Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology accelerates creative workflows.
You can be my wing-wing anytime.
This week In the NVIDIA Studio takes off with the debut of Top Goose, a short animation created with Omniverse Machinima and inspired by one of the greatest fictional pilots to ever grace the big screen.
The project was powered by PCs using the same breed of GPU that has produced every Best Visual Effects nominee at the Academy Awards for 14 years: multiple systems with NVIDIA RTX A6000 GPUs and an NVIDIA Studio laptop — the Razer Blade 15 with a GeForce RTX 3070 Laptop GPU.
The team took Top Goose from concept to completion in just two weeks. It likely would’ve taken at least twice as long without the remote collaboration NVIDIA Omniverse offers NVIDIA RTX and GeForce RTX users.
Built to showcase the #MadeinMachinima contest, the inspiration was simple. One of the NVIDIANs involved in the project, Dane Johnston, succinctly noted, “How do you get a midcentury legionnaire on an aircraft carrier and what would he be doing? He’d be getting chased by a goose, of course.”
Ready to Take-Off
Johnston and fellow NVIDIANs Dave Tyner, Matthew Harwood and Terry Naas began the project by prepping models for the static assets in Autodesk 3ds Max. Several of the key models came from TurboSquid by Shutterstock, including the F14 fighter jet, aircraft carrier, goose and several props.

TurboSquid has a huge library of 3D models to begin creating within Omniverse. Simply drag and drop models into Omniverse and start collaborating with team members — regardless of the 3D application they’re using or where they’re physically located.
Tyner could easily integrate 3D models he already owned by simply dropping them into the scene from the new Asset Store browser in Omniverse.
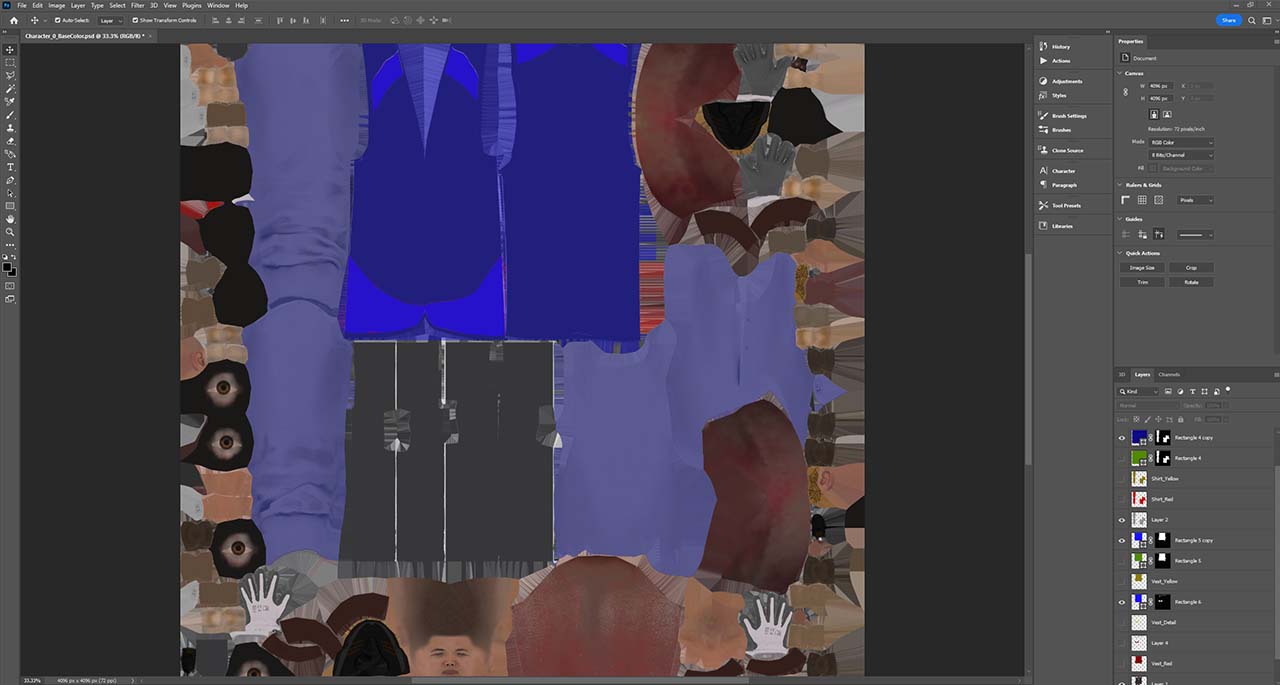
The team worked seamlessly between apps within Omniverse, in real time, including Adobe Photoshop.
From there, Adobe Photoshop was used to edit character uniforms and various props within the scene, including the Top Goose badge at the end of the cinematic.
Animators, Mount Up!
Once models were ready, animation could begin. The team used Reallusion’s iClone Character Creator Omniverse Connector to import characters to Machinima.
Omniverse-ready USD animations from Reallusion ActorCore were dragged and dropped into the Omniverse Machinima content browser for easy access.
The models and animations were brought into Machinima by Tyner, where he used the retargeting function to instantly apply the animations to different characters, including the top knight from Mount & Blade II: Bannerlord — one of the hundreds of assets included with Omniverse.
Tyner, a generalist 3D artist, supplemented the project by creating custom animations from motion capture using an Xsens suit that was exported to FBX. Using a series of Omniverse Connectors, he brought the FBX files into Autodesk 3ds Max and ran a quick script to create a rudimentary skin.
Then, Tyner sent the skinned character and animation into Autodesk Maya for USD skeleton export to Machinima, using the Autodesk Maya Connector. The animation was automatically retargeted onto the main character inside Machinima. Once the data was captured, the entire mocap workflow took only a few minutes using NVIDIA Studio tools.
If Tyner didn’t have a motion-capture suit, he could have used Machinima’s AI Pose Estimation — a tool within Omniverse that lets anyone with a camera capture movement and create a 3D animation.
Static objects were all animated in Machinima with the Curve Editor and Sequencer. These tools allowed the team to animate anything they wanted, exactly how they wanted. For instance, the team animated the fighter jet barrel rolls with gravity keyed on a y-axis — allowing gravity to be turned on and off.
This technique, coupled with NVIDIA PhysX, also allowed the team to animate the cockpit scene with the flying bread and apples simply by turning off the gravity. The objects in the scene all obeyed the laws of physics and flew naturally without any manual animation.

Animating the mighty wings of the goose was no cheap trick. While some of the animations were integrated as part of the asset from TurboSquid, the team collaborated within Omniverse to animate the inverted scenes.
Tyner used Omniverse Cloud Simple Share Early Access to package and send the entire USD project to Johnston and Harwood, NVIDIA’s resident audiophile. Harwood added sounds like the fly-bys and goose honks. Johnston brought the Mount & Blade II: Bannerlord character to life by recording custom audio and animating the character’s face with Omniverse Audio2Face.
Traditional audio workflows usually involve multiple pieces of audio recordings sent piecemeal to the animators. With Simple Share, Tyner packaged and sent the entire USD project to Harwood, who was able to add audio directly to the file and return it with a single click.
Revvin’ Up the Engine
Working in Omniverse meant the team could make adjustments and see the changes, with full-quality resolution, in real time. This saved the team a massive amount of time by not having to wait for single shots to render out.

With individuals working hundreds of miles apart, the team leveraged Omniverse’s collaboration capabilities with Omniverse Nucleus. They were able to complete set dressing, layout and lighting adjustments in a single real-time jam session.
The new constraints system in Machinima was integral to the camera work. Tyner created the shaky camera that helps bring the feeling of being on an aircraft carrier by animating a shaking ball in Autodesk 3ds Max, bringing it in via its Omniverse Connector, and constraining a camera to it using OmniGraph.
Equally important are the new Curve Editor and Sequencer. They gave the team complete intuitive control of the creative process. They used Sequencer to quickly and easily choreograph animated characters, lights, constraints and cameras — including field of view and depth of field.
With all elements in place, all that was left was the final render — conveniently and quickly handled using the Omniverse RTX renderer and without any file transfers in Omniverse Nucleus.
Tyner noted, “This is the first major project that I’ve done where I was never blocked. With Omniverse, everything just worked and was really easy to use.”
Not only was it easy to use individually, but Omniverse, part of the NVIDIA Studio suite of software, let this team of artists easily collaborate while working in and out of various apps from multiple locations.
Top Prizes in the #MadeinMachinima Contest
Top Goose is a showcase for #MadeinMachinima. The contest, which is currently running and closes June 27, asks artists to build and animate a cinematic short story with the Omniverse Machinima app for a chance to win RTX-accelerated NVIDIA Studio laptops.
RTX creators everywhere can remix and animate characters from Squad, Mount & Blade II: Bannerlord, Shadow Warrior 3, Post Scriptum, Beyond the Wire and Mechwarrior Mercenaries 5 using the Omniverse Machinima app.
Experiment with the AI-enabled tools like Audio2Face for instant facial animation from just an audio track; create intuitively with PhysX-powered tools to help you build as if building in reality; or add special effects with Blast for destruction and Flow for smoke and fire. You can use any third-party tools to help with your workflow, just assemble and render your final submission using Omniverse Machinima.
Learn more about NVIDIA Omniverse, including tips, tricks and more on the Omniverse YouTube channel. For additional support, explore the Omniverse forums or join the Discord server to chat with the community. Check out the Omniverse Twitter, Instagram and Medium page to stay up to date.
Follow NVIDIA Studio on Instagram, Twitter and Facebook. Access a wide range of tutorials on the Studio YouTube channel and get updates in your inbox by subscribing to the Studio newsletter.