
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible and showcases new hardware, software, tools and accelerations for NVIDIA RTX PC and workstation users.
The demand for tools to simplify and optimize generative AI development is skyrocketing. Applications based on retrieval-augmented generation (RAG) — a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from specified external sources — and customized models are enabling developers to tune AI models to their specific needs.
While such work may have required a complex setup in the past, new tools are making it easier than ever.
NVIDIA AI Workbench simplifies AI developer workflows by helping users build their own RAG projects, customize models and more. It’s part of the RTX AI Toolkit — a suite of tools and software development kits for customizing, optimizing and deploying AI capabilities — launched at COMPUTEX earlier this month. AI Workbench removes the complexity of technical tasks that can derail experts and halt beginners.
What Is NVIDIA AI Workbench?
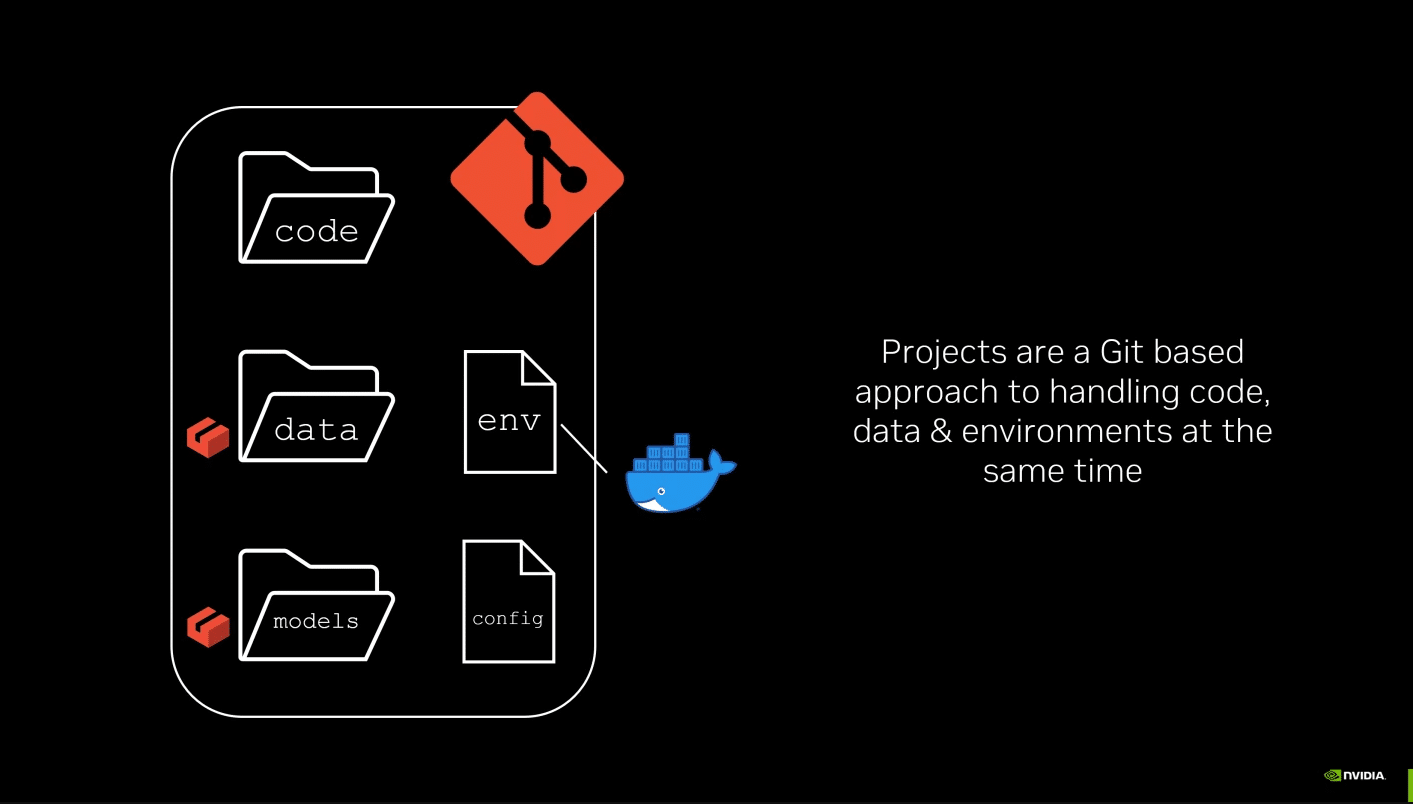
Available for free, NVIDIA AI Workbench enables users to develop, experiment with, test and prototype AI applications across GPU systems of their choice — from laptops and workstations to data center and cloud. It offers a new approach for creating, using and sharing GPU-enabled development environments across people and systems.
A simple installation gets users up and running with AI Workbench on a local or remote machine in just minutes. Users can then start a new project or replicate one from the examples on GitHub. Everything works through GitHub or GitLab, so users can easily collaborate and distribute work. Learn more about getting started with AI Workbench.
How AI Workbench Helps Address AI Project Challenges
Developing AI workloads can require manual, often complex processes, right from the start.
Setting up GPUs, updating drivers and managing versioning incompatibilities can be cumbersome. Reproducing projects across different systems can require replicating manual processes over and over. Inconsistencies when replicating projects, like issues with data fragmentation and version control, can hinder collaboration. Varied setup processes, moving credentials and secrets, and changes in the environment, data, models and file locations can all limit the portability of projects.
AI Workbench makes it easier for data scientists and developers to manage their work and collaborate across heterogeneous platforms. It integrates and automates various aspects of the development process, offering:
- Ease of setup: AI Workbench streamlines the process of setting up a developer environment that’s GPU-accelerated, even for users with limited technical knowledge.
- Seamless collaboration: AI Workbench integrates with version-control and project-management tools like GitHub and GitLab, reducing friction when collaborating.
- Consistency when scaling from local to cloud: AI Workbench ensures consistency across multiple environments, supporting scaling up or down from local workstations or PCs to data centers or the cloud.
RAG for Documents, Easier Than Ever
NVIDIA offers sample development Workbench Projects to help users get started with AI Workbench. The hybrid RAG Workbench Project is one example: It runs a custom, text-based RAG web application with a user’s documents on their local workstation, PC or remote system.
Every Workbench Project runs in a “container” — software that includes all the necessary components to run the AI application. The hybrid RAG sample pairs a Gradio chat interface frontend on the host machine with a containerized RAG server — the backend that services a user’s request and routes queries to and from the vector database and the selected large language model.
This Workbench Project supports a wide variety of LLMs available on NVIDIA’s GitHub page. Plus, the hybrid nature of the project lets users select where to run inference.
Developers can run the embedding model on the host machine and run inference locally on a Hugging Face Text Generation Inference server, on target cloud resources using NVIDIA inference endpoints like the NVIDIA API catalog, or with self-hosting microservices such as NVIDIA NIM or third-party services.
The hybrid RAG Workbench Project also includes:
- Performance metrics: Users can evaluate how RAG- and non-RAG-based user queries perform across each inference mode. Tracked metrics include Retrieval Time, Time to First Token (TTFT) and Token Velocity.
- Retrieval transparency: A panel shows the exact snippets of text — retrieved from the most contextually relevant content in the vector database — that are being fed into the LLM and improving the response’s relevance to a user’s query.
- Response customization: Responses can be tweaked with a variety of parameters, such as maximum tokens to generate, temperature and frequency penalty.
To get started with this project, simply install AI Workbench on a local system. The hybrid RAG Workbench Project can be brought from GitHub into the user’s account and duplicated to the local system.
More resources are available in the AI Decoded user guide. In addition, community members provide helpful video tutorials, like the one from Joe Freeman below.
Customize, Optimize, Deploy
Developers often seek to customize AI models for specific use cases. Fine-tuning, a technique that changes the model by training it with additional data, can be useful for style transfer or changing model behavior. AI Workbench helps with fine-tuning, as well.
The Llama-factory AI Workbench Project enables QLoRa, a fine-tuning method that minimizes memory requirements, for a variety of models, as well as model quantization via a simple graphical user interface. Developers can use public or their own datasets to meet the needs of their applications.
Once fine-tuning is complete, the model can be quantized for improved performance and a smaller memory footprint, then deployed to native Windows applications for local inference or to NVIDIA NIM for cloud inference. Find a complete tutorial for this project on the NVIDIA RTX AI Toolkit repository.
Truly Hybrid — Run AI Workloads Anywhere
The Hybrid-RAG Workbench Project described above is hybrid in more than one way. In addition to offering a choice of inference mode, the project can be run locally on NVIDIA RTX workstations and GeForce RTX PCs, or scaled up to remote cloud servers and data centers.
The ability to run projects on systems of the user’s choice — without the overhead of setting up the infrastructure — extends to all Workbench Projects. Find more examples and instructions for fine-tuning and customization in the AI Workbench quick-start guide.
For a more technical perspective, read the blog Optimize AI Model Performance and Maintain Data Privacy with Hybrid RAG.
Generative AI is transforming gaming, videoconferencing and interactive experiences of all kinds. Make sense of what’s new and what’s next by subscribing to the AI Decoded newsletter.