If you’ve ever played the game Jenga, you’ll have some sense of sparsity in AI and machine learning.
Players stack wooden blocks in crisscross fashion into a column. Then each player takes a turn carefully removing one block, without tipping the column.
It starts off easy but gets increasingly hairy until the losing player pulls out a block that sends the tower crashing down.
What Is Sparsity in AI?
In AI inference and machine learning, sparsity refers to a matrix of numbers that includes many zeros or values that will not significantly impact a calculation.
For years, researchers in machine learning have been playing a kind of Jenga with numbers in their efforts to accelerate AI using sparsity. They try to pull out of a neural network as many unneeded parameters as possible — without unraveling AI’s uncanny accuracy.
The goal is to reduce the mounds of matrix multiplication deep learning requires, shortening the time to good results. So far, there have been no big winners.
To date, researchers have tried a variety of techniques to pull out as many as 95 percent of the weights in a neural network. But then, spending more time than they’d saved, they’re forced to craft heroic steps to claw back the accuracy of the streamlined model. And the steps that have worked for one model haven’t worked on others.
Until today.
Sparsity by the Numbers
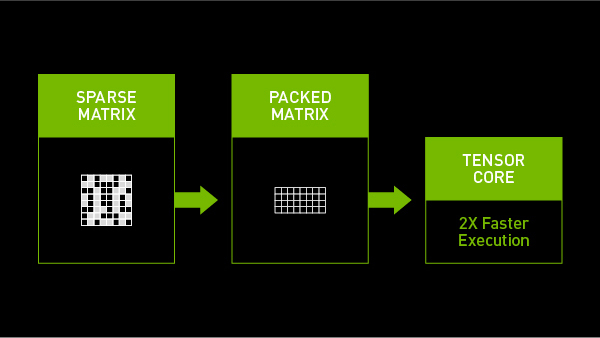
The NVIDIA Ampere architecture introduces third-generation Tensor Cores in NVIDIA A100 GPUs that take advantage of the fine-grained sparsity in network weights. They offer up to 2x the maximum throughput of dense math without sacrificing accuracy of the matrix multiply-accumulate jobs at the heart of deep learning.
Tests show this approach to sparsity maintains the accuracy of approaches using dense math on a wide variety of AI tasks including image classification, object detection and language translation. It’s also been tested across convolutional and recurrent neural networks as well as attention-based transformers.
The internal math speed ups have significant impacts at the application level. Using sparsity, an A100 GPU can run BERT (Bidirectional Encoder Representations from Transformers), the state-of-the-art model for natural-language processing, 50% faster than with dense math.
The NVIDIA Ampere architecture takes advantage of the prevalence of small values in neural networks in a way that benefits the widest possible swath of AI applications. Specifically, it defines a method for training a neural network with half its weights removed, or what’s known as 50 percent sparsity.
Less Is More, When You Do It Right
Some researchers use coarse-grained pruning techniques that can cut whole channels from a neural network layer, often lowering the network’s accuracy. The approach in the NVIDIA Ampere architecture employs structured sparsity with a fine-grained pruning technique that won’t noticeably reduce accuracy, something users can validate when they retrain their models.
Once a network is suitably pruned, an A100 GPU automates the rest of the work.
Tensor Cores in the A100 GPU efficiently compress sparse matrices to enable the appropriate dense math. Skipping what are effectively zero-value locations in a matrix reduces computing, saving power as well as time. Compressing sparse matrices also reduces the use of precious memory and bandwidth.
To get the big picture on the role of sparsity in our latest GPUs, watch the keynote with NVIDIA CEO and founder Jensen Huang. To learn even more, register for the webinar on sparsity or read a detailed article that takes a deep dive into the NVIDIA Ampere architecture.
Our support for sparsity is among a wide array of new capabilities in the NVIDIA Ampere architecture driving AI and HPC performance to new heights. For more details, check out our blogs on:
- TensorFloat-32 (TF32), a precision format, accelerating AI training and certain HPC jobs up to 20x.
- Double Precision Tensor Cores, speeding HPC simulations and AI up to 2.5x.
- Multi-Instance GPU (MIG), supporting up to 7x in GPU productivity gains.
- Or, see our website describing the NVIDIA A100 GPU.