To speed up AI adoption across industries, HPE and NVIDIA today launched new AI factory offerings at HPE… Read Article
To speed up AI adoption across industries, HPE and NVIDIA today launched new AI factory offerings at HPE… Read Article
Industrial AI isn’t slowing down. Germany is ready. Following London Tech Week and GTC Paris at VivaTech, NVIDIA founder and CEO Jensen Huang’s European tour continued with a stop in… Read Article
At GTC Paris — held alongside VivaTech, Europe’s largest tech event — NVIDIA founder and CEO Jensen Huang delivered a clear message: Europe isn’t just adopting AI — it’s building… Read Article
In a new effort to advance sovereign AI for European public service media, NVIDIA and the European Broadcasting Union (EBU) are working together to give the media industry access to… Read Article
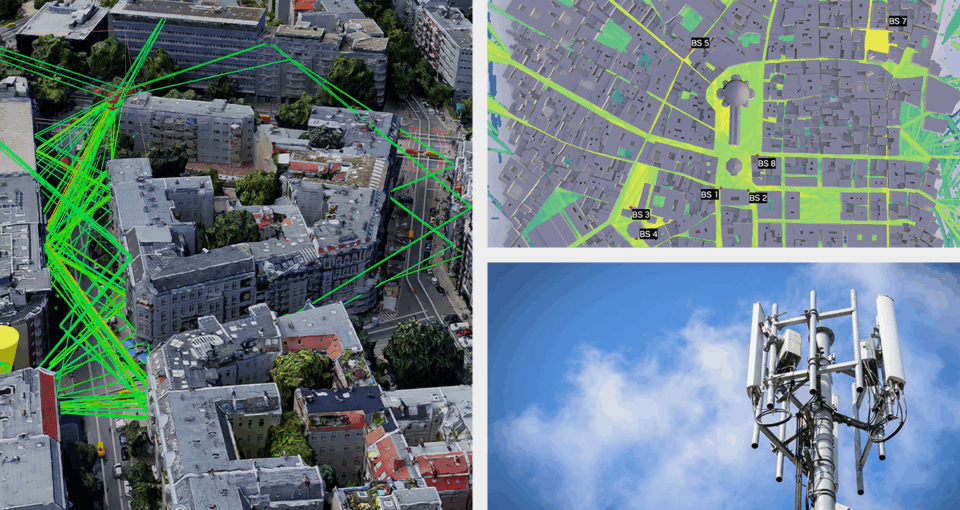
Telecom companies last year spent nearly $295 billion in capital expenditures and over $1 trillion in operating expenditures. These large expenses are due in part to laborious manual processes that… Read Article
Urban populations are expected to double by 2050, which means around 2.5 billion people could be added to urban areas by the middle of the century, driving the need for… Read Article
Using NVIDIA platforms, tools and libraries, European telecommunications institutions are accelerating efforts to develop 6G — the next generation of cellular technology, with AI woven in from the start. 6G… Read Article
Autonomous vehicle (AV) stacks are evolving from many distinct models to a unified, end-to-end architecture that executes driving actions directly from sensor data. This transition to using larger models is… Read Article
AI supercomputing is accelerating the development of new quantum applications, driving breakthroughs in critical industries such as aerospace, automotive and manufacturing. Underscoring that opportunity, Ansys announced today it is using… Read Article