Many users want to run large language models (LLMs) locally for more privacy and control, and without subscriptions, but until recently, this meant a trade-off in output quality. Newly released open-weight models, like OpenAI’s gpt-oss and Alibaba’s Qwen 3, can run directly on PCs, delivering useful high-quality outputs, especially for local agentic AI.
This opens up new opportunities for students, hobbyists and developers to explore generative AI applications locally. NVIDIA RTX PCs accelerate these experiences, delivering fast and snappy AI to users.
Getting Started With Local LLMs Optimized for RTX PCs
NVIDIA has worked to optimize top LLM applications for RTX PCs, extracting maximum performance of Tensor Cores in RTX GPUs.
One of the easiest ways to get started with AI on a PC is with Ollama, an open-source tool that provides a simple interface for running and interacting with LLMs. It supports the ability to drag and drop PDFs into prompts, conversational chat and multimodal understanding workflows that include text and images.
NVIDIA has collaborated with Ollama to improve its performance and user experience on GeForce RTX GPUs. The most recent developments include:
- 50% performance improvements on OpenAI’s gpt-oss-20B model
- 60% performance improvements on the new Gemma 3 270M and EmbeddingGemma models for hyper-efficient RAG
- Improved model scheduling system to maximize and accurately report memory utilization
- Stability enhancements to reduce the number of crashes
Ollama is a developer framework that can be used with other applications. For example, AnythingLLM — an open-source app that lets users build their own AI assistants powered by any LLM — can run on top of Ollama and benefit from all of its accelerations.
Enthusiasts can also get started with local LLMs using LM Studio, an app powered by the popular llama.cpp framework. The app provides a user-friendly interface for running models locally, letting users load different LLMs, chat with them in real time and even serve them as local application programming interface endpoints for integration into custom projects.
NVIDIA has worked with llama.cpp to optimize performance on NVIDIA RTX GPUs. The latest updates include:
- Support for the latest NVIDIA Nemotron Nano v2 9B model, which is based on the novel hybrid-mamba architecture
- Flash Attention now turned on by default, offering an up to 20% performance improvement compared with Flash Attention being turned off
- CUDA kernels optimizations for RMS Norm and fast-div based modulo, resulting in up to 9% performance improvements for popular model
- Semantic versioning, making it easy for developers to adopt future releases
Learn more about gpt-oss on RTX and how NVIDIA has worked with LM Studio to accelerate LLM performance on RTX PCs.
Creating an AI-Powered Study Buddy With AnythingLLM
In addition to greater privacy and performance, running LLMs locally removes restrictions on how many files can be loaded or how long they stay available, enabling context-aware AI conversations for a longer period of time. This creates more flexibility for building conversational and generative AI-powered assistants.
For students, managing a flood of slides, notes, labs and past exams can be overwhelming. Local LLMs make it possible to create a personal tutor that can adapt to individual learning needs.
The demo below shows how students can use local LLMs to build a generative-AI powered assistant:
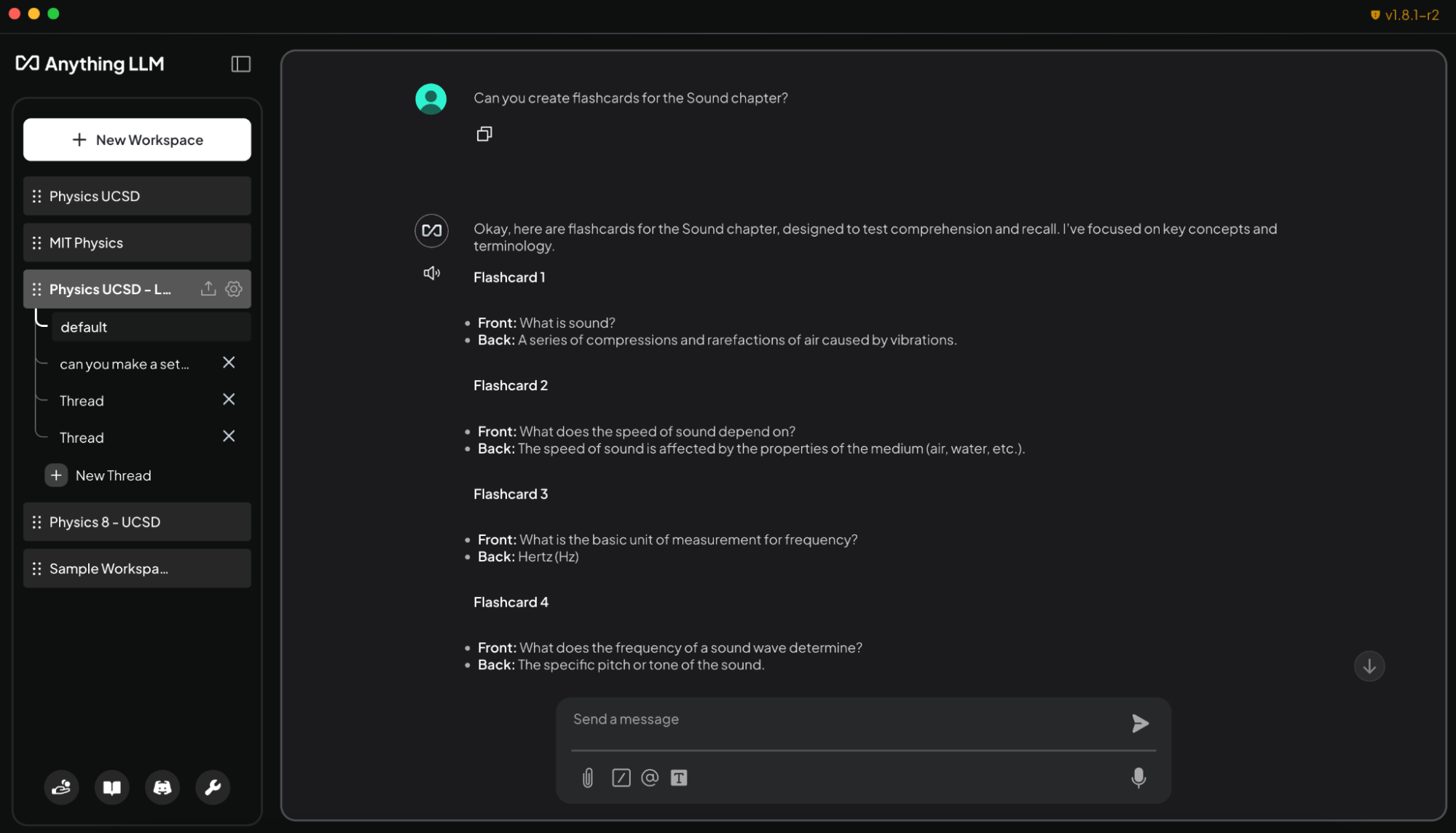
A simple way to do this is with AnythingLLM, which supports document uploads, custom knowledge bases and conversational interfaces. This makes it a flexible tool for anyone who wants to create a customizable AI to help with research, projects or day-to-day tasks. And with RTX acceleration, users can experience even faster responses.
By loading syllabi, assignments and textbooks into AnythingLLM on RTX PCs, students can gain an adaptive, interactive study companion. They can ask the agent, using plain text or speech, to help with tasks like:
- Generating flashcards from lecture slides: “Create flashcards from the Sound chapter lecture slides. Put key terms on one side and definitions on the other.”
- Asking contextual questions tied to their materials: “Explain conservation of momentum using my Physics 8 notes.”
- Creating and grading quizzes for exam prep: “Create a 10-question multiple choice quiz based on chapters 5-6 of my chemistry textbook and grade my answers.”
- Walking through tough problems step by step: “Show me how to solve problem 4 from my coding homework, step by step.”
Beyond the classroom, hobbyists and professionals can use AnythingLLM to prepare for certifications in new fields of study or for other similar purposes. And running locally on RTX GPUs ensures fast, private responses with no subscription costs or usage limits.
Project G-Assist Can Now Control Laptop Settings
Project G-Assist is an experimental AI assistant that helps users tune, control and optimize their gaming PCs through simple voice or text commands — without needing to dig through menus. Over the next day, a new G-Assist update will roll out via the home page of the NVIDIA App.
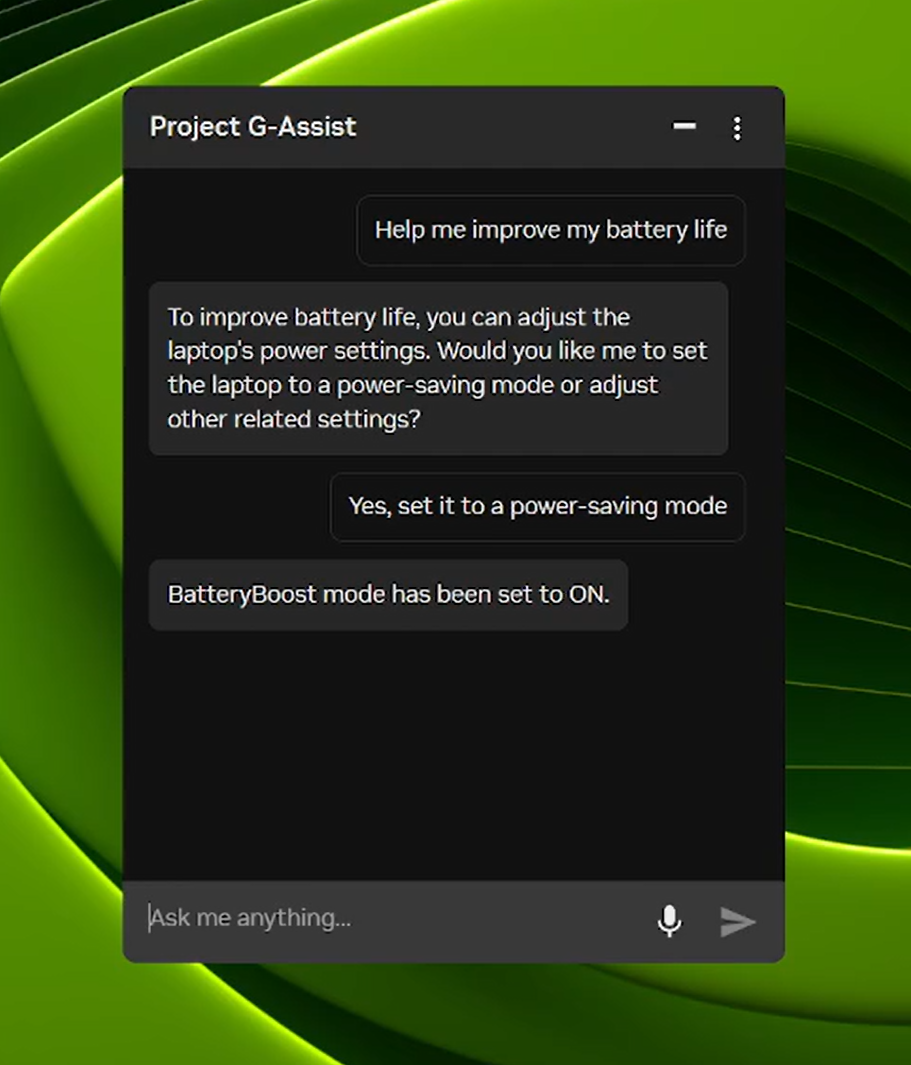
Building on its new, more efficient AI model and support for the majority of RTX GPUs released in August, the new G-Assist update adds commands to adjust laptop settings, including:
- App profiles optimized for laptops: Automatically adjust games or apps for efficiency, quality or a balance when laptops aren’t connected to chargers.
- BatteryBoost control: Activate or adjust BatteryBoost to extend battery life while keeping frame rates smooth.
- WhisperMode control: Cut fan noise by up to 50% when needed, and go back to full performance when not.
Project G-Assist is also extensible. With the G-Assist Plug-In Builder, users can create and customize G-Assist functionality by adding new commands or connecting external tools with easy-to-create plugins. And with the G-Assist Plug-In Hub, users can easily discover and install plug-ins to expand G-Assist capabilities.
Check out NVIDIA’s G-Assist GitHub repository for materials on how to get started, including sample plug-ins, step-by-step instructions and documentation for building custom functionalities.
#ICYMI — The Latest Advancements in RTX AI PCs
🎉Ollama Gets a Major Performance Boost on RTX
Latest updates include optimized performance for OpenAI’s gpt-oss-20B, faster Gemma 3 models and smarter model scheduling to reduce memory issues and improve multi-GPU efficiency.
🚀 Llama.cpp and GGML Optimized for RTX
The latest updates deliver faster, more efficient inference on RTX GPUs, including support for the NVIDIA Nemotron Nano v2 9B model, Flash Attention enabled by default and CUDA kernel optimizations.
⚡Project G-Assist Update Rolls Out
Download the G-Assist v0.1.18 update via the NVIDIA App. The update features new commands for laptop users and enhanced answer quality.
⚙️ Windows ML With NVIDIA TensorRT for RTX Now Generally Available
Microsoft released Windows ML with NVIDIA TensorRT for RTX acceleration, delivering up to 50% faster inference, streamlined deployment and support for LLMs, diffusion and other model types on Windows 11 PCs.
🌐 NVIDIA Nemotron Powers AI Development
The NVIDIA Nemotron collection of open models, datasets and techniques is fueling innovation in AI, from generalized reasoning to industry-specific applications.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.