
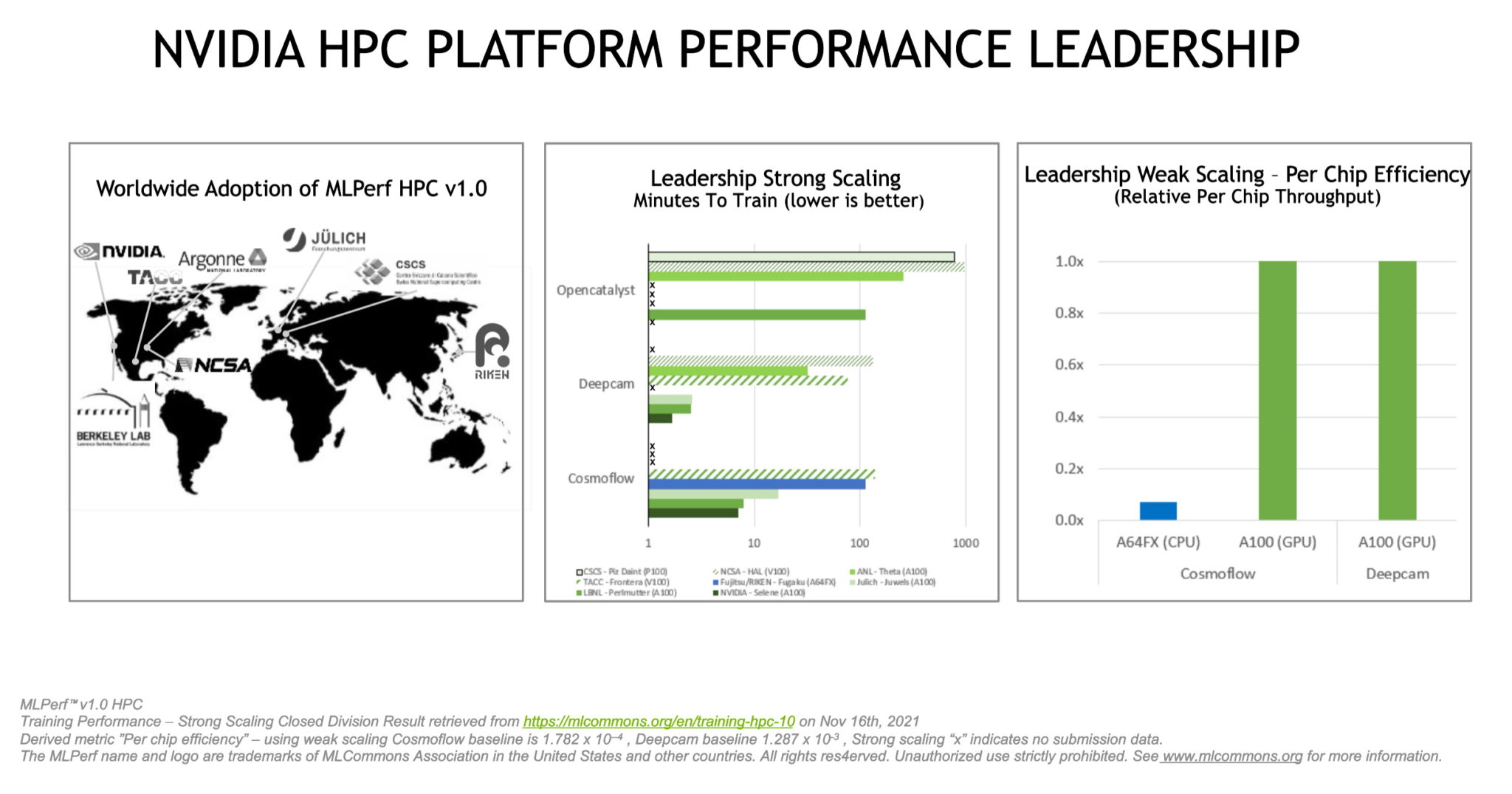
NVIDIA-powered systems won four of five tests in MLPerf HPC 1.0, an industry benchmark for AI performance on scientific applications in high performance computing.
They’re the latest results from MLPerf, a set of industry benchmarks for deep learning first released in May 2018. MLPerf HPC addresses a style of computing that speeds and augments simulations on supercomputers with AI.
Recent advances in molecular dynamics, astronomy and climate simulation all used HPC+AI to make scientific breakthroughs. It’s a trend driving the adoption of exascale AI for users in both science and industry.
What the Benchmarks Measure
MLPerf HPC 1.0 measured training of AI models in three typical workloads for HPC centers.
- CosmoFlow estimates details of objects in images from telescopes.
- DeepCAM tests detection of hurricanes and atmospheric rivers in climate data.
- OpenCatalyst tracks how well systems predict forces among atoms in molecules.
Each test has two parts. A measure of how fast a system trains a model is called strong scaling. Its counterpart, weak scaling, is a measure of maximum system throughput, that is, how many models a system can train in a given time.
Compared to the best results in strong scaling from last year’s MLPerf 0.7 round, NVIDIA delivered 5x better results for CosmoFlow. In DeepCAM, we delivered nearly 7x more performance.
The Perlmutter Phase 1 system at Lawrence Berkeley National Lab led in strong scaling in the OpenCatalyst benchmark using 512 of its 6,144 NVIDIA A100 Tensor Core GPUs.
In the weak-scaling category, we led DeepCAM using 16 nodes per job and 256 simultaneous jobs. All our tests ran on NVIDIA Selene (pictured above), our in-house system and the world’s largest industrial supercomputer.
The latest results demonstrate another dimension of the NVIDIA AI platform and its performance leadership. It marks the eighth straight time NVIDIA delivered top scores in MLPerf benchmarks that span AI training and inference in the data center, the cloud and the network’s edge.
A Broad Ecosystem
Seven of the eight participants in this round submitted results using NVIDIA GPUs.
They include the Jülich Supercomputing Centre in Germany, the Swiss National Supercomputing Centre and, in the U.S., the Argonne and Lawrence Berkeley National Laboratories, the National Center for Supercomputing Applications and the Texas Advanced Computing Center.
“With the benchmark test, we have shown that our machine can unfold its potential in practice and contribute to keeping Europe on the ball when it comes to AI,” said Thomas Lippert, director of the Jülich Supercomputing Centre in a blog.
The MLPerf benchmarks are backed by MLCommons, an industry group led by Alibaba, Google, Intel, Meta, NVIDIA and others.
How We Did It
The strong showing is the result of a mature NVIDIA AI platform that includes a full stack of software.
In this round, we tuned our code with tools available to everyone, such as NVIDIA DALI to accelerate data processing and CUDA Graphs to reduce small-batch latency for efficiently scaling up to 1,024 or more GPUs.
We also applied NVIDIA SHARP, a key component within NVIDIA MagnumIO. It provides in-network computing to accelerate communications and offload data operations to the NVIDIA Quantum InfiniBand switch.
For a deeper dive into how we used these tools see our developer blog.
All the software we used for our submissions is available from the MLPerf repository. We regularly add such code to the NGC catalog, our software hub for pretrained AI models, industry application frameworks, GPU applications and other software resources.



