizations extend to ControlNets — a set of AI models that help guide a diffusion model’s output by adding extra conditions. With TensorRT, ControlNets are 40% faster.
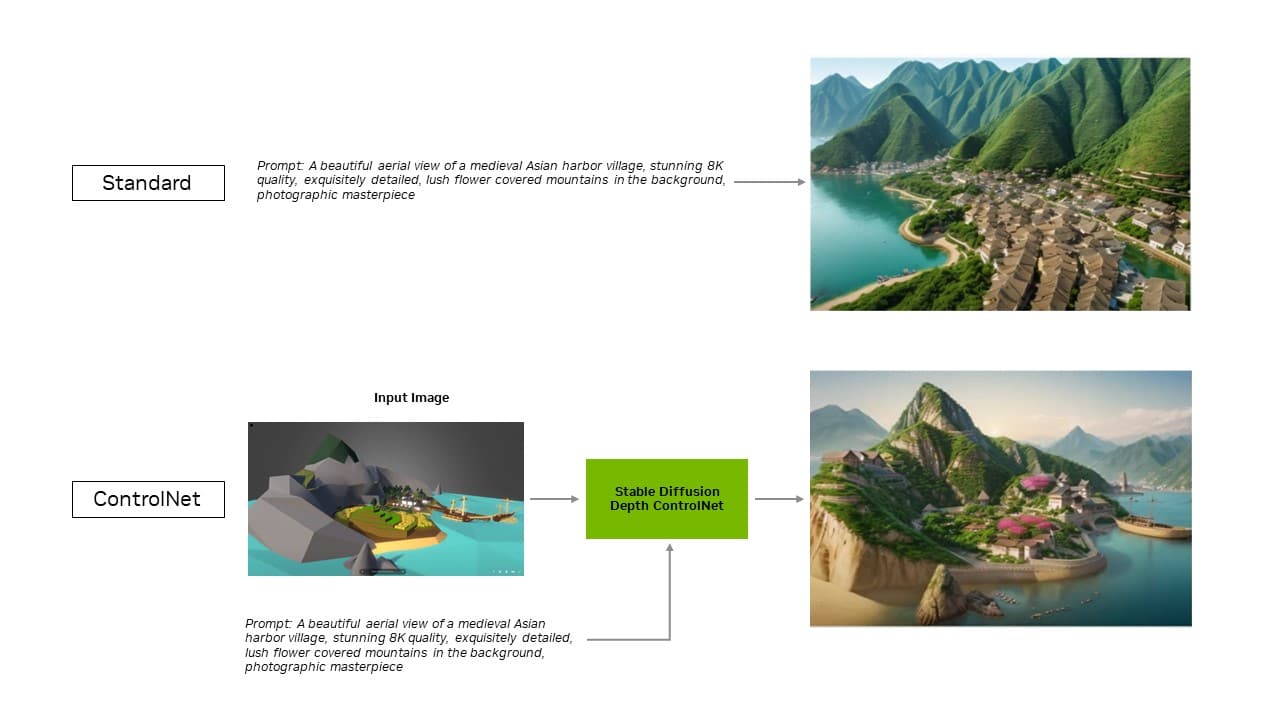
Users can guide aspects of the output to match an input image, which gives them more control over the final image. They can also use multiple ControlNets together for even greater control. A ControlNet can be a depth map, edge map, normal map or keypoint detection model, among others.
Download the TensorRT extension for Stable Diffusion Web UI on GitHub today.
Other Popular Apps Accelerated by TensorRT
Blackmagic Design adopted NVIDIA TensorRT acceleration in update 18.6 of DaVinci Resolve. Its AI tools, like Magic Mask, Speed Warp and Super Scale, run more than 50% faster and up to 2.3x faster on RTX GPUs compared with Macs.
In addition, with TensorRT integration, Topaz Labs saw an up to 60% performance increase in its Photo AI and Video AI apps — such as photo denoising, sharpening, photo super resolution, video slow motion, video super resolution, video stabilization and more — all running on RTX.
Combining Tensor Cores with TensorRT software brings unmatched generative AI performance to local PCs and workstations. And by running locally, several advantages are unlocked:
- Performance: Users experience lower latency, since latency becomes independent of network quality when the entire model runs locally. This can be important for real-time use cases such as gaming or video conferencing. NVIDIA RTX offers the fastest AI accelerators, scaling to more than 1,300 AI trillion operations per second, or TOPS.
- Cost: Users don’t have to pay for cloud services, cloud-hosted application programming interfaces or infrastructure costs for large language model inference.
- Always on: Users can access LLM capabilities anywhere they go, without relying on high-bandwidth network connectivity.
- Data privacy: Private and proprietary data can always stay on the user’s device.
Optimized for LLMs
What TensorRT brings to deep learning, NVIDIA TensorRT-LLM brings to the latest LLMs.
TensorRT-LLM, an open-source library that accelerates and optimizes LLM inference, includes out-of-the-box support for popular community models, including Phi-2, Llama2, Gemma, Mistral and Code Llama. Anyone — from developers and creators to enterprise employees and casual users — can experiment with TensorRT-LLM-optimized models in the NVIDIA AI Foundation models. Plus, with the NVIDIA ChatRTX tech demo, users can see the performance of various models running locally on a Windows PC. ChatRTX is built on TensorRT-LLM for optimized performance on RTX GPUs.
NVIDIA is collaborating with the open-source community to develop native TensorRT-LLM connectors to popular application frameworks, including LlamaIndex and LangChain.
These innovations make it easy for developers to use TensorRT-LLM with their applications and experience the best LLM performance with RTX.
Get weekly updates directly in your inbox by subscribing to the AI Decoded newsletter.

