There are a few different ways to build IKEA furniture. Each will, ideally, lead to a completed couch or chair. But depending on the details, one approach will make more sense than the others.
Got the instruction manual and all the right pieces? Just follow directions. Getting the hang of it? Toss the manual aside and go solo. But misplace the instructions, and it’s up to you to make sense of that pile of wooden dowels and planks.
It’s the same with deep learning. Based on the kind of data available and the research question at hand, a scientist will choose to train an algorithm using a specific learning model.
In a supervised learning model, the algorithm learns on a labeled dataset, providing an answer key that the algorithm can use to evaluate its accuracy on training data. An unsupervised model, in contrast, provides unlabeled data that the algorithm tries to make sense of by extracting features and patterns on its own.
Semi-supervised learning takes a middle ground. It uses a small amount of labeled data bolstering a larger set of unlabeled data. And reinforcement learning trains an algorithm with a reward system, providing feedback when an artificial intelligence agent performs the best action in a particular situation.
Let’s walk through the kinds of datasets and problems that lend themselves to each kind of learning.
What Is Supervised Learning?
If you’re learning a task under supervision, someone is present judging whether you’re getting the right answer. Similarly, in supervised learning, that means having a full set of labeled data while training an algorithm.
Fully labeled means that each example in the training dataset is tagged with the answer the algorithm should come up with on its own. So, a labeled dataset of flower images would tell the model which photos were of roses, daisies and daffodils. When shown a new image, the model compares it to the training examples to predict the correct label.
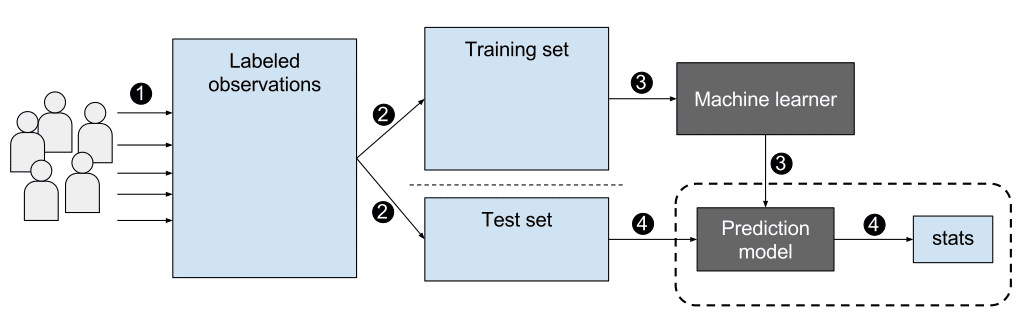
There are two main areas where supervised learning is useful: classification problems and regression problems.

Classification problems ask the algorithm to predict a discrete value, identifying the input data as the member of a particular class, or group. In a training dataset of animal images, that would mean each photo was pre-labeled as cat, koala or turtle. The algorithm is then evaluated by how accurately it can correctly classify new images of other koalas and turtles.
On the other hand, regression problems look at continuous data. One use case, linear regression, should sound familiar from algebra class: given a particular x value, what’s the expected value of the y variable?
A more realistic machine learning example is one involving lots of variables, like an algorithm that predicts the price of an apartment in San Francisco based on square footage, location and proximity to public transport.
Supervised learning is, thus, best suited to problems where there is a set of available reference points or a ground truth with which to train the algorithm. But those aren’t always available.
What Is Unsupervised Learning?
Clean, perfectly labeled datasets aren’t easy to come by. And sometimes, researchers are asking the algorithm questions they don’t know the answer to. That’s where unsupervised learning comes in.
In unsupervised learning, a deep learning model is handed a dataset without explicit instructions on what to do with it. The training dataset is a collection of examples without a specific desired outcome or correct answer. The neural network then attempts to automatically find structure in the data by extracting useful features and analyzing its structure.

Depending on the problem at hand, the unsupervised learning model can organize the data in different ways.
- Clustering: Without being an expert ornithologist, it’s possible to look at a collection of bird photos and separate them roughly by species, relying on cues like feather color, size or beak shape. That’s how the most common application for unsupervised learning, clustering, works: the deep learning model looks for training data that are similar to each other and groups them together.
- Anomaly detection: Banks detect fraudulent transactions by looking for unusual patterns in customer’s purchasing behavior. For instance, if the same credit card is used in California and Denmark within the same day, that’s cause for suspicion. Similarly, unsupervised learning can be used to flag outliers in a dataset.
- Association: Fill an online shopping cart with diapers, applesauce and sippy cups and the site just may recommend that you add a bib and a baby monitor to your order. This is an example of association, where certain features of a data sample correlate with other features. By looking at a couple key attributes of a data point, an unsupervised learning model can predict the other attributes with which they’re commonly associated.
- Autoencoders: Autoencoders take input data, compress it into a code, then try to recreate the input data from that summarized code. It’s like starting with Moby Dick, creating a SparkNotes version and then trying to rewrite the original story using only SparkNotes for reference. While a neat deep learning trick, there are fewer real-world cases where a simple autocoder is useful. But add a layer of complexity and the possibilities multiply: by using both noisy and clean versions of an image during training, autoencoders can remove noise from visual data like images, video or medical scans to improve picture quality.
Because there is no “ground truth” element to the data, it’s difficult to measure the accuracy of an algorithm trained with unsupervised learning. But there are many research areas where labeled data is elusive, or too expensive, to get. In these cases, giving the deep learning model free rein to find patterns of its own can produce high-quality results.
What Is Semi-Supervised Learning?
Think of it as a happy medium.
Semi-supervised learning is, for the most part, just what it sounds like: a training dataset with both labeled and unlabeled data. This method is particularly useful when extracting relevant features from the data is difficult, and labeling examples is a time-intensive task for experts.
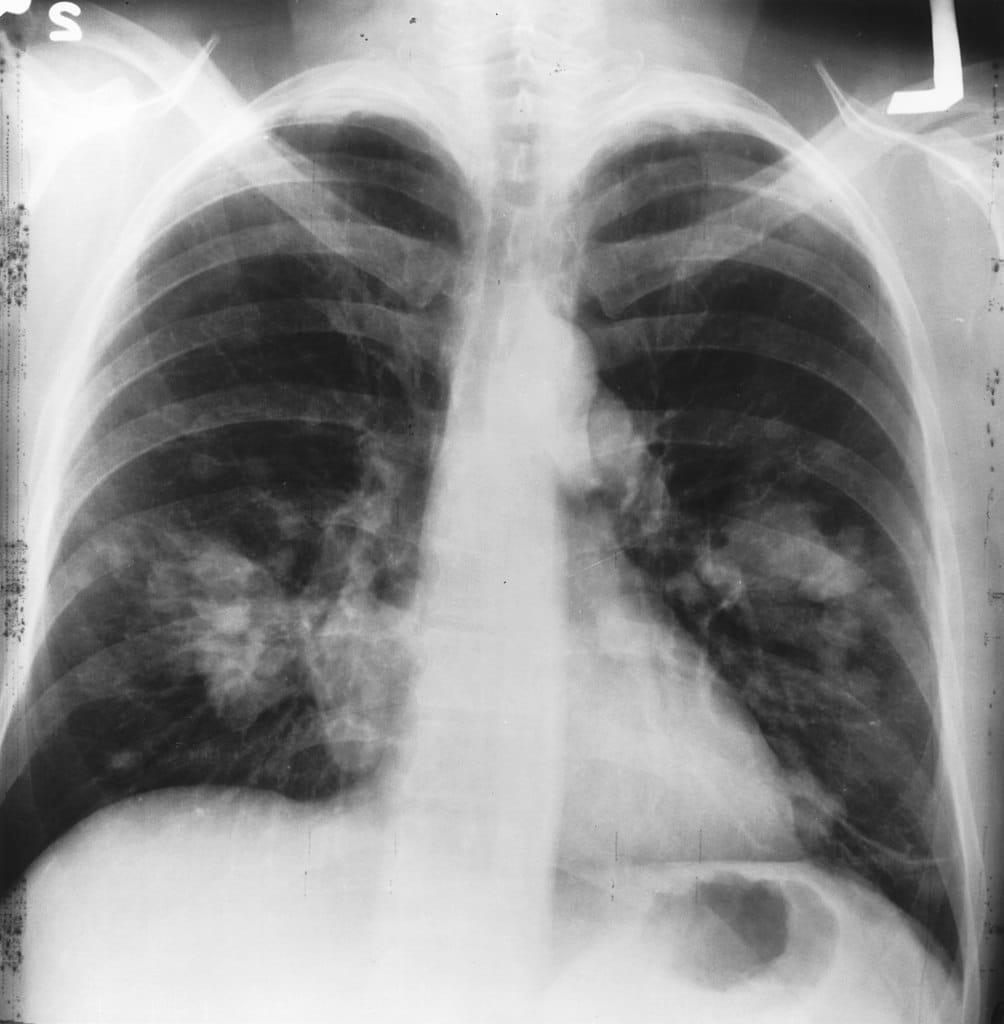
Common situations for this kind of learning are medical images like CT scans or MRIs. A trained radiologist can go through and label a small subset of scans for tumors or diseases. It would be too time-intensive and costly to manually label all the scans — but the deep learning network can still benefit from the small proportion of labeled data and improve its accuracy compared to a fully unsupervised model.
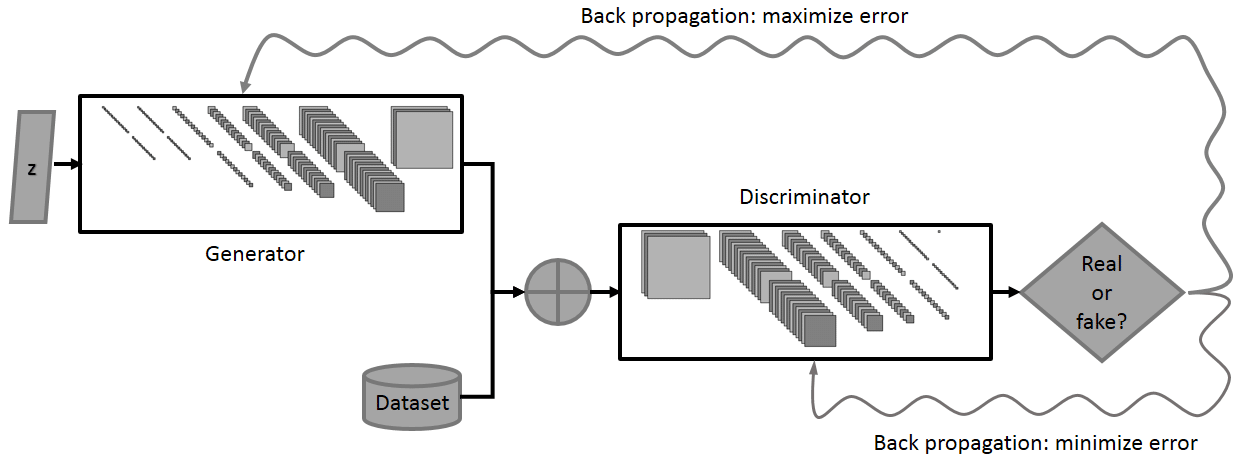
A popular training method that starts with a fairly small set of labeled data is using general adversarial networks, or GANs.
Imagine two deep learning networks in competition, each trying to outsmart the other. That’s a GAN. One of the networks, called the generator, tries to create new data points that mimic the training data. The other network, the discriminator, pulls in these newly generated data and evaluates whether they are part of the training data or fakes. The networks improve in a positive feedback loop — as the discriminator gets better at separating the fakes from the originals, the generator improves its ability to create convincing fakes.
What Is Reinforcement Learning?
Video games are full of reinforcement cues. Complete a level and earn a badge. Defeat the bad guy in a certain number of moves and earn a bonus. Step into a trap — game over.
These cues help players learn how to improve their performance for the next game. Without this feedback, they would just take random actions around a game environment in the hopes of advancing to the next level.
Reinforcement learning operates on the same principle — and actually, video games are a common test environment for this kind of research.
In this kind of machine learning, AI agents are attempting to find the optimal way to accomplish a particular goal, or improve performance on a specific task. As the agent takes action that goes toward the goal, it receives a reward. The overall aim: predict the best next step to take to earn the biggest final reward.
To make its choices, the agent relies both on learnings from past feedback and exploration of new tactics that may present a larger payoff. This involves a long-term strategy — just as the best immediate move in a chess game may not help you win in the long run, the agent tries to maximize the cumulative reward.
It’s an iterative process: the more rounds of feedback, the better the agent’s strategy becomes. This technique is especially useful for training robots, which make a series of decisions in tasks like steering an autonomous vehicle or managing inventory in a warehouse.
Just as students in a school, every algorithm learns differently. But with the diversity of approaches available, it’s only a matter of picking the best way to help your neural network learn the ropes.