Editor’s note: This post was updated in October 2025.
School’s in session. That’s how to think about deep neural networks going through the “training” phase. Neural networks, also known as AI models, get an education for the same reason most people do — to learn to do a job. Generative AI models use neural networks to identify the patterns and structures within existing data to generate new and original content.
More specifically, the trained neural network is put to work out in the digital world using what it has learned — to generate code or images, provide healthcare customer support, offer real-time translation, enable AI search across the web and more — in the streamlined form of an application. This speedier and more efficient version of a neural network infers things about new data it’s presented with based on its training. In the AI lexicon, this is known as “AI inference.”
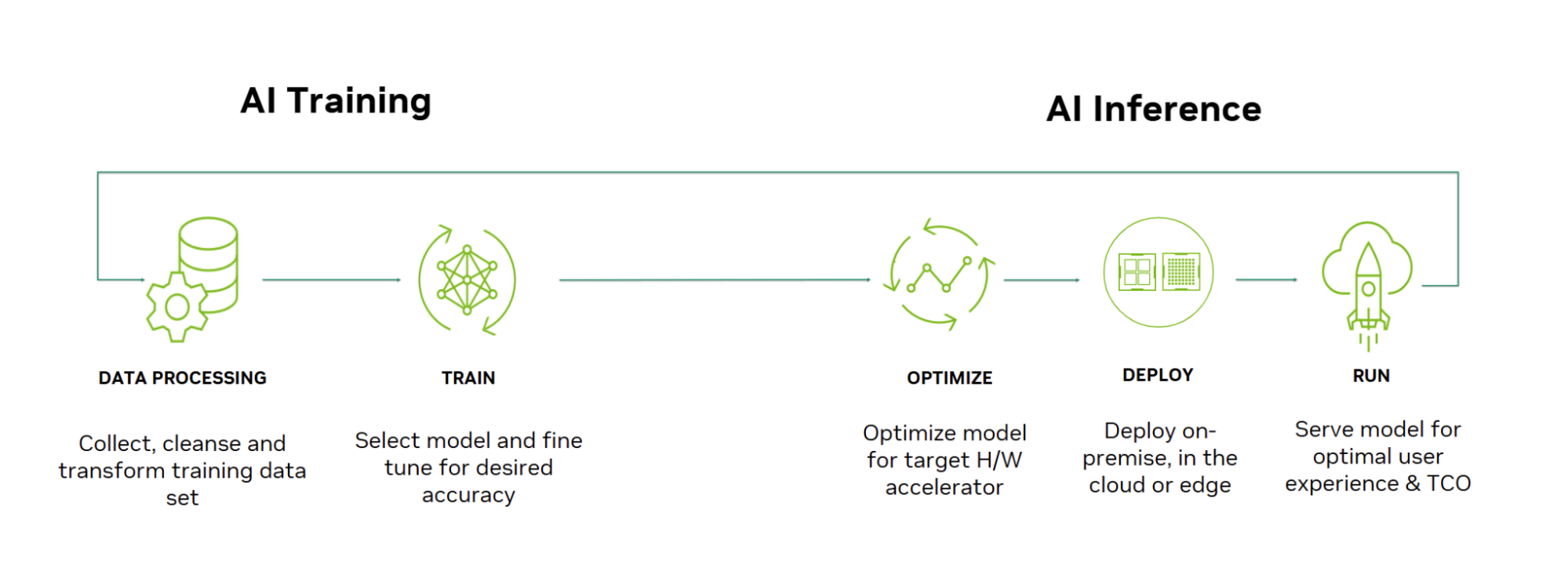
Inference is the process where a trained AI model generates new outputs by reasoning and making predictions on new data — classifying inputs and applying learned knowledge in real time.
Inference can’t happen without training. Makes sense. That’s how we gain and use our own knowledge for the most part.
So let’s break down the progression from AI training to AI inference, and how they both function.
Training Deep Neural Networks

While the goal is the same — knowledge — the educational process, or training, of a neural network is (thankfully) not quite like our own. Neural networks are loosely modeled on the biology of our brains — all those interconnections between the neurons. Unlike our brains, where any neuron can connect to any other neuron within a certain physical distance, artificial neural networks have separate layers, connections and directions of data propagation.
When training a neural network, training data is put into the first layer of the network, and individual neurons assign a weighting to the input — how correct or incorrect it is — based on the task being performed.
In the case of a code generation assistant, for example, a model might first learn to understand user intent and map relationships between natural language instructions and code. Deeper layers could recognize programming patterns, syntax and structures, while subsequent layers might be able to autocomplete functions, suggest snippets or even translate code into another language. At the final stages, the network could review code for accuracy, offering refinements and corrections. Each layer builds on the last, with the model rewarded for how closely its outputs align with the desired solution.
Deep Learning Training Is Compute-Intensive
If the algorithm informs the neural network that it was wrong, it doesn’t get informed what the right answer is. Instead, the error is propagated back through the network’s layers, and the model must adjust its weights and try again. In a coding example, this might mean checking whether the suggested code actually runs, whether it follows the rules of the programming language and whether it does what the user asked for. With each pass, the network adjusts — weighing certain attributes of structure, logic or accuracy — and then tries again. Over many iterations, it converges on the correct weights, enabling it to reliably suggest accurate, useful code completions or translations.
Now you have a data structure and all the weights in there have been balanced based on what it has learned as you sent the training data through. The challenge is, it’s also a monster when it comes to consuming compute. For example, training Llama 3.1 with 405 billion parameters required roughly 38 yottaflops, which is 3.8 x 10^25 math operations across the entire training cycle.
Fine-Tuning Makes Models More Adaptable
Fine-tuning is the bridge between a foundation model trained on broad data and a model specialized for a specific domain — like legal documents, medical images or enterprise analytics. Instead of starting from scratch, developers reuse the core model and train just a few layers or adapters on domain-specific examples. This enables faster iteration for building domain-specific models. With fine-tuning complete, the model now has both broad knowledge and domain-specific expertise. The heavy lifting of training is done; the next step is turning that learned intelligence outward.
That’s where inference comes in.
Congratulations! Your Neural Network Is Trained and Ready for Inference
Once training is complete, the point is to put that intelligence to work. That’s inference: applying what’s been learned to new, unseen data and returning answers quickly and accurately.
Today, inference has become the beating heart of AI adoption across industries. Demand for tokens — the atomic units of intelligence — has never been higher, driven by AI reasoning models that generate thousands more tokens than their predecessors. These AI models enable agentic and physical AI, real-time decision-making and complex multi-step reasoning, but they also push compute requirements to unprecedented levels.
Meeting this challenge requires AI factories: highly optimized infrastructure designed to manufacture intelligence at scale.
Inference is not just about being fast — it’s about delivering the right combination of real-time responsiveness for each user while serving as many users as possible, all at AI factory scale. That’s why inference optimization techniques are so critical: they allow enterprises to optimize throughput and latency so they can meet their service level agreements across a variety of use cases. One key tool for evaluating inference is the Think SMART framework, which helps enterprises strike the right balance of accuracy, latency and return on investment when deploying AI at AI factory scale.
How AI Inference Works
At its core, for large language models, inference is the process of turning tokens into intelligence.
Input Encoding (Tokens In): Inputs such as words, images or audio are first broken into tokens — numerical representations that an AI model can process. For example, the word “hello” might become a short sequence of numbers.
Prefill Phase: All input tokens are processed at once, flowing through every layer of the neural network. The model uses its trained weights to understand context, relationships and meaning. This is computationally heavy since the entire set of input tokens is processed all together. To accelerate the prefill phase, enterprises can use a technique called disaggregated serving, in which a separate set of GPUs are used for the prefill phase than the next decode phase.
Decode Phase (Token by Token): The model begins generating outputs one token at a time. Each new token depends on the history of all the previous ones. Speculative decoding speeds this up by letting a smaller model “guess ahead” and the larger model quickly check those guesses, reducing wait time.
Output Conversion (Tokens Out): The sequence of predicted tokens is decoded back into human-readable language, such as an image or audio. That’s the “answer” users see on screen, or the recommendation they get in an app.
A smartphone’s AI assistant performs inference to support tasks such as real-time translation, personalized shopping or music recommendations. AI image generators like Stable Diffusion or DALL·E, chatbots like ChatGPT all rely on inference to deliver results instantly.
Evaluating Training and Inference Performance
Multiple inference performance benchmarks show how the full-stack NVIDIA inference platform consistently sets new industry records. To see how these advantages translate into real-world performance, explore the latest training and inference results for MLPerf, the industry-standard benchmark suite that highlights GPU-accelerated systems consistently setting new records in efficiency and speed.
Complementing these traditional benchmarks, open-source initiatives like InferenceMAX provide an additional layer of transparency and reliability. By evaluating popular models across leading hardware and publishing openly verifiable results, these benchmarks simplify comparisons of efficiency, cost and responsiveness in practical, real-world AI applications.
For AI service providers, strong benchmark performance translates directly into higher return on investment, enabling them to meet surging token demand while maximizing profitability.
Reasoning: The Next Frontier in AI
Beyond training and fine-tuning, a fast-growing area of interest is test-time scaling — prompting a model to solve harder problems by taking multiple steps during inference. This includes techniques like chain-of-thought prompting, external memory and multistep decomposition. These strategies show that inference itself can scale with more time or tokens — not just model size — unlocking better reasoning with the same trained model.
You can see how these models and applications will just get smarter, faster and more accurate. Inference will bring new applications to every aspect of our lives. It seems the same admonition applies to AI as it does to our youth — don’t be a fool, stay in school. Inference awaits.
To learn more, check out NVIDIA’s inference solutions for scaling large language model serving across AI factories. Or to learn more about the evolution of AI into deep learning, tune into the AI Podcast for an in-depth interview with NVIDIA’s Will Ramey.


