The new ranking of the TOP500 supercomputers paints a picture of modern scientific computing, expanded with AI and data analytics, and accelerated with NVIDIA technologies.
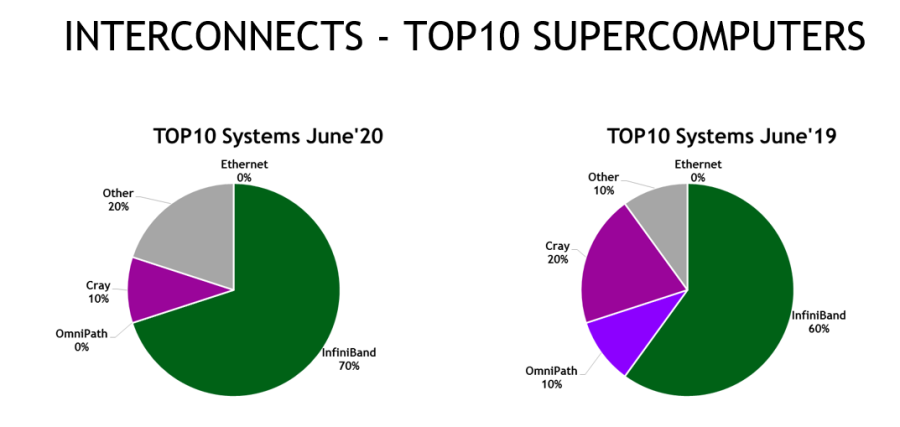
Eight of the world’s top 10 supercomputers now use NVIDIA GPUs, InfiniBand networking or both. They include the most powerful systems in the U.S., Europe and China.
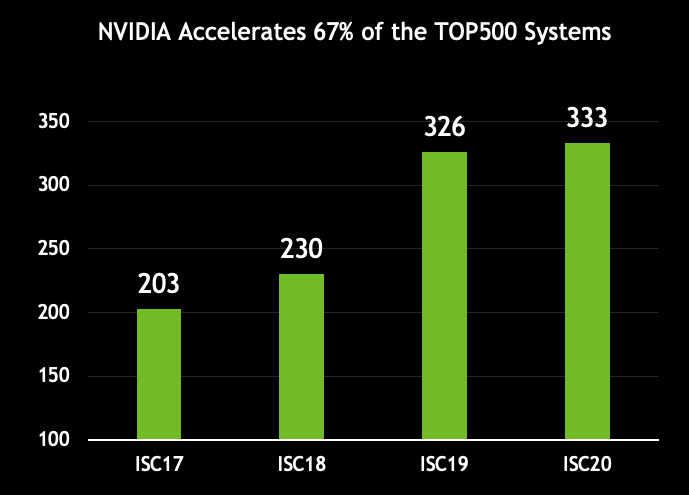
NVIDIA, now combined with Mellanox, powers two-thirds (333) of the overall TOP500 systems on the latest list, up dramatically from less than half (203) for the two separate companies combined on the June 2017 list.
Nearly three-quarters (73 percent) of the new InfiniBand systems on the list adopted NVIDIA Mellanox HDR 200G InfiniBand, demonstrating the rapid embrace of the latest data rates for smart interconnects.
The number of TOP500 systems using HDR InfiniBand nearly doubled since the November 2019 list. Overall, InfiniBand appears in 141 supercomputers on the list, up 12 percent since June 2019.
NVIDIA Mellanox InfiniBand and Ethernet networks connect 305 systems (61 percent) of the TOP500 supercomputers, including all of the 141 InfiniBand systems, and 164 (63 percent) of the systems using Ethernet.
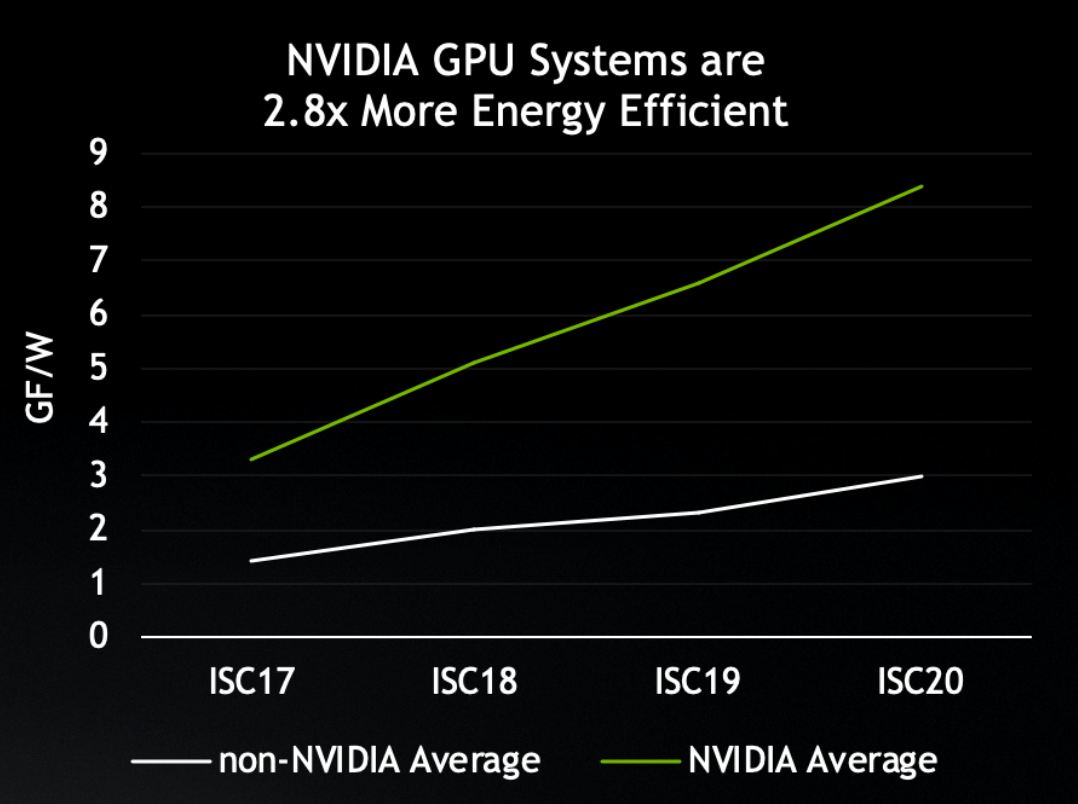
In energy efficiency, the systems using NVIDIA GPUs are pulling away from the pack. On average, they’re now 2.8x more power-efficient than systems without NVIDIA GPUs, measured in gigaflops/watt.
That’s one reason why NVIDIA GPUs are now used by 20 of the top 25 supercomputers on the Green500 list.
The best example of this power efficiency is Selene (pictured above), the latest addition to NVIDIA’s internal research cluster. The system was No. 2 on the latest Green500 list and No. 7 on the overall TOP500 at 27.5 petaflops on the Linpack benchmark.
At 20.5 gigaflops/watt, Selene is within a fraction of a point from the top spot on the Green500 list, claimed by a much smaller system that ranked No. 394 by performance.
Selene is the only top 100 system to crack the 20 gigaflops/watt barrier. It’s also the second most powerful industrial supercomputer in the world behind the No. 6 system from energy giant Eni S.p.A. of Italy, which also uses NVIDIA GPUs.
In energy use, Selene is 6.8x more efficient than the average TOP500 system not using NVIDIA GPUs. Selene’s performance and energy efficiency are thanks to third-generation Tensor Cores in NVIDIA A100 GPUs that speed up both traditional 64-bit math for simulations and lower precision work for AI.
Selene’s rankings are an impressive feat for a system that took less than four weeks to build. Engineers were able to assemble Selene quickly because they used NVIDIA’s modular reference architecture.
The guide defines what NVIDIA calls a DGX SuperPOD. It’s based on a powerful, yet flexible building block for modern data centers: the NVIDIA DGX A100 system.
The DGX A100 is an agile system, available today, that packs eight A100 GPUs in a 6U server with NVIDIA Mellanox HDR InfiniBand networking. It was created to accelerate a rich mix of high performance computing, data analytics and AI jobs — including training and inference — and to be fast to deploy.
Scaling from Systems to SuperPODs
With the reference design, any organization can quickly set up a world-class computing cluster. It shows how 20 DGX A100 systems can be linked in Lego-like fashion using high-performance NVIDIA Mellanox InfiniBand switches.
Four operators can rack a 20-system DGX A100 cluster in as little as an hour, creating a 2-petaflops system powerful enough to appear on the TOP500 list. Such systems are designed to run comfortably within the power and thermal capabilities of standard data centers.
By adding an additional layer of NVIDIA Mellanox InfiniBand switches, engineers linked 14 of these 20-system units to create Selene, which sports:
- 280 DGX A100 systems
- 2,240 NVIDIA A100 GPUs
- 494 NVIDIA Mellanox Quantum 200G InfiniBand switches
- 56 TB/s network fabric
- 7PB of high-performance all-flash storage
One of Selene’s most significant specs is it can deliver more than 1 exaflops of AI performance.
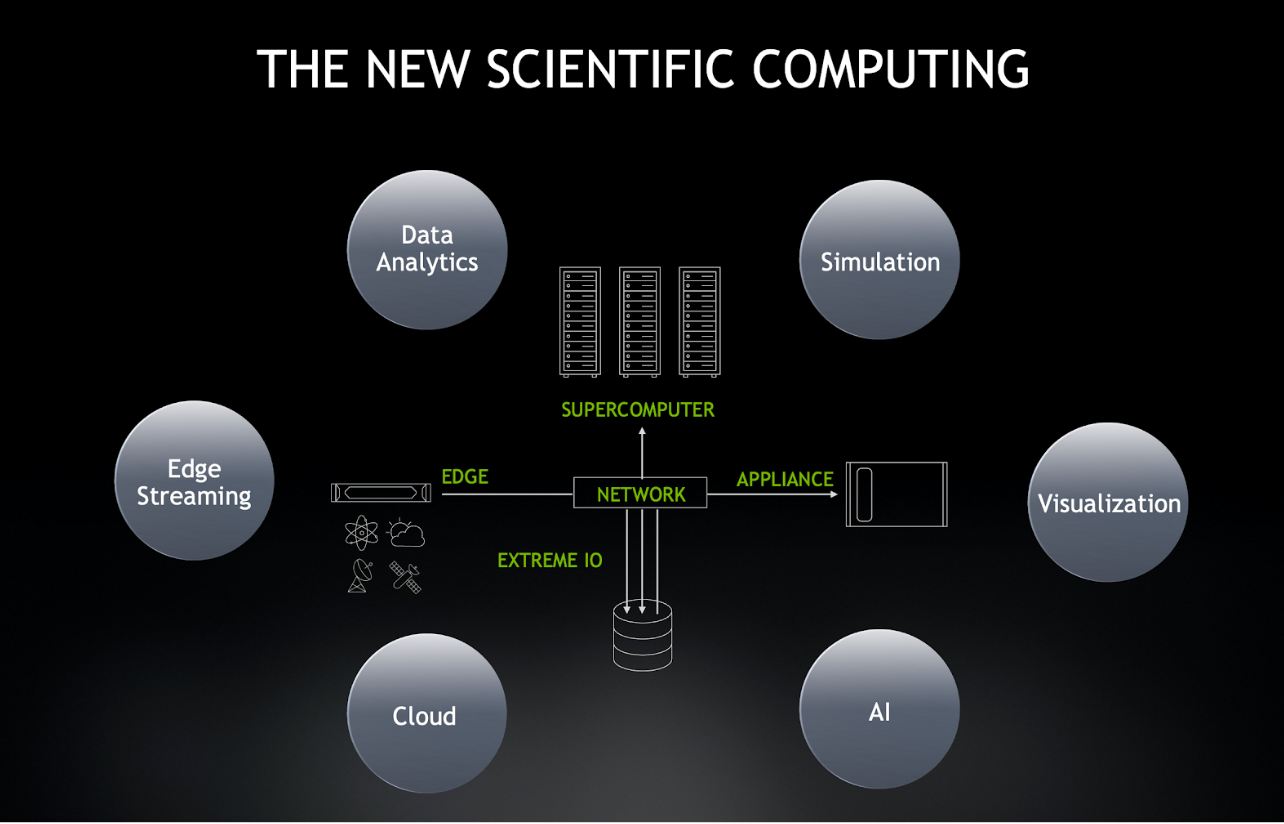
These results are critical at a time when AI and analytics are becoming part of the new requirements for scientific computing.
Around the world, researchers are using deep learning and data analytics to predict the most fruitful areas for conducting experiments. The approach reduces the number of costly and time-consuming experiments researchers require, accelerating scientific results.
For example, six systems not yet on the TOP500 list are being built today with the A100 GPUs NVIDIA launched last month. They’ll accelerate a blend of HPC and AI that’s defining a new era in science.
TOP500 Expands Canvas for Scientific Computing
One of those systems is at Argonne National Laboratory, where researchers will use a cluster of 24 NVIDIA DGX A100 systems to scan billions of drugs in the search for treatments for COVID-19.
“Much of this work is hard to simulate on a computer, so we use AI to intelligently guide where and when we will sample next,” said Arvind Ramanathan, a computational biologist at Argonne, in a report on the first users of A100 GPUs.
For its part, NERSC (the U.S. National Energy Research Scientific Computing Center) is embracing AI for several projects targeting Perlmutter, its pre-exascale system packing 6,200 A100 GPUs.
For example, one project will use reinforcement learning to control light source experiments, and one will apply generative models to reproduce expensive simulations at high-energy physics detectors.
Researchers in Munich are training natural-language models on 6,000 GPUs on the Summit supercomputer to speed the analysis of coronavirus proteins. It’s another sign that leading TOP500 systems are extending beyond traditional simulations run with double-precision math.
As scientists expand into deep learning and analytics, they’re also tapping into cloud computing services and even streaming data from remote instruments at the edge of the network. Together these elements form four pillars of modern scientific computing that NVIDIA accelerates:
- Simulation: In the fight against COVID-19, researchers at Oak Ridge National Laboratory are simulating over 2 billion compounds in 24 hours, running AutoDock on GPUs on the Summit supercomputer.
- AI and data analytics: GPU acceleration for Spark 3.0 now delivers speedups for the critical and time-consuming front-end of the machine-learning pipeline.
- Scientific edge streaming: CERN recently announced that NVIDIA GPUs will enable a 500x reduction in the huge amounts of data produced by particle collision events within its Large Hadron Collider.
- Visualization: NVIDIA’s IndeX and Magnum IO software help power a visualization of the Mars Lander, the world’s largest interactive, real-time volumetric visualization.
It’s part of a broader trend where both researchers and enterprises are seeking acceleration for AI and analytics from the cloud to the network’s edge. That’s why the world’s largest cloud service providers along with the world’s top OEMs are adopting NVIDIA GPUs.
In this way, the latest TOP500 list reflects NVIDIA’s efforts to democratize AI and HPC. Any company that wants to build leadership computing capabilities can access NVIDIA technologies such as DGX systems that power the world’s most powerful systems.
Finally, NVIDIA congratulates the engineers behind the Fugaku supercomputer in Japan for taking the No. 1 spot, showing Arm is becoming more real and now a viable option in high performance computing. That’s one reason why NVIDIA announced a year ago it’s making its CUDA accelerated computing software available on the Arm processor architecture.
Editor’s note: This post has been updated to remove a reference to a preliminary benchmark.