
The hit 1982 TV series Knight Rider, starring David Hasselhoff and a futuristic crime-fighting Pontiac Firebird, was prophetic. The self-driving, talking car also offers a Hollywood lesson in image and language recognition.
If scripted today, Hasselhoff’s AI car, dubbed KITT, would feature deep learning from convolutional neural networks and recurrent neural networks to see, hear and talk.
That’s because CNNs are the image crunchers now used by machines — the eyes — to identify objects. And RNNs are the mathematical engines — the ears and mouth — used to parse language patterns.
Fast-forward from the ‘80s, and CNNs are today’s eyes of autonomous vehicles, oil exploration and fusion energy research. They can help spot diseases faster in medical imaging and save lives.
Today the “Hoff” — like billions of others — benefits, even if unwittingly, from CNNs to post photos of friends on Facebook, enjoying its auto-tagging feature for names, adding to his social lubrication.
So strip the CNN from his Firebird and it no longer has the computerized eyes to drive itself, becoming just another action prop without sizzle.
And yank the RNN from Hasselhoff’s sleek, black, autonomous Firebird sidekick, and there goes the intelligent computerized voice that wryly pokes fun at his bachelorhood. Not to mention, toss out KITT’s command of French and Spanish.
Without a doubt, RNNs are revving up a voice-based computing revolution. They are the natural language processing brains that give ears and speech to Amazon’s Alexa, Google’s Assistant and Apple’s Siri. They lend clairvoyant-like magic to Google’s autocomplete feature that fills in lines of your search queries.

Moreover, CNNs and RNNs today make such a car more than just Tinseltown fantasy. Automakers are now fast at work on the KITT-like cars of tomorrow.
Today’s autonomous cars can get put through paces in simulation to test before even hitting the road. This allows developers to test and validate that the eyes of the vehicle are able to see at superhuman levels of perception.
AI-driven machines of all types are becoming powered with eyes and ears like ours, thanks to CNNs and RNNs. Much of these applications of AI are made possible by decades of advances in deep neural networks and strides in high performance computing from GPUs to process massive amounts of data.
Brief History of CNNs
How did we get here is often asked. Long before autonomous vehicles came along, the biological connections made between neurons of the human brain served as inspiration to researchers studying general artificial neural networks. Researchers of CNNs followed the same line of thinking.
A seminal moment for CNNs hit in 1998. That year Yann LeCun and co-authors Léon Bottou, Yoshua Bengio and Patrick Haffner published the influential paper Gradient-based Learning Applied to Document Recognition.
The paper describes how these learning algorithms can help classify patterns in handwritten letters with minimal preprocessing. The research into CNNs proved record-breaking accuracy at reading bank checks and has now been implemented widely for processing them commercially.
It fueled a surge of hope for the promise of AI. LeCun, the paper’s lead researcher, became a professor at New York University in 2003 and much later joined Facebook, in 2018, to become the social network’s chief AI scientist.
The next breakout moment was 2012. That’s when University of Toronto researchers Alex Krizhevsky, Ilya Sutskever and Geoffrey Hinton published the groundbreaking paper ImageNet Classification with Deep Convolutional Neural Networks.
The research advanced the state of object recognition. The trio trained a deep convolutional neural network to classify the 1.2 million images from the ImageNet Large Scale Visual Recognition Challenge contest, winning with a record-breaking reduction in error rate.
This sparked today’s modern AI boom.
CNNs Explained: Dog or Pony?
Here’s an example of image recognition’s role. We humans can see a Great Dane and know it’s big but that it is still a dog. Computers just see numbers. How do they know a Great Dane isn’t a pony? Well, that numerical representation of pixels can be processed through many layers of a CNN. Many Great Dane features can be identified this way to arrive at dog for an answer.
Now, let’s peek deeper under the hood of CNNs to understand what goes on at a more technical level.
CNNs are comprised of an input layer (such as an image represented by numbers for pixels), one or more hidden layers and an output layer.
These layers of math operations help computers define details of images little bits at a time in an effort to eventually — hopefully — identify specific objects or animals or whatever the aim. They often miss, however, especially early on in training.
Convolutional Layer:
In mathematics, a convolution is a grouping function. In CNNs, convolution happens between two matrices (rectangular arrays of numbers arranged in columns and rows) to form a third matrix as an output.
A CNN uses these convolutions in the convolutional layers to filter input data and find information.
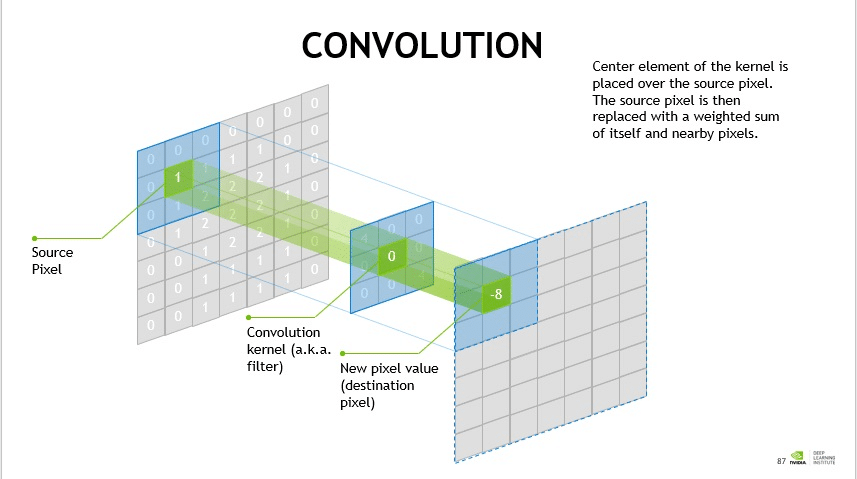
The convolutional layer does most of the computational heavy lifting in a CNN. It acts as the mathematical filters that help computers find edges of images, dark and light areas, colors, and other details, such as height, width and depth.
There are usually many convolutional layer filters applied to an image.
- Pooling layer: Pooling layers are often sandwiched between the convolutional layers. They’re used to reduce the size of the representations created by the convolutional layers as well as reduce the memory requirements, which allows for more convolutional layers.
- Normalization layer: Normalization is a technique used to improve the performance and stability of neural networks. It acts to make more manageable the inputs of each layer by converting all inputs to a mean of zero and a variance of one. Think of this as regularizing the data.
- Fully connected layers: Fully connected layers are used to connect every neuron in one layer to all the neurons in another layer.
For a more in-depth technical explanation, check out the CNN page of our developer site.
CNNs are ideally suited for computer vision, but feeding them enough data can make them useful in videos, speech, music and text as well.
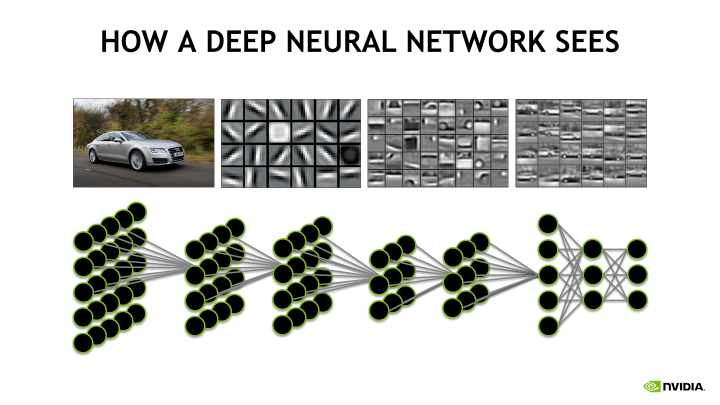
They can enlist a giant sequence of filters — or neurons — in these hidden layers that all optimize toward efficiency in identifying an image. CNNs are called “feedforward” neural networks because information is fed from one layer to the next.
Alternatively, RNNs share much of the same architecture of traditional artificial neural networks and CNNs, except that they have memory that can serve as feedback loops. Like a human brain, particularly in conversations, more weight is given to recency of information to anticipate sentences.
This makes RNNs suited for predicting what comes next in a sequence of words. Also, RNNs can be fed sequences of data of varying length, while CNNs have fixed input data.
A Brief History of RNNs
Like the rising star of Hasselhoff, RNNs have been around since the 1980s. In 1982, John Hopfield invented the Hopfield network, an early RNN.
What’s known as long short-term memory (LSTM) networks, and used by RNNs, was invented by Sepp Hochreiter and Jürgen Schmidhuber in 1997. By about 2007, LSTMs made leaps in speech recognition.
In 2009, an RNN was winning pattern recognition contests for handwriting recognition. By 2014, China’s Baidu search engine beat the Switchboard Hub5’00 speech recognition standard, a new landmark.
RNNs Explained: What’s for Lunch?
An RNN is a neural network with an active data memory, known as the LSTM, that can be applied to a sequence of data to help guess what comes next.
With RNNs, the outputs of some layers are fed back into the inputs of a previous layer, creating a feedback loop.
Here’s a classic example of a simple RNN. It’s for keeping track of which day the main dishes are served in your cafeteria, which let’s say has a rigid schedule of the same dish running on the same day each week. Let’s imagine it looks like this: burgers on Mondays, tacos on Tuesdays, pizza on Wednesdays, sushi on Thursdays and pasta on Fridays.
With an RNN, if the output “sushi” is fed back into the network to determine Friday’s dish, then the RNN will know that the next main dish in the sequence is pasta (because it has learned there is an order and Thursday’s dish just happened, so Friday’s dish comes next).
Another example is the sentence: I just ran 10 miles and need a drink of ______. A human could figure how to fill in the blank based on past experience. Thanks to the memory capabilities of RNNs, it’s possible to anticipate what comes next because it may have enough trained memory of similar such sentences that end with “water” to complete the answer.
RNN applications extend beyond natural language processing and speech recognition. They’re used in language translation, stock predictions and algorithmic trading as well.
Also used, neural turing machines (NTMs) are RNNs that have access to external memory.
Last, what’s known as bidirectional RNNs take an input vector and train it on two RNNs. One of the them gets trained on the regular RNN input sequence while the other on a reversed sequence. Outputs from both RNNs are next concatenated, or combined
All told, CNNs and RNNs have made apps, the web and the world of machines far more capable with sight and speech. Without these two AI workhorses, our machines would be boring.
Amazon’s Alexa, for one, is teaching us how to talk to our kitchen Echo “radio” devices, begging all kinds of new queries in chatting with its quirky AI.
And autonomous vehicles will soon be right around the corner, promising a starring role in our lives.
For a more technical deep dive on RNNs, check out our developers site. To learn more about deep learning, visit our NVIDIA Deep Learning Institute for the latest information on classes.


