What you can see, you can understand.
Simulations help us understand the mysteries of black holes and see how a protein spike on the coronavirus causes COVID-19. They also let designers create everything from sleek cars to jet engines.
But simulations are also among the most demanding computer applications on the planet because they require lots of the most advanced math.
Simulations make numeric models visual with calculations that use a double-precision floating-point format called FP64. Each number in the format takes up 64 bits inside a computer, making it one the most computationally intensive of the many math formats today’s GPUs support.
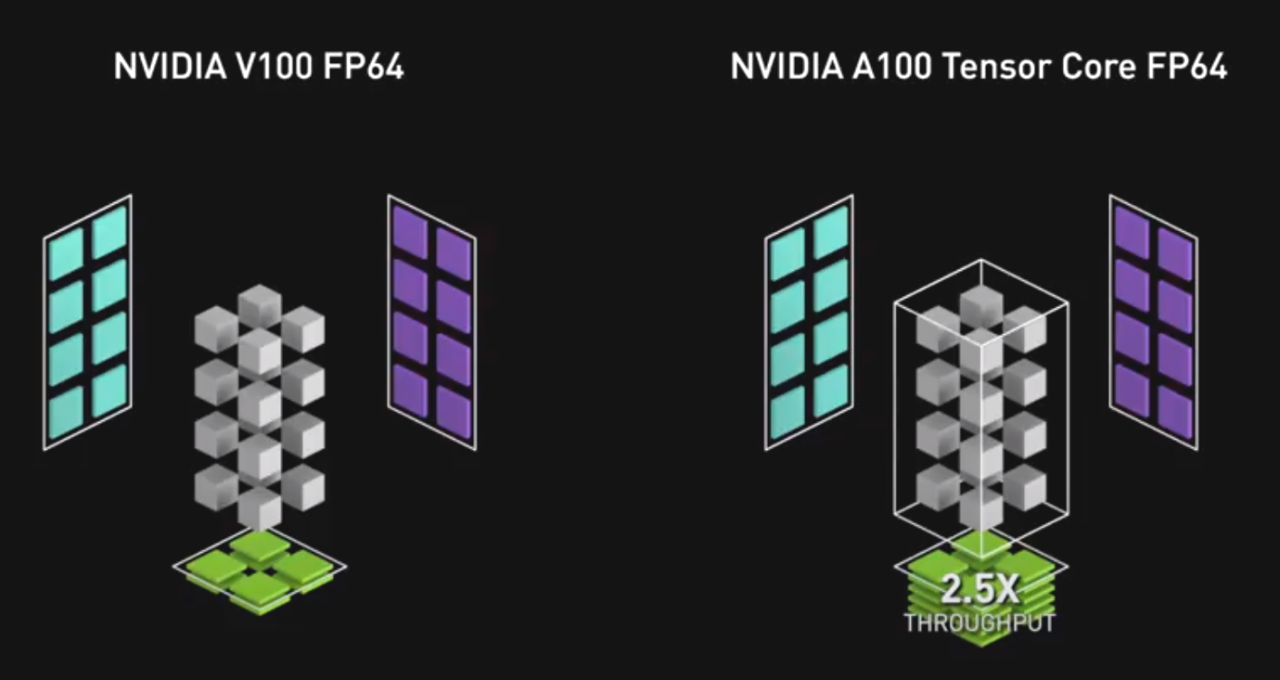
As the next big step in our efforts to accelerate high performance computing, the NVIDIA Ampere architecture defines third-generation Tensor Cores that accelerate FP64 math by 2.5x compared to last-generation GPUs.
That means simulations that kept researchers and designers waiting overnight can be viewed in a few hours when run on the latest A100 GPUs.
Science Puts AI in the Loop
The speed gains open a door for combining AI with simulations and experiments, creating a positive-feedback loop that saves time.
First, a simulation creates a dataset that trains an AI model. Then the AI and simulation models run together, feeding off each other’s strengths until the AI model is ready to deliver real-time results through inference. The trained AI model also can take in data from an experiment or sensor, further refining its insights.
Using this technique, AI can define a few areas of interest for conducting high-resolution simulations. By narrowing the field, AI can slash by orders of magnitude the need for thousands of time-consuming simulations. And the simulations that need to be run will run 2.5x faster on an A100 GPU.
With FP64 and other new features, the A100 GPUs based on the NVIDIA Ampere architecture become a flexible platform for simulations, as well as AI inference and training — the entire workflow for modern HPC. That capability will drive developers to migrate simulation codes to the A100.
Users can call new CUDA-X libraries to access FP64 acceleration in the A100. Under the hood, these GPUs are packed with third-generation Tensor Cores that support DMMA, a new mode that accelerates double-precision matrix multiply-accumulate operations.
Accelerating Matrix Math
A single DMMA job uses one computer instruction to replace eight traditional FP64 instructions. As a result, the A100 crunches FP64 math faster than other chips with less work, saving not only time and power but precious memory and I/O bandwidth as well.
We refer to this new capability as Double-Precision Tensor Cores. It delivers the power of Tensor Cores to HPC applications, accelerating matrix math in full FP64 precision.
Beyond simulations, HPC apps called iterative solvers — algorithms with repetitive matrix-math calculations — will benefit from this new capability. These apps include a wide range of jobs in earth science, fluid dynamics, healthcare, material science and nuclear energy as well as oil and gas exploration.
To serve the world’s most demanding applications, Double-Precision Tensor Cores arrive inside the largest and most powerful GPU we’ve ever made. The A100 also packs more memory and bandwidth than any GPU on the planet.
The third-generation Tensor Cores in the NVIDIA Ampere architecture are beefier than prior versions. They support a larger matrix size — 8x8x4, compared to 4x4x4 for Volta — that lets users tackle tougher problems.
That’s one reason why an A100 with a total of 432 Tensor Cores delivers up to 19.5 FP64 TFLOPS, more than double the performance of a Volta V100.
Where to Go to Learn More
To get the big picture on the role of FP64 in our latest GPUs, watch the keynote with NVIDIA founder and CEO Jensen Huang. To learn more, register for the webinar or read a detailed article that takes a deep dive into the NVIDIA Ampere architecture.
Double-Precision Tensor Cores are among a battery of new capabilities in the NVIDIA Ampere architecture, driving HPC performance as well as AI training and inference to new heights. For more details, check out our blogs on:


