The world’s top-performing system for graph processing at scale was built on a commercially available cluster.
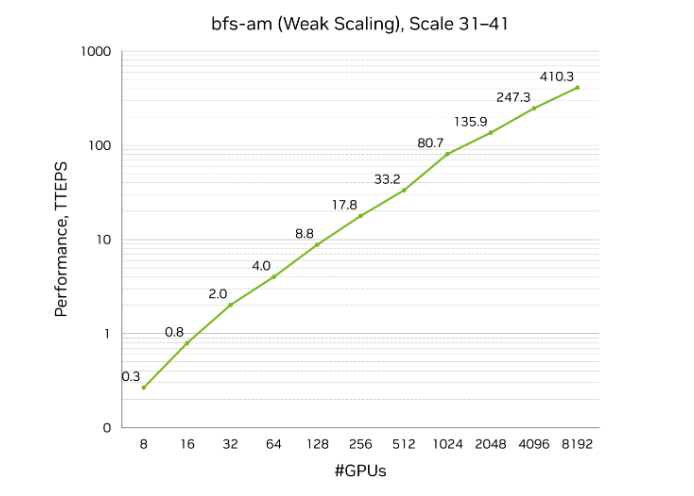
NVIDIA last month announced a record-breaking benchmark result of 410 trillion traversed edges per second (TEPS), ranking No. 1 on the 31st Graph500 breadth-first search (BFS) list.
Performed on an accelerated computing cluster hosted in a CoreWeave data center in Dallas, the winning run used 8,192 NVIDIA H100 GPUs to process a graph with 2.2 trillion vertices and 35 trillion edges. This result is more than double the performance of comparable solutions on the list, including those hosted in national labs.
To put this performance in perspective, say every person on Earth has 150 friends. This would represent 1.2 trillion edges in a graph of social relationships. The level of performance recently achieved by NVIDIA and CoreWeave enables searching through every friend relationship on Earth in just about three milliseconds.
Speed at that scale is half the story — the real breakthrough is efficiency. A comparable entry in the top 10 runs of the Graph500 list used about 9,000 nodes, while the winning run from NVIDIA used just over 1,000 nodes, delivering 3x better performance per dollar.
NVIDIA tapped into the combined power of its full-stack compute, networking and software technologies — including the NVIDIA CUDA platform, Spectrum-X networking, H100 GPUs and a new active messaging library — to push the boundaries of performance while minimizing hardware footprint.
By saving significant time and costs at this scale in a commercially available system, the win demonstrates how the NVIDIA computing platform is ready to democratize access to acceleration of the world’s largest sparse, irregular workloads — involving data and work items that come in varying and unpredictable sizes — in addition to dense workloads like AI training.
How Graphs at Scale Work
Graphs are the underlying information structure for modern technology. People interact with them on social networks and banking apps, among other use cases, every day. Graphs capture relationships between pieces of information in massive webs of information.
For example, consider LinkedIn. A user’s profile is a vertex. Connections or relationships to other users are edges — with other users represented as vertices. Some users have five connections, others have 50,000. This creates variable density across the graph, making it sparse and irregular. Unlike an image or language model, which is structured and dense, a graph is unpredictable.
Graph500 BFS has a long history as the industry-standard benchmark because it measures a system’s ability to navigate this irregularity at scale.
BFS measures the speed of traversing the graph through every vertex and edge. A high TEPS score for BFS — measuring how fast the system can process these edges — proves the system has superior interconnects, such as cables or switches between compute nodes, as well as more memory bandwidth and software able to take advantage of the system’s capabilities. It validates the engineering of the entire system, not just the speed of the CPU or GPU.
Effectively, it’s a measure of how fast a system can “think” and associate disparate pieces of information.
Current Techniques for Processing Graphs
GPUs are known for accelerating dense workloads like AI training. Until recently, the largest sparse linear algebra and graph workloads have remained the domain of traditional CPU architectures.
To process graphs, CPUs move graph data across compute nodes. As the graph scales to trillions of edges, this constant movement creates bottlenecks and jams communications.
Developers use a variety of software techniques to circumvent this issue. A common approach is to process the graph where it is with active messages, where developers send messages that can process graph data in place. The messages are smaller and can be grouped together to maximize network efficiency.
While this software technique significantly accelerates processing, active messaging was designed to run on CPUs and is inherently limited by the throughput rate and compute capabilities of CPU systems.
Reengineering Graph Processing for the GPU
To speed up the BFS run, NVIDIA engineered a full-stack, GPU-only solution that reimagines how data moves across the network.
A custom software framework developed using InfiniBand GPUDirect Async (IBGDA) and the NVSHMEM parallel programming interface enables GPU-to-GPU active messages.
With IBGDA, the GPU can directly communicate with the InfiniBand network interface card. Message aggregation has been engineered from the ground up to support hundreds of thousands of GPU threads sending active messages simultaneously, compared with just hundreds of threads on a CPU.
As such, in this redesigned system, active messaging runs completely on GPUs, bypassing the CPU.
This enables taking full advantage of the massive parallelism and memory bandwidth of NVIDIA H100 GPUs to send messages, move them across the network and process them on the receiver.
Running on the stable, high-performance infrastructure of NVIDIA partner CoreWeave, this orchestration enabled doubling the performance of comparable runs while using a fraction of the hardware — at a fraction of the cost.
Accelerating New Workloads
This breakthrough has massive implications for high-performance computing. HPC fields like fluid dynamics and weather forecasting rely on similar sparse data structures and communication patterns that power the graphs that underpin social networks and cybersecurity.
For decades, these fields have been tethered to CPUs at the largest scales, even as data scales from billions to trillions of edges. NVIDIA’s winning result on Graph500, alongside two other top 10 entries, validates a new approach for high-performance computing at scale.
With the full-stack orchestration of NVIDIA computing, networking and software, developers can now use technologies like NVSHMEM and IBGDA to efficiently scale their largest HPC applications, bringing supercomputing performance to commercially available infrastructure.
Stay up to date on the latest Graph500 benchmarks and learn more about NVIDIA networking technologies.

