


NVIDIA Research Unlocks Advanced Grasping, Smarter Autonomous Driving and Agent Training at Scale
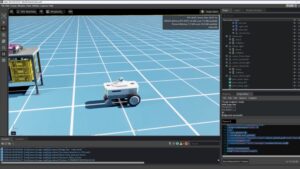
What makes a robot gripper useful isn’t that it can pick up one object — it’s that it can pick up the next one, and the one after that, with...

A car pulls up to the curb. The app says, “Your ride is here.” No one’s in the driver’s seat. For people who live in...
What makes a robot gripper useful isn’t that it can pick up one object — it’s that it can pick up the next one, and the one after that, with...

At CES, Caterpillar reveals how it’s integrating NVIDIA technologies, from NVIDIA Jetson Thor to speech models, to transform the world’s heavy industries....

NVIDIA founder and CEO Jensen Huang took the stage at the Fontainebleau Las Vegas to open CES 2026, declaring that AI is scaling into every domain and every device. “Computing...

At the CES trade show running this week in Las Vegas, NVIDIA announced that the global DRIVE Hyperion ecosystem is expanding to include tier 1 suppliers, automotive integrators and sensor...

NVIDIA is enabling a new era of AI-defined driving, bringing its NVIDIA DRIVE AV software with enhanced level 2 point-to-point driver assistance capabilities to U.S. roads, expected by end of...

Expanding the open model universe, NVIDIA today released new open models, data and tools to advance AI across every industry. These models — spanning the NVIDIA Nemotron family for agentic...

Physical AI is moving from research labs into the real world, powering intelligent robots and autonomous vehicles (AVs) — such as robotaxis — that must reliably sense, reason and act...

Researchers worldwide rely on open-source technologies as the foundation of their work. To equip the community with the latest advancements in digital and physical AI, NVIDIA is further expanding its...

Monday, Oct. 27, 12:30 p.m. ET How Medium-Sized Cities Are Tackling AI Readiness 🔗 A panel discussion today at GTC Washington, D.C., highlighted a public-private initiative to invigorate the economy...

When the Society of Automotive Engineers established its framework for vehicle autonomy in 2014, it created the industry-standard roadmap for self-driving technology. The levels of automation progress from level 1...
