NVIDIA researchers are collaborating with academic centers worldwide to advance generative AI, robotics and the natural sciences — and more than a dozen of these projects will be shared at NeurIPS, one of the world’s top AI conferences.
Set for Dec. 10-16 in New Orleans, NeurIPS brings together experts in generative AI, machine learning, computer vision and more. Among the innovations NVIDIA Research will present are new techniques for transforming text to images, photos to 3D avatars, and specialized robots into multi-talented machines.
“NVIDIA Research continues to drive progress across the field — including generative AI models that transform text to images or speech, autonomous AI agents that learn new tasks faster, and neural networks that calculate complex physics,” said Jan Kautz, vice president of learning and perception research at NVIDIA. “These projects, often done in collaboration with leading minds in academia, will help accelerate developers of virtual worlds, simulations and autonomous machines.”
Picture This: Improving Text-to-Image Diffusion Models
Diffusion models have become the most popular type of generative AI models to turn text into realistic imagery. NVIDIA researchers have collaborated with universities on multiple projects advancing diffusion models that will be presented at NeurIPS.
- A paper accepted as an oral presentation focuses on improving generative AI models’ ability to understand the link between modifier words and main entities in text prompts. While existing text-to-image models asked to depict a yellow tomato and a red lemon may incorrectly generate images of yellow lemons and red tomatoes, the new model analyzes the syntax of a user’s prompt, encouraging a bond between an entity and its modifiers to deliver a more faithful visual depiction of the prompt.
- SceneScape, a new framework using diffusion models to create long videos of 3D scenes from text prompts, will be presented as a poster. The project combines a text-to-image model with a depth prediction model that helps the videos maintain plausible-looking scenes with consistency between the frames — generating videos of art museums, haunted houses and ice castles (pictured above).
- Another poster describes work that improves how text-to-image models generate concepts rarely seen in training data. Attempts to generate such images usually result in low-quality visuals that aren’t an exact match to the user’s prompt. The new method uses a small set of example images that help the model identify good seeds — random number sequences that guide the AI to generate images from the specified rare classes.
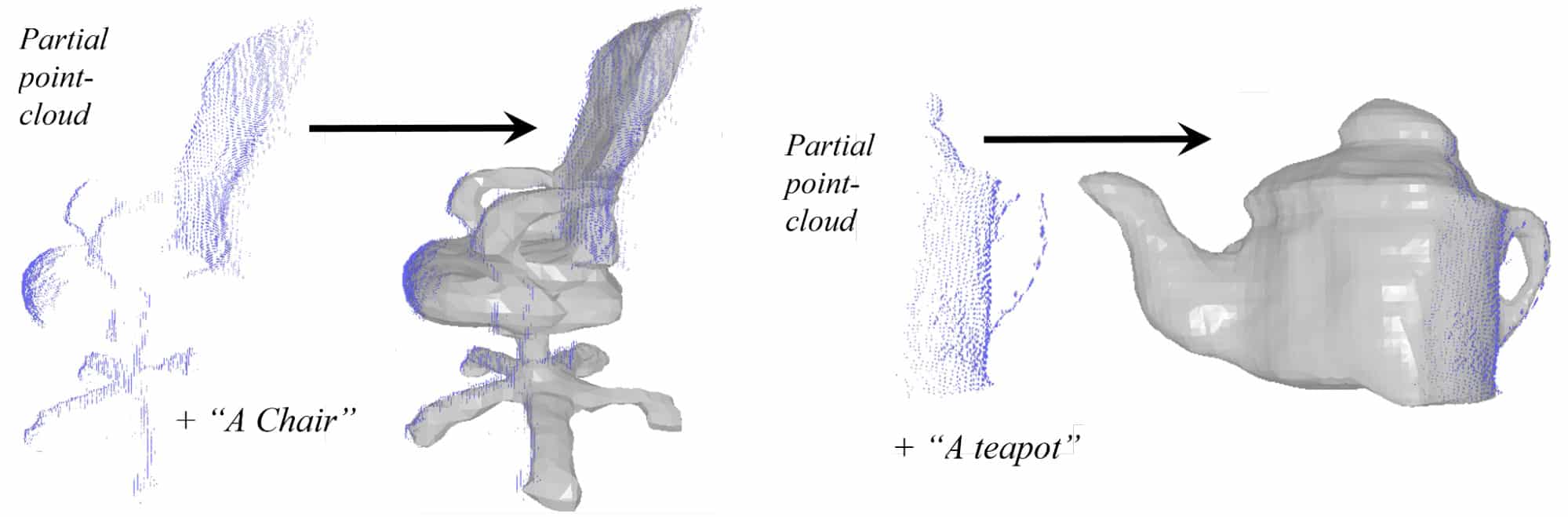
- A third poster shows how a text-to-image diffusion model can use the text description of an incomplete point cloud to generate missing parts and create a complete 3D model of the object. This could help complete point cloud data collected by lidar scanners and other depth sensors for robotics and autonomous vehicle AI applications. Collected imagery is often incomplete because objects are scanned from a specific angle — for example, a lidar sensor mounted to a vehicle would only scan one side of each building as the car drives down a street.
Character Development: Advancements in AI Avatars
AI avatars combine multiple generative AI models to create and animate virtual characters, produce text and convert it to speech. Two NVIDIA posters at NeurIPS present new ways to make these tasks more efficient.
- A poster describes a new method to turn a single portrait image into a 3D head avatar while capturing details including hairstyles and accessories. Unlike current methods that require multiple images and a time-consuming optimization process, this model achieves high-fidelity 3D reconstruction without additional optimization during inference. The avatars can be animated either with blendshapes, which are 3D mesh representations used to represent different facial expressions, or with a reference video clip where a person’s facial expressions and motion are applied to the avatar.
- Another poster by NVIDIA researchers and university collaborators advances zero-shot text-to-speech synthesis with P-Flow, a generative AI model that can rapidly synthesize high-quality personalized speech given a three-second reference prompt. P-Flow features better pronunciation, human likeness and speaker similarity compared to recent state-of-the-art counterparts. The model can near-instantly convert text to speech on a single NVIDIA A100 Tensor Core GPU.
Research Breakthroughs in Reinforcement Learning, Robotics
In the fields of reinforcement learning and robotics, NVIDIA researchers will present two posters highlighting innovations that improve the generalizability of AI across different tasks and environments.
- The first proposes a framework for developing reinforcement learning algorithms that can adapt to new tasks while avoiding the common pitfalls of gradient bias and data inefficiency. The researchers showed that their method — which features a novel meta-algorithm that can create a robust version of any meta-reinforcement learning model — performed well on multiple benchmark tasks.
- Another by an NVIDIA researcher and university collaborators tackles the challenge of object manipulation in robotics. Prior AI models that help robotic hands pick up and interact with objects can handle specific shapes but struggle with objects unseen in the training data. The researchers introduce a new framework that estimates how objects across different categories are geometrically alike — such as drawers and pot lids that have similar handles — enabling the model to more quickly generalize to new shapes.
Supercharging Science: AI-Accelerated Physics, Climate, Healthcare
NVIDIA researchers at NeurIPS will also present papers across the natural sciences — covering physics simulations, climate models and AI for healthcare.
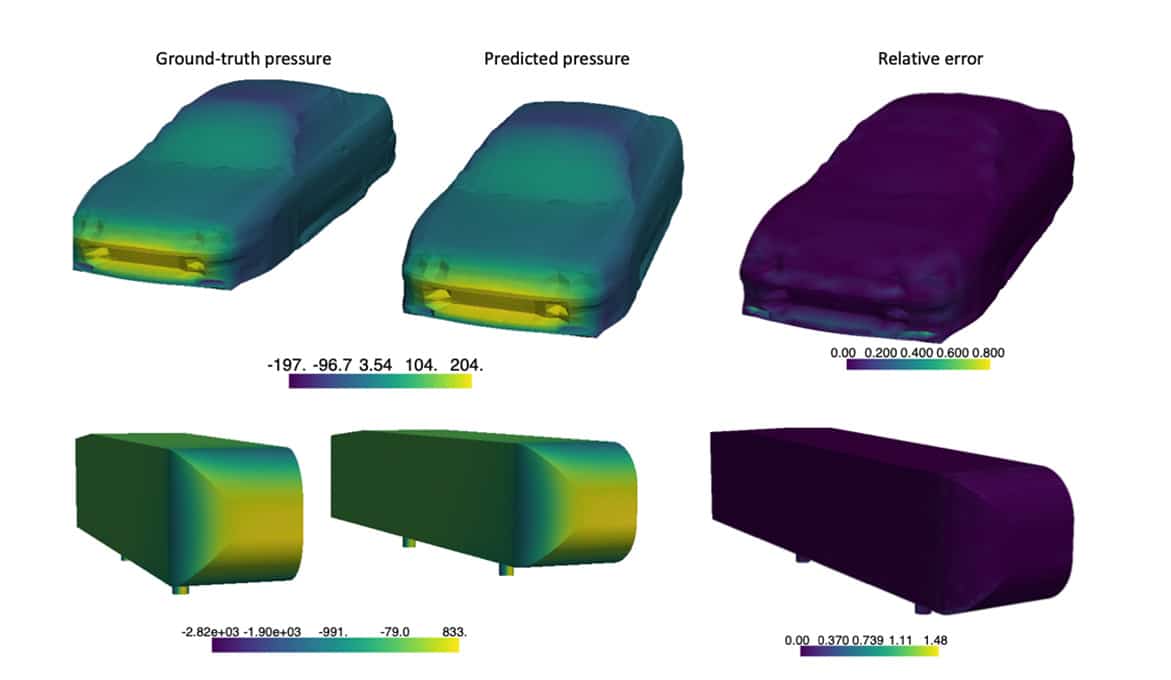
- To accelerate computational fluid dynamics for large-scale 3D simulations, a team of NVIDIA researchers proposed a neural operator architecture that combines accuracy and computational efficiency to estimate the pressure field around vehicles — the first deep learning-based computational fluid dynamics method on an industry-standard, large-scale automotive benchmark. The method achieved 100,000x acceleration on a single NVIDIA Tensor Core GPU compared to another GPU-based solver, while reducing the error rate. Researchers can incorporate the model into their own applications using the open-source neuraloperator library.
- A consortium of climate scientists and machine learning researchers from universities, national labs, research institutes, Allen AI and NVIDIA collaborated on ClimSim, a massive dataset for physics and machine learning-based climate research that will be shared in an oral presentation at NeurIPS. The dataset covers the globe over multiple years at high resolution — and machine learning emulators built using that data can be plugged into existing operational climate simulators to improve their fidelity, accuracy and precision. This can help scientists produce better predictions of storms and other extreme events.
- NVIDIA Research interns are presenting a poster introducing an AI algorithm that provides personalized predictions of the effects of medicine dosage on patients. Using real-world data, the researchers tested the model’s predictions of blood coagulation for patients given different dosages of a treatment. They also analyzed the new algorithm’s predictions of the antibiotic vancomycin levels in patients who received the medication — and found that prediction accuracy significantly improved compared to prior methods.
NVIDIA Research comprises hundreds of scientists and engineers worldwide, with teams focused on topics including AI, computer graphics, computer vision, self-driving cars and robotics.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.



