Artificial intelligence on Windows 11 PCs marks a pivotal moment in tech history, revolutionizing experiences for gamers, creators, streamers, office workers, students and even casual PC users.
It offers unprecedented opportunities to enhance productivity for users of the more than 100 million Windows PCs and workstations that are powered by RTX GPUs. And NVIDIA RTX technology is making it even easier for developers to create AI applications to change the way people use computers.
New optimizations, models and resources announced at Microsoft Ignite will help developers deliver new end-user experiences, quicker.
An upcoming update to TensorRT-LLM — open-source software that increases AI inference performance — will add support for new large language models and make demanding AI workloads more accessible on desktops and laptops with RTX GPUs starting at 8GB of VRAM.
TensorRT-LLM for Windows will soon be compatible with OpenAI’s popular Chat API through a new wrapper. This will enable hundreds of developer projects and applications to run locally on a PC with RTX, instead of in the cloud — so users can keep private and proprietary data on Windows 11 PCs.
Custom generative AI requires time and energy to maintain projects. The process can become incredibly complex and time-consuming, especially when trying to collaborate and deploy across multiple environments and platforms.
AI Workbench is a unified, easy-to-use toolkit that allows developers to quickly create, test and customize pretrained generative AI models and LLMs on a PC or workstation. It provides developers a single platform to organize their AI projects and tune models to specific use cases.
This enables seamless collaboration and deployment for developers to create cost-effective, scalable generative AI models quickly. Join the early access list to be among the first to gain access to this growing initiative and to receive future updates.
To support AI developers, NVIDIA and Microsoft will release DirectML enhancements to accelerate one of the most popular foundational AI models, Llama 2. Developers now have more options for cross-vendor deployment, in addition to setting a new standard for performance.
Portable AI
Last month, NVIDIA announced TensorRT-LLM for Windows, a library for accelerating LLM inference.
The next TensorRT-LLM release, v0.6.0 coming later this month, will bring improved inference performance — up to 5x faster — and enable support for additional popular LLMs, including the new Mistral 7B and Nemotron-3 8B. Versions of these LLMs will run on any GeForce RTX 30 Series and 40 Series GPU with 8GB of RAM or more, making fast, accurate, local LLM capabilities accessible even in some of the most portable Windows devices.
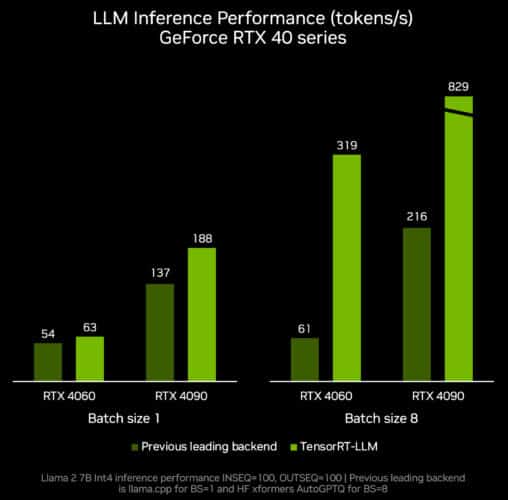
The new release of TensorRT-LLM will be available for install on the /NVIDIA/TensorRT-LLM GitHub repo. New optimized models will be available on ngc.nvidia.com.
Conversing With Confidence
Developers and enthusiasts worldwide use OpenAI’s Chat API for a wide range of applications — from summarizing web content and drafting documents and emails to analyzing and visualizing data and creating presentations.
One challenge with such cloud-based AIs is that they require users to upload their input data, making them impractical for private or proprietary data or for working with large datasets.
To address this challenge, NVIDIA is soon enabling TensorRT-LLM for Windows to offer a similar API interface to OpenAI’s widely popular ChatAPI, through a new wrapper, offering a similar workflow to developers whether they are designing models and applications to run locally on a PC with RTX or in the cloud. By changing just one or two lines of code, hundreds of AI-powered developer projects and applications can now benefit from fast, local AI. Users can keep their data on their PCs and not worry about uploading datasets to the cloud.
Perhaps the best part is that many of these projects and applications are open source, making it easy for developers to leverage and extend their capabilities to fuel the adoption of generative AI on Windows, powered by RTX.
The wrapper will work with any LLM that’s been optimized for TensorRT-LLM (for example, Llama 2, Mistral and Nemotron-3 8B) and is being released as a reference project on GitHub, alongside other developer resources for working with LLMs on RTX.
Model Acceleration
Developers can now leverage cutting-edge AI models and deploy with a cross-vendor API. As part of an ongoing commitment to empower developers, NVIDIA and Microsoft have been working together to accelerate Llama on RTX via the DirectML API.
Building on the announcements for the fastest inference performance for these models announced last month, this new option for cross-vendor deployment makes it easier than ever to bring AI capabilities to PC.
Developers and enthusiasts can experience the latest optimizations by downloading the latest ONNX runtime and following the installation instructions from Microsoft, and installing the latest driver from NVIDIA, which will be available on Nov. 21.
These new optimizations, models and resources will accelerate the development and deployment of AI features and applications to the 100 million RTX PCs worldwide, joining the more than 400 AI-powered apps and games already accelerated by RTX GPUs.
As models become even more accessible and developers bring more generative AI-powered functionality to RTX-powered Windows PCs, RTX GPUs will be critical for enabling users to take advantage of this powerful technology.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.