
NVIDIA today announced Nemotron-4 340B, a family of open models that developers can use to generate synthetic data for training large language models (LLMs) for commercial applications across healthcare, finance, manufacturing, retail and every other industry.
High-quality training data plays a critical role in the performance, accuracy and quality of responses from a custom LLM — but robust datasets can be prohibitively expensive and difficult to access.
Through a uniquely permissive open model license, Nemotron-4 340B gives developers a free, scalable way to generate synthetic data that can help build powerful LLMs.
The Nemotron-4 340B family includes base, instruct and reward models that form a pipeline to generate synthetic data used for training and refining LLMs. The models are optimized to work with NVIDIA NeMo, an open-source framework for end-to-end model training, including data curation, customization and evaluation. They’re also optimized for inference with the open-source NVIDIA TensorRT-LLM library.
Nemotron-4 340B can be downloaded now from the NVIDIA NGC catalog and from Hugging Face, where developers can also use the Train on DGX Cloud service to easily fine-tune open AI models. Developers will soon be able to access the models at ai.nvidia.com, where they’ll be packaged as an NVIDIA NIM microservice with a standard application programming interface that can be deployed anywhere.
Navigating Nemotron to Generate Synthetic Data
LLMs can help developers generate synthetic training data in scenarios where access to large, diverse labeled datasets is limited.
The Nemotron-4 340B Instruct model creates diverse synthetic data that mimics the characteristics of real-world data, helping improve data quality to increase the performance and robustness of custom LLMs across various domains.
Then, to boost the quality of the AI-generated data, developers can use the Nemotron-4 340B Reward model to filter for high-quality responses. Nemotron-4 340B Reward grades responses on five attributes: helpfulness, correctness, coherence, complexity and verbosity. It’s currently first place on the Hugging Face RewardBench leaderboard, created by AI2, for evaluating the capabilities, safety and pitfalls of reward models.
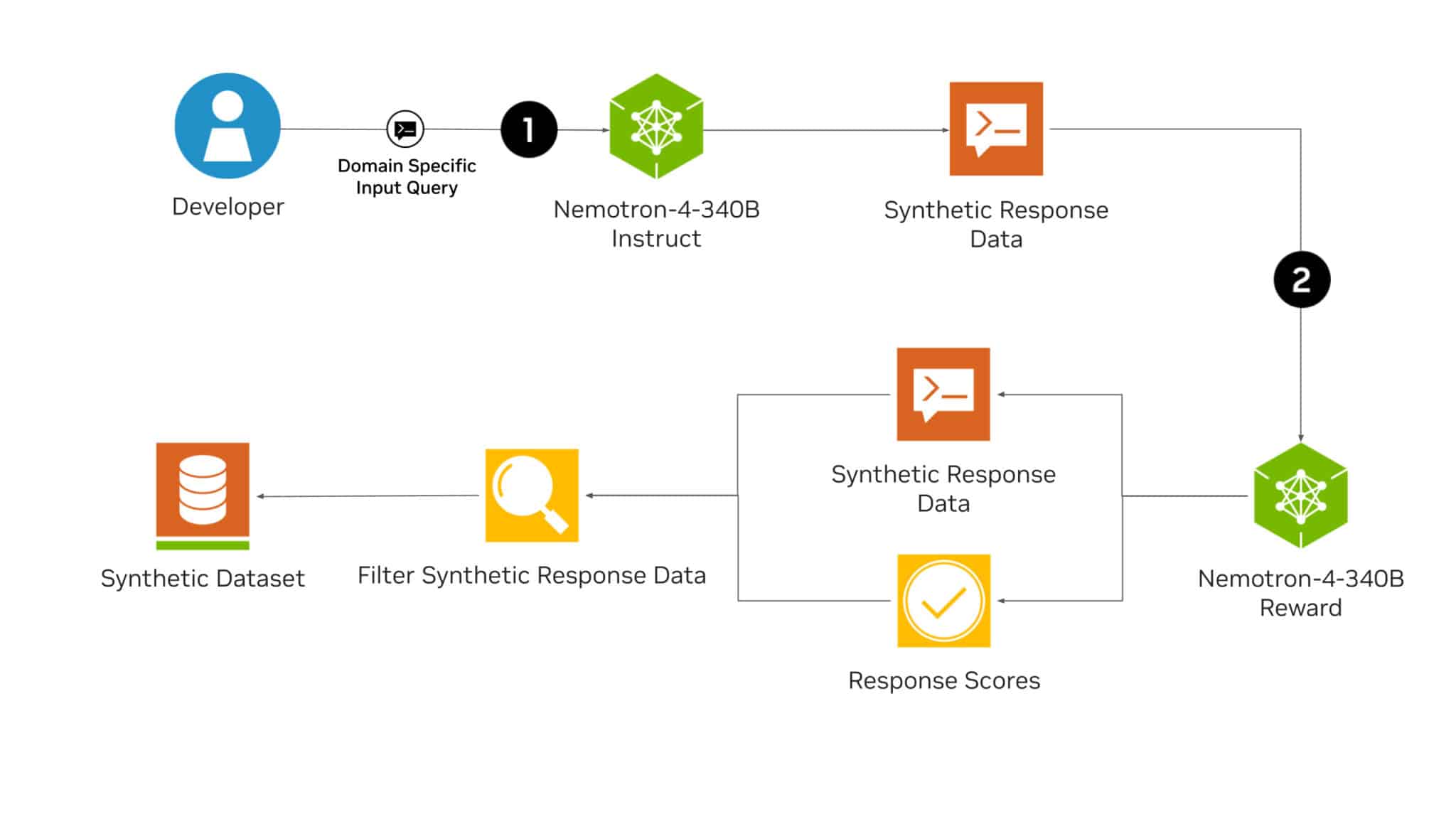
Researchers can also create their own instruct or reward models by customizing the Nemotron-4 340B Base model using their proprietary data, combined with the included HelpSteer2 dataset.
Fine-Tuning With NeMo, Optimizing for Inference With TensorRT-LLM
Using open-source NVIDIA NeMo and NVIDIA TensorRT-LLM, developers can optimize the efficiency of their instruct and reward models to generate synthetic data and to score responses.
All Nemotron-4 340B models are optimized with TensorRT-LLM to take advantage of tensor parallelism, a type of model parallelism in which individual weight matrices are split across multiple GPUs and servers, enabling efficient inference at scale.
Nemotron-4 340B Base, trained on 9 trillion tokens, can be customized using the NeMo framework to adapt to specific use cases or domains. This fine-tuning process benefits from extensive pretraining data and yields more accurate outputs for specific downstream tasks.
A variety of customization methods are available through the NeMo framework, including supervised fine-tuning and parameter-efficient fine-tuning methods such as low-rank adaptation, or LoRA.
To boost model quality, developers can align their models with NeMo Aligner and datasets annotated by Nemotron-4 340B Reward. Alignment is a key step in training LLMs, where a model’s behavior is fine-tuned using algorithms like reinforcement learning from human feedback (RLHF) to ensure its outputs are safe, accurate, contextually appropriate and consistent with its intended goals.
Businesses seeking enterprise-grade support and security for production environments can also access NeMo and TensorRT-LLM through the cloud-native NVIDIA AI Enterprise software platform, which provides accelerated and efficient runtimes for generative AI foundation models.
Evaluating Model Security and Getting Started
The Nemotron-4 340B Instruct model underwent extensive safety evaluation, including adversarial tests, and performed well across a wide range of risk indicators. Users should still perform careful evaluation of the model’s outputs to ensure the synthetically generated data is suitable, safe and accurate for their use case.
For more information on model security and safety evaluation, read the model card.
Download Nemotron-4 340B models via NVIDIA NGC and Hugging Face. For more details, read the research papers on the model and dataset.
See notice regarding software product information.