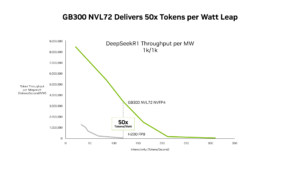


Advancing Open Source AI, NVIDIA Donates Dynamic Resource Allocation Driver for GPUs to Kubernetes Community
Artificial intelligence has rapidly emerged as one of the most critical workloads in modern computing. For the vast majority of enterprises, this workload runs on Kubernetes, an open source platform...