When we prompt generative AI to answer a question or create an image, large language models generate tokens of intelligence that combine to provide the result.
One prompt. One set of tokens for the answer. This is called AI inference.
Agentic AI uses reasoning to complete tasks. AI agents aren’t just providing one-shot answers. They break tasks down into a series of steps, each one a different inference technique.
One prompt. Many sets of tokens to complete the job.
The engines of AI inference are called AI factories — massive infrastructures that serve AI to millions of users at once.
AI factories generate AI tokens. Their product is intelligence. In the AI era, this intelligence grows revenue and profits. Growing revenue over time depends on how efficient the AI factory can be as it scales.
AI factories are the machines of the next industrial revolution.

Aerial view of Crusoe (Stargate)
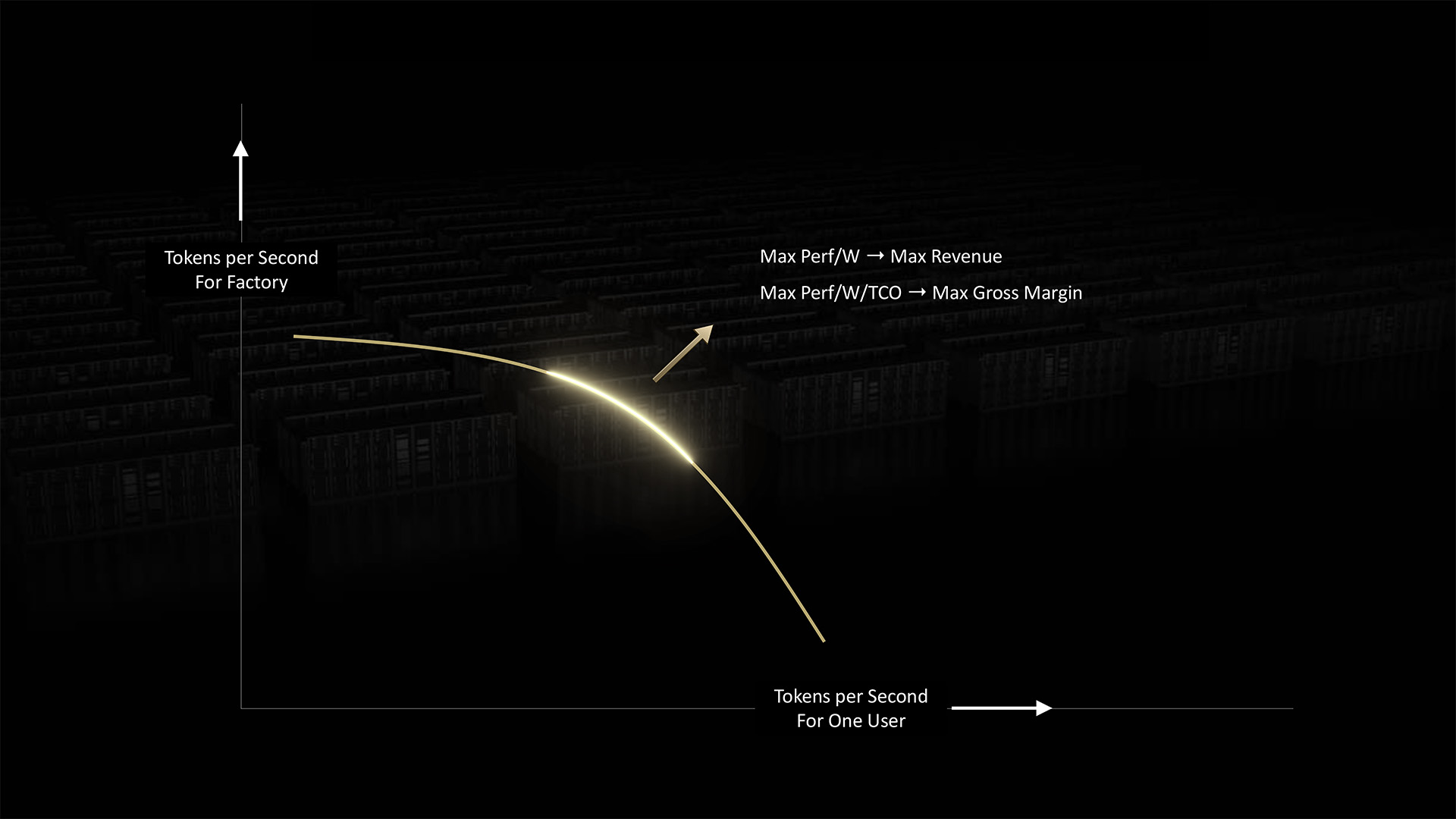
AI factories have to balance two competing demands to deliver optimal inference: speed per user and overall system throughput.

CoreWeave, 200MW, USA, scaling globally
AI factories can improve both factors by scaling — to more FLOPS and higher bandwidth. They can group and process AI workloads to maximize productivity.
But ultimately, AI factories are limited by the power they can access.
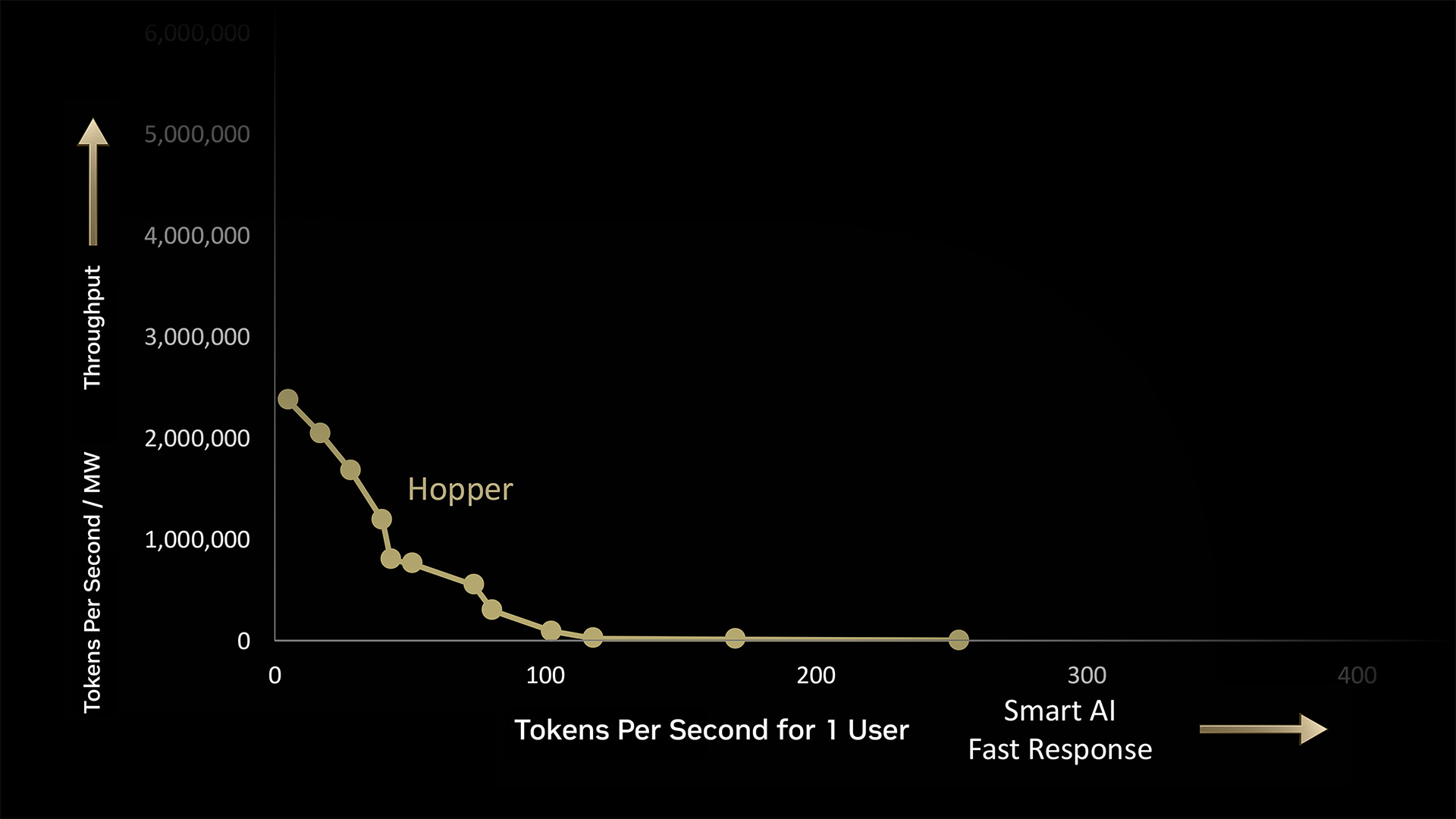
In a 1-megawatt AI factory, NVIDIA Hopper generates 180,000 tokens per second (TPS) at max volume, or 225 TPS for one user at the fastest.
But the real work happens in the space in between. Each dot along the curve represents batches of workloads for the AI factory to process — each with its own mix of performance demands.
NVIDIA GPUs have the flexibility to handle this full spectrum of workloads because they can be programmed using NVIDIA CUDA software.
The NVIDIA Blackwell architecture can do far more with 1 megawatt than the Hopper architecture — and there’s more coming. Optimizing the software and hardware stacks means Blackwell gets faster and more efficient over time.
Blackwell gets another boost when developers optimize the AI factory workloads autonomously with NVIDIA Dynamo, the new operating system for AI factories.
Dynamo breaks inference tasks into smaller components, dynamically routing and rerouting workloads to the most optimal compute resources available at that moment.
The improvements are remarkable. In a single generational leap of processor architecture from Hopper to Blackwell, we can achieve a 50x improvement in AI reasoning performance using the same amount of energy.
This is how NVIDIA full-stack integration and advanced software give customers massive speed and efficiency boosts in the time between chip architecture generations.
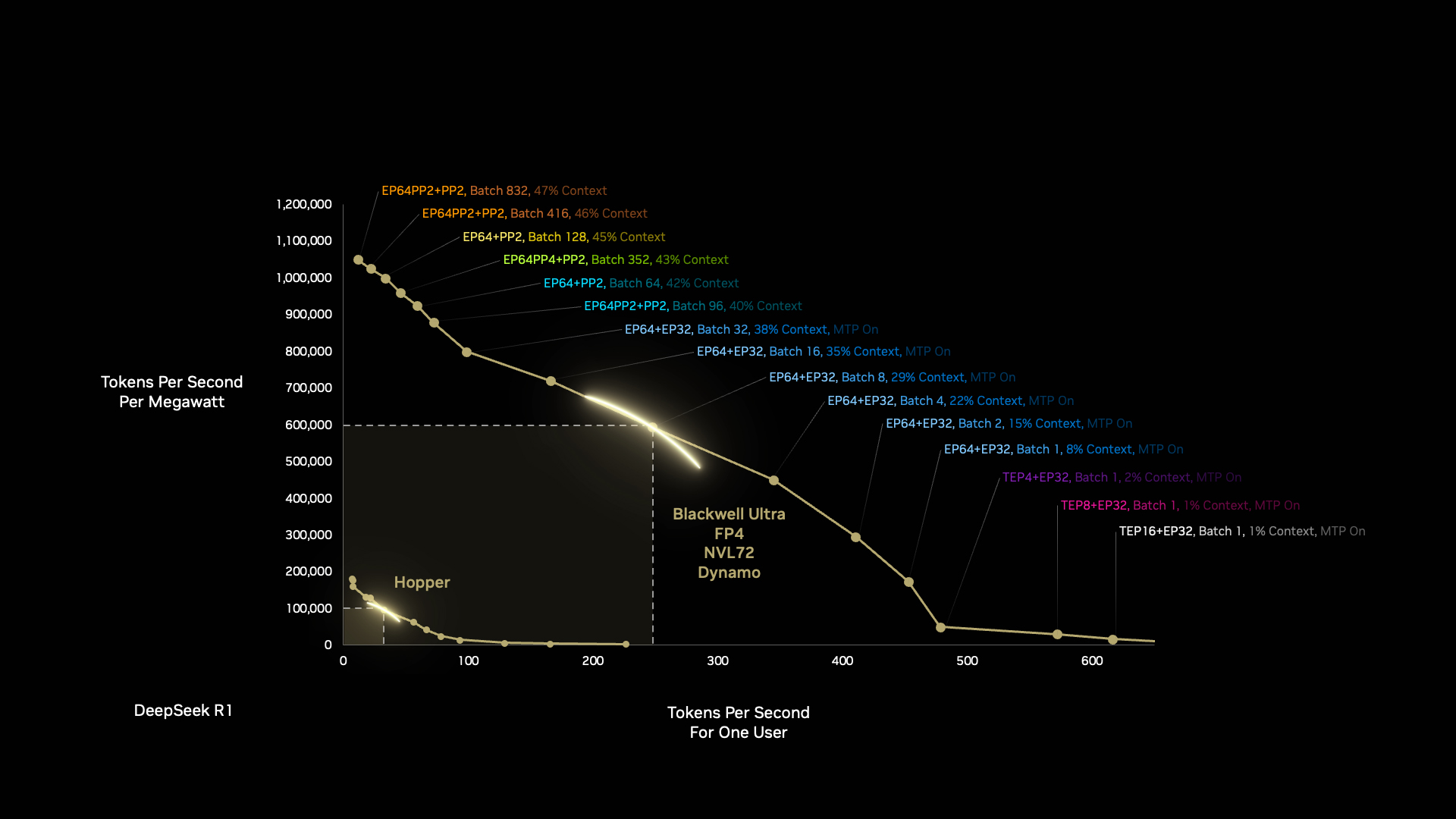
We push this curve outward with each generation, from hardware to software, from compute to networking.
And with each push forward in performance, AI can create trillions of dollars of productivity for NVIDIA’s partners and customers around the globe — while bringing us one step closer to curing diseases, reversing climate change and uncovering some of the greatest secrets of the universe.
This is compute turning into capital — and progress.
Related News



