Idea generation, not hardware or software, needs to be the bottleneck to the advancement of AI, Bryan Catanzaro, vice president of applied deep learning research at NVIDIA, said this week at the AI Hardware Summit.
“We want the inventors, the researchers and the engineers that are coming up with future AI to be limited only by their own thoughts,” Catanzaro told the audience.
Catanzaro leads a team of researchers working to apply the power of deep learning to everything from video games to chip design. At the annual event held in Silicon Valley, he described the work that NVIDIA is doing to enable advancements in AI, with a focus on large language modeling.
CUDA Is for the Dreamers
Training and deploying large neural networks is a tough computational problem, so hardware that’s both incredibly fast and highly efficient is a necessity, according to Catanzaro.
But, he explained, the software that accompanies that hardware might be even more important to unlocking further advancements in AI.
“The core of the work that we do involves optimizing hardware and software together, all the way from chips, to systems, to software, frameworks, libraries, compilers, algorithms and applications,” he said. “We optimize all of these things to give transformational capabilities to scientists, researchers and engineers around the world.”
This end-to-end approach yields chart-topping performance in industry-standard benchmarks, such as MLPerf. It also ensures that developers aren’t constrained by the platform as they aim to advance AI.
“CUDA is for the dreamers, CUDA is for the people who are thinking new thoughts,” said Catanzaro. “How do they think those thoughts and test them efficiently? They need something general and flexible, and that’s why we build what we build.”
Large Language Models Are Changing the World
One of the most exciting areas of AI is language modeling, which is enabling groundbreaking applications in natural language understanding and conversational AI.
The complexity of large language models is growing at an incredible rate, with parameter counts doubling every two months.
A well-known example of a large and powerful language model is GPT-3, developed by OpenAI. Packing 175 billion parameters, it required 314 zettaflops (1021 floating point operations) to train.
“It’s a staggering amount of compute,” Catanzaro said. “And that means language modeling is now becoming constrained by economics.”
Estimates suggest that GPT-3 would cost about $12 million to train and, Catanzaro observed, the rapid growth in model complexity means that, despite NVIDIA’s tireless work to advance the performance and efficiency of its hardware and software, the cost to train these models is set to grow.
And, according to Catanzaro, this trend suggests that it might not be too long before a single model might require more than a billion dollars’ worth of computer time to train.
“What would it look like to build a model that took a billion dollars to train a single model? Well, it would need to reinvent an entire company, and you’d need to be able to use it in a lot of different contexts,” Catanzaro explained.
Catanzaro expects that these models will unlock an incredible amount of value, inspiring continued innovation. During his talk, Catanzaro showed an example of the surprising capabilities of large language models to solve new tasks without being explicitly trained to do so.
After inputting just a few examples into a large language model — four sentences, with two written in English and their corresponding translations into Spanish — he then entered an English sentence, which the model then translated into Spanish properly.
The model was able to do this despite never being trained to do translation. Instead, it was trained — using, as Catanzaro described, “an enormous amount of data from the internet” — to predict the next word that should follow a given sequence of text.
To perform that very generic task, the model needed to come up with higher-level representations of concepts, such as the existence of languages in general, English and Spanish vocabularies and grammar, and the concept of a translation task, in order to understand the query and properly respond.
“These language models are first steps towards generalized artificial intelligence with few shot learning, and that is enormously valuable and very exciting,” explained Catanzaro.
A Full-Stack Approach to Language Modeling
Catanzaro then went on to describe NVIDIA Megatron, a framework created by NVIDIA using PyTorch “for efficiently training the world’s largest, transformer-based language models.”
A key feature of NVIDIA Megatron, which Catanzaro notes has already been used by various companies and organizations to train large transformer-based models, is model parallelism.
Megatron supports both inter-layer (pipeline) parallelism, which allows different layers of a model to be processed on different devices, as well as intra-layer (tensor) parallelism, which allows a single layer to be processed by multiple different devices.
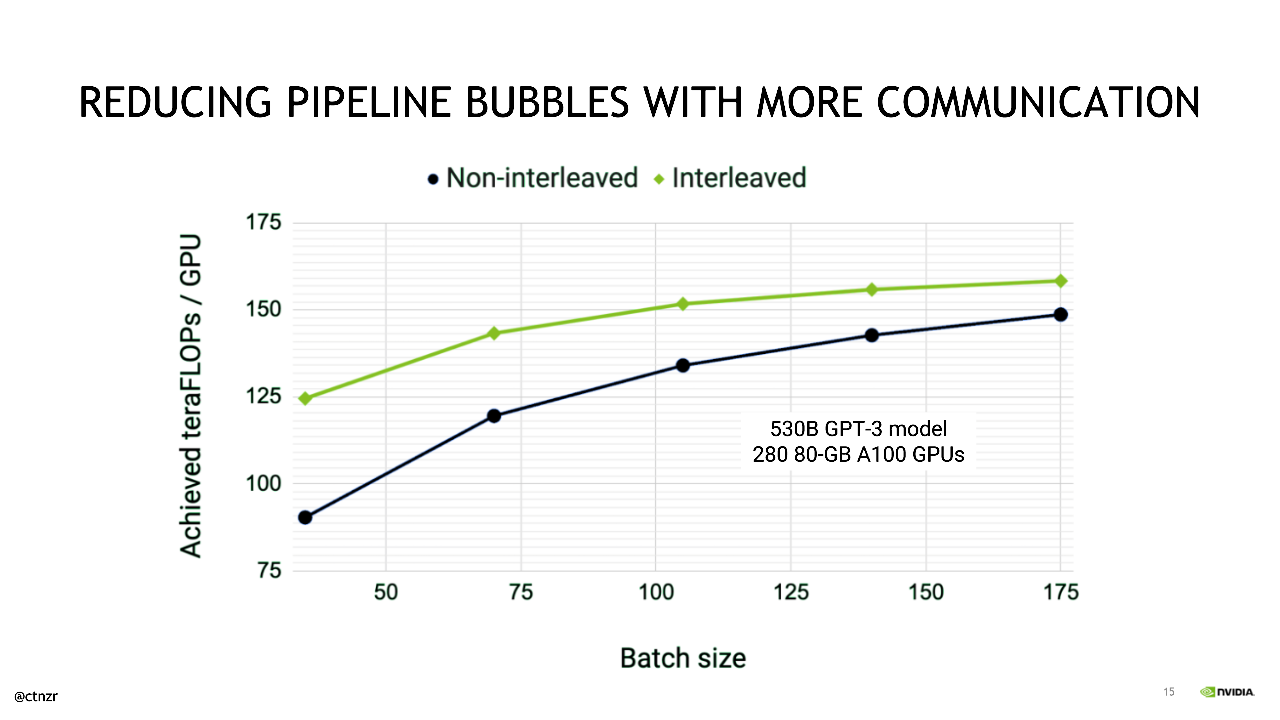
Catanzaro further described some of the optimizations that NVIDIA applies to maximize the efficiency of pipeline parallelism and minimize so-called “pipeline bubbles,” during which a GPU is not performing useful work.
A batch is split into microbatches, the execution of which is pipelined. This boosts the utilization of the GPU resources in a system during training. With further optimizations, pipeline bubbles can be reduced even more.
Catanzaro described an optimization, recently published, that entails “round-robining each (pipeline) stage among multiple GPUs so that we can further reduce the amount of pipeline bubble overhead in this schedule.”
Although this optimization puts additional stress on the communication fabric within the system, Catanzaro showed that, by leveraging the full suite of NVIDIA’s high-bandwidth, low-latency interconnect technologies, this optimization is able to deliver sizable speedups when training GPT-3 style models.
Catanzaro then highlighted the impressive performance scaling of Megatron on NVIDIA DGX SuperPOD, achieving 502 petaflops sustained across 3,072 GPUs, representing an astonishing 52 percent of Tensor Core peak at scale.
“This represents an achievement by all of NVIDIA and our partners in the industry: to be able to deliver that level of end-to-end performance requires optimizing the entire computing stack, from algorithms to interconnects, from frameworks to processors,” said Catanzaro.


