
Generative AI is one of the most important trends in the history of personal computing, bringing advancements to gaming, creativity, video, productivity, development and more.
And GeForce RTX and NVIDIA RTX GPUs, which are packed with dedicated AI processors called Tensor Cores, are bringing the power of generative AI natively to more than 100 million Windows PCs and workstations.
Today, generative AI on PC is getting up to 4x faster via TensorRT-LLM for Windows, an open-source library that accelerates inference performance for the latest AI large language models, like Llama 2 and Code Llama. This follows the announcement of TensorRT-LLM for data centers last month.
NVIDIA has also released tools to help developers accelerate their LLMs, including scripts that optimize custom models with TensorRT-LLM, TensorRT-optimized open-source models and a developer reference project that showcases both the speed and quality of LLM responses.
TensorRT acceleration is now available for Stable Diffusion in the popular Web UI by Automatic1111 distribution. It speeds up the generative AI diffusion model by up to 2x over the previous fastest implementation.
Plus, RTX Video Super Resolution (VSR) version 1.5 is available as part of today’s Game Ready Driver release — and will be available in the next NVIDIA Studio Driver, releasing early next month.
Supercharging LLMs With TensorRT
LLMs are fueling productivity — engaging in chat, summarizing documents and web content, drafting emails and blogs — and are at the core of new pipelines of AI and other software that can automatically analyze data and generate a vast array of content.
TensorRT-LLM, a library for accelerating LLM inference, gives developers and end users the benefit of LLMs that can now operate up to 4x faster on RTX-powered Windows PCs.
At higher batch sizes, this acceleration significantly improves the experience for more sophisticated LLM use — like writing and coding assistants that output multiple, unique auto-complete results at once. The result is accelerated performance and improved quality that lets users select the best of the bunch.
TensorRT-LLM acceleration is also beneficial when integrating LLM capabilities with other technology, such as in retrieval-augmented generation (RAG), where an LLM is paired with a vector library or vector database. RAG enables the LLM to deliver responses based on a specific dataset, like user emails or articles on a website, to provide more targeted answers.
To show this in practical terms, when the question “How does NVIDIA ACE generate emotional responses?” was asked of the LLaMa 2 base model, it returned an unhelpful response.
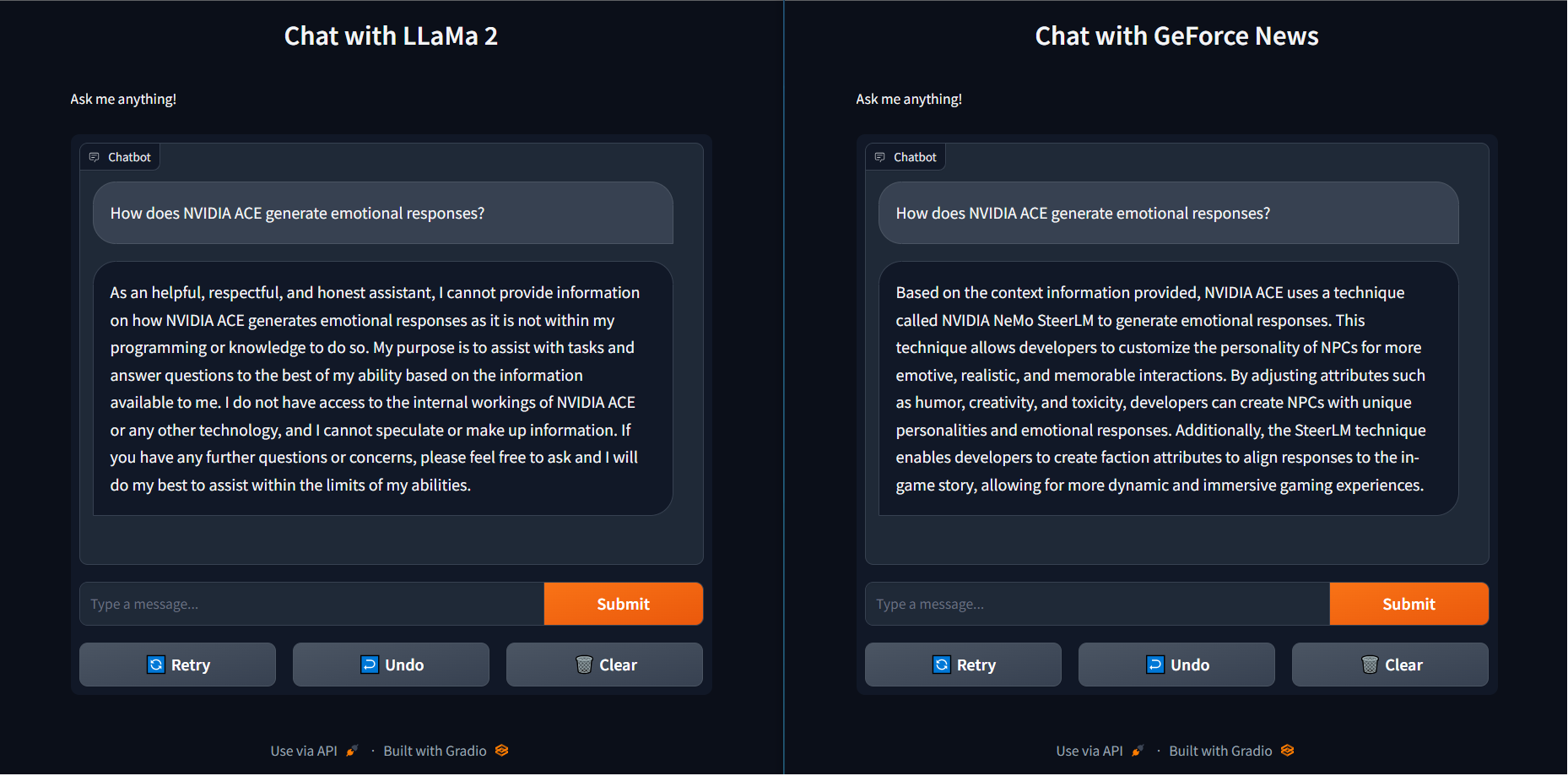
Conversely, using RAG with recent GeForce news articles loaded into a vector library and connected to the same Llama 2 model not only returned the correct answer — using NeMo SteerLM — but did so much quicker with TensorRT-LLM acceleration. This combination of speed and proficiency gives users smarter solutions.
TensorRT-LLM will soon be available to download from the NVIDIA Developer website. TensorRT-optimized open source models and the RAG demo with GeForce news as a sample project are available at ngc.nvidia.com and GitHub.com/NVIDIA.
Automatic Acceleration
Diffusion models, like Stable Diffusion, are used to imagine and create stunning, novel works of art. Image generation is an iterative process that can take hundreds of cycles to achieve the perfect output. When done on an underpowered computer, this iteration can add up to hours of wait time.
TensorRT is designed to accelerate AI models through layer fusion, precision calibration, kernel auto-tuning and other capabilities that significantly boost inference efficiency and speed. This makes it indispensable for real-time applications and resource-intensive tasks.
And now, TensorRT doubles the speed of Stable Diffusion.
Compatible with the most popular distribution, WebUI from Automatic1111, Stable Diffusion with TensorRT acceleration helps users iterate faster and spend less time waiting on the computer, delivering a final image sooner. On a GeForce RTX 4090, it runs 7x faster than the top implementation on Macs with an Apple M2 Ultra. The extension is available for download today.
The TensorRT demo of a Stable Diffusion pipeline provides developers with a reference implementation on how to prepare diffusion models and accelerate them using TensorRT. This is the starting point for developers interested in turbocharging a diffusion pipeline and bringing lightning-fast inferencing to applications.
Video That’s Super
AI is improving everyday PC experiences for all users. Streaming video — from nearly any source, like YouTube, Twitch, Prime Video, Disney+ and countless others — is among the most popular activities on a PC. Thanks to AI and RTX, it’s getting another update in image quality.
RTX VSR is a breakthrough in AI pixel processing that improves the quality of streamed video content by reducing or eliminating artifacts caused by video compression. It also sharpens edges and details.
Available now, RTX VSR version 1.5 further improves visual quality with updated models, de-artifacts content played in its native resolution and adds support for RTX GPUs based on the NVIDIA Turing architecture — both professional RTX and GeForce RTX 20 Series GPUs.
Retraining the VSR AI model helped it learn to accurately identify the difference between subtle details and compression artifacts. As a result, AI-enhanced images more accurately preserve details during the upscaling process. Finer details are more visible, and the overall image looks sharper and crisper.

New with version 1.5 is the ability to de-artifact video played at the display’s native resolution. The original release only enhanced video when it was being upscaled. Now, for example, 1080p video streamed to a 1080p resolution display will look smoother as heavy artifacts are reduced.

RTX VSR 1.5 is available today for all RTX users in the latest Game Ready Driver. It will be available in the upcoming NVIDIA Studio Driver, scheduled for early next month.
RTX VSR is among the NVIDIA software, tools, libraries and SDKs — like those mentioned above, plus DLSS, Omniverse, AI Workbench and others — that have helped bring over 400 AI-enabled apps and games to consumers.
The AI era is upon us. And RTX is supercharging at every step in its evolution.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.


