NVIDIA and its partners continued to provide the best overall AI training performance and the most submissions across all benchmarks with 90% of all entries coming from the ecosystem, according to MLPerf benchmarks released today.
The NVIDIA AI platform covered all eight benchmarks in the MLPerf Training 2.0 round, highlighting its leading versatility.
fNo other accelerator ran all benchmarks, which represent popular AI use cases including speech recognition, natural language processing, recommender systems, object detection, image classification and more. NVIDIA has done so consistently since submitting in December 2018 to the first round of MLPerf, an industry-standard suite of AI benchmarks.
Leading Benchmark Results, Availability
In its fourth consecutive MLPerf Training submission, the NVIDIA A100 Tensor Core GPU based on the NVIDIA Ampere architecture continued to excel.

Selene — our in-house AI supercomputer based on the modular NVIDIA DGX SuperPOD and powered by NVIDIA A100 GPUs, our software stack and NVIDIA InfiniBand networking — turned in the fastest time to train on four out of eight tests.
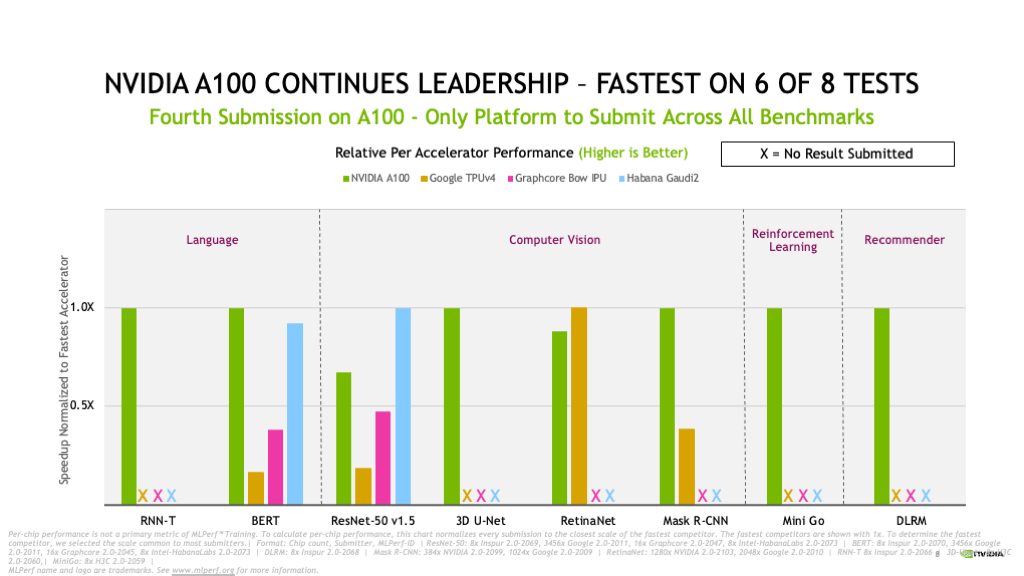
NVIDIA A100 also continued its per-chip leadership, proving the fastest on six of the eight tests.
A total of 16 partners submitted results this round using the NVIDIA AI platform. They include ASUS, Baidu, CASIA (Institute of Automation, Chinese Academy of Sciences), Dell Technologies, Fujitsu, GIGABYTE, New H3C Information Technologies, Hewlett Packard Enterprise, Inspur Electronic Information, KRAI, Lenovo, Microsoft Azure, MosaicML, Nettrix and Supermicro.
Most of our OEM partners submitted results using NVIDIA-Certified Systems, servers validated by NVIDIA to provide great performance, manageability, security and scalability for enterprise deployments.
Many Models Power Real AI Applications
An AI application may need to understand a user’s spoken request, classify an image, make a recommendation and deliver a response as a spoken message.
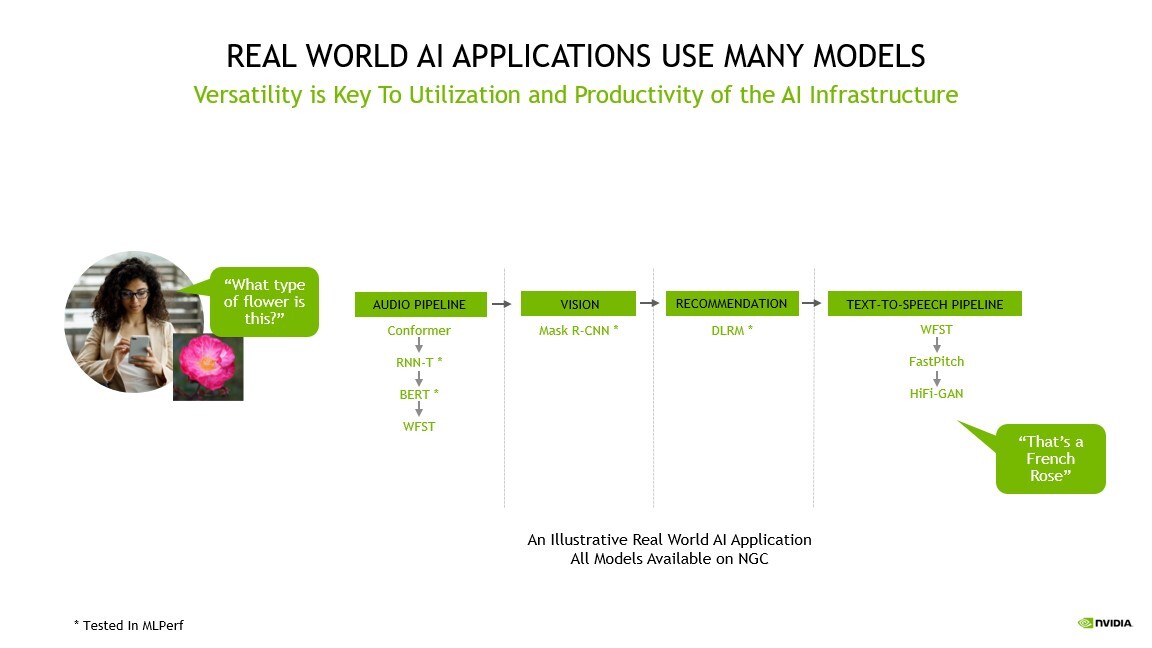
These tasks require multiple kinds of AI models to work in sequence, also known as a pipeline. Users need to design, train, deploy and optimize these models fast and flexibly.
That’s why both versatility – the ability to run every model in MLPerf and beyond – as well as leading performance are vital for bringing real-world AI into production.
Delivering ROI With AI
For customers, their data science and engineering teams are their most precious resources, and their productivity determines the return on investment for AI infrastructure. Customers must consider the cost of expensive data science teams, which often plays a significant part in the total cost of deploying AI, as well as the relatively small cost of deploying the AI infrastructure itself.
AI researcher productivity depends on the ability to quickly test new ideas, requiring both the versatility to train any model as well as the speed afforded by training those models at the largest scale.That’s why organizations focus on overall productivity per dollar to determine the best AI platforms — a more comprehensive view that more accurately represents the true cost of deploying AI.
In addition, the utilization of their AI infrastructure relies on its fungibility, or the ability to accelerate the entire AI workflow — from data prep to training to inference — on a single platform.
With NVIDIA AI, customers can use the same infrastructure for the entire AI pipeline, repurposing it to match the varying demands between data preparation, training and inference, which dramatically boosts utilization, leading to very high ROI.
And, as researchers discover new AI breakthroughs, supporting the latest model innovations is key to maximizing the useful life of AI infrastructure.
NVIDIA AI delivers the highest productivity per dollar as it is universal and performant for every model, scales to any size and accelerates AI from end to end — from data prep to training to inference.
Today’s results provide the latest demonstration of NVIDIA’s broad and deep AI expertise shown in every MLPerf training, inference and HPC round to date.
23x More Performance in 3.5 Years
In the two years since our first MLPerf submission with A100, our platform has delivered 6x more performance. Continuous optimizations to our software stack helped fuel those gains.
Since the advent of MLPerf, the NVIDIA AI platform has delivered 23x more performance in 3.5 years on the benchmark — the result of full-stack innovation spanning GPUs, software and at-scale improvements. It’s this continuous commitment to innovation that assures customers that the AI platform that they invest in today and keep in service for 3 to 5 years, will continue to advance to support the state-of-the-art.
In addition the NVIDIA Hopper architecture, announced in March, promises another giant leap in performance in future MLPerf rounds.
How We Did It
Software innovation continues to unlock more performance on the NVIDIA Ampere architecture.
For example, CUDA Graphs — software that helps minimize launch overhead on jobs that run across many accelerators — is used extensively across our submissions. Optimized kernels in our libraries like cuDNN and pre-processing in DALI unlocked additional speedups. We also implemented full stack improvements across hardware, software and networking such as NVIDIA Magnum IO and SHARP, which offloads some AI functions into the network to drive even greater performance, especially at scale.
All the software we use is available from the MLPerf repository, so everyone can get our world-class results. We continuously fold these optimizations into containers available on NGC, our software hub for GPU applications, and offer NVIDIA AI Enterprise to deliver optimized software, fully supported by NVIDIA.
Two years after the debut of A100, the NVIDIA AI platform continues to deliver the highest performance in MLPerf 2.0, and is the only platform to submit on every single benchmark. Our next-generation Hopper architecture promises another giant leap in future MLPerf rounds.
Our platform is universal for every model and framework at any scale, and provides the fungibility to handle every part of the AI workload. It’s available from every major cloud and server maker.