



NVIDIA Powers Over 400 of the World’s 500 Fastest Supercomputers
NVIDIA technologies power more than 400 of the world’s 500 fastest supercomputers — 81% of the TOP500 — according to the latest rankings released this week at the ISC High...
For the past two years, the U.S. National Science Foundation’s National Artificial Intelligence Research Resource (NAIRR) pilot program has driven innovative research across the U.S....
NVIDIA technologies power more than 400 of the world’s 500 fastest supercomputers — 81% of the TOP500 — according to the latest rankings released this week at the ISC High...

JUPITER, Europe’s first exascale supercomputer at Germany’s Forschungszentrum Jülich, runs on NVIDIA Grace Hopper Superchips and NVIDIA Quantum-X800 InfiniBand networking — and it’s had a busy year. As the international...

Mission, Vision and Veritas — new Los Alamos National Laboratory (LANL) supercomputers to be built with HPE and NVIDIA — are tapping NVIDIA Vera CPUs to accelerate scientific discovery, unlocking...

At the ISC conference running in Hamburg this week, NVIDIA is introducing new software that speeds AI for science, from chemistry and materials discovery to the search for dark matter. ...

The next era of AI will not be defined by compute alone. Its growth will be determined by energy. As accelerated computing scales across AI factories, agentic AI, industrial AI,...

NVIDIA founder and CEO Jensen Huang took the stage at the Fontainebleau Las Vegas to open CES 2026, declaring that AI is scaling into every domain and every device. “Computing...

The Hao AI Lab research team at the University of California San Diego — at the forefront of pioneering AI model innovation — recently received an NVIDIA DGX B200 system...

At SC25, NVIDIA unveiled advances across NVIDIA BlueField DPUs, next-generation networking, quantum computing, national research, AI physics and more — as accelerated systems drive the next chapter in AI supercomputing....
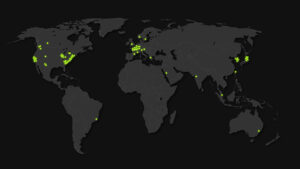
Across quantum physics, digital biology and climate research, the world’s researchers are harnessing a universal scientific instrument to chart new frontiers of discovery: accelerated computing. At this week’s SC25 conference...

To power future technologies including liquid-cooled data centers, high-resolution digital displays and long-lasting batteries, scientists are searching for novel chemicals and materials optimized for factors like energy use, durability and...
