Remember after recess on a summer day, waiting at the back of a long line at the drinking fountain? Now imagine a multi-headed water fountain, flowing with cool goodness for all.
That’s the essence of the Multi-Instance GPU, or MIG, enabled in the NVIDIA Ampere architecture.
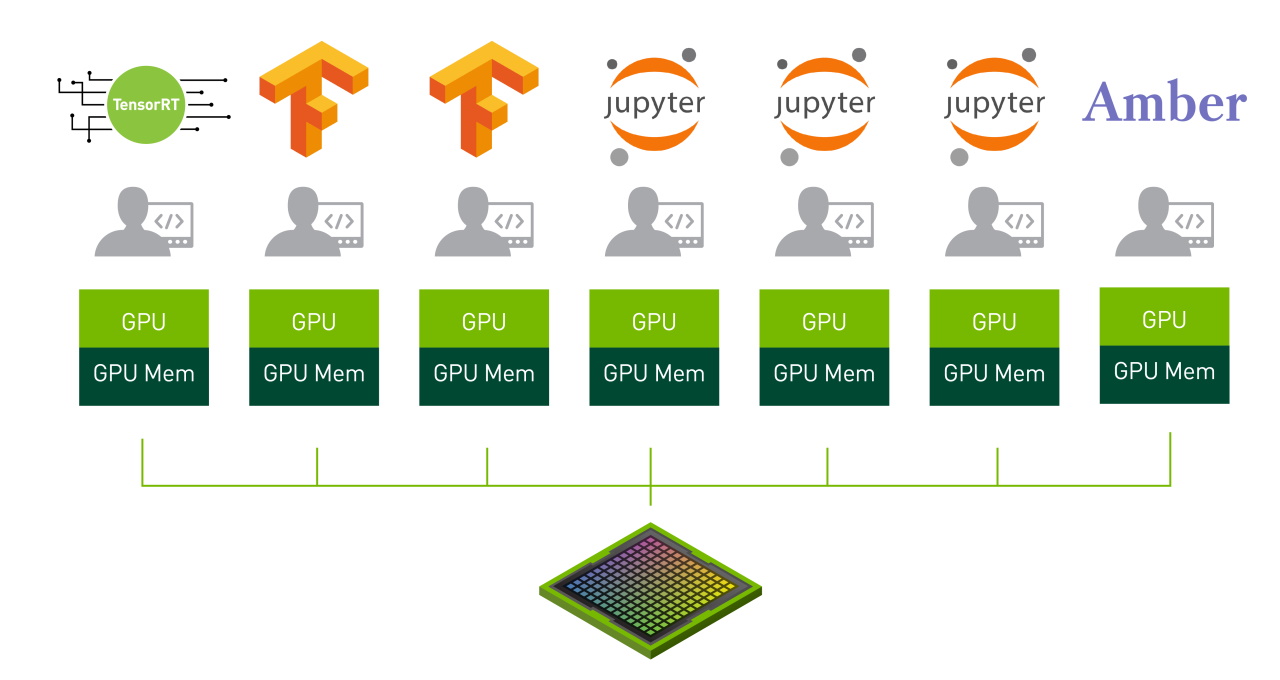
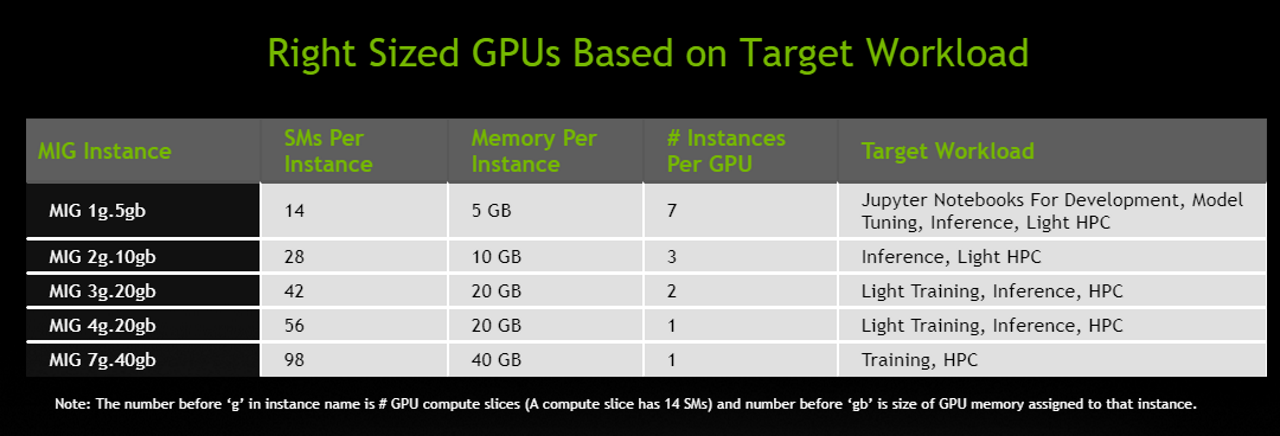
MIG partitions a single NVIDIA A100 GPU into as many as seven independent GPU instances. They run simultaneously, each with its own memory, cache and streaming multiprocessors. That enables the A100 GPU to deliver guaranteed quality-of-service (QoS) at up to 7x higher utilization compared to prior GPUs.
The A100 in MIG mode can run any mix of up to seven AI or HPC workloads of different sizes. The capability is especially useful for AI inference jobs that typically don’t demand all the performance a modern GPU delivers.
For example, users can create two MIG instances with 20 gigabytes (GB) of memory each, three instances with 10 GB or seven with 5 GB. Users create the mix that’s right for their workloads.
Because MIG walls off GPU instances, it provides fault isolation — a problem in one instance won’t affect others running on the same physical GPU. Each instance delivers guaranteed QoS, assuring users their workloads get the latency and throughput they expect.
Cloud service providers and other businesses can use MIG to raise utilization rates on their GPU servers, delivering users up to 7x more GPU instances.
“NVIDIA is a strategic partner for Google Cloud and we are excited for them to innovate on behalf of customers,” said Tim Hockin, Principal Software Engineer at Google Cloud.
“MIG makes it possible to reach new levels of efficiency and utilization of GPUs in shared Kubernetes clusters. We’re looking forward to working with NVIDIA and the Kubernetes community to enable these shared GPU use-cases, and make them available through the Google Kubernetes Engine,” Hockin said.
Businesses Make Inference Fly on MIG
For enterprise users, MIG speeds both development and deployment of AI models.
MIG gives up to seven data scientists simultaneous access to what feels like a dedicated GPU so they can work in parallel to fine-tune deep learning models for optimal accuracy and performance. It’s time-consuming work, but it often doesn’t require much compute capacity — a great use case for MIG.
Once models are ready to run, MIG lets a single GPU handle up to seven inference jobs at once. That’s ideal for batch-1 inference workloads that involve small, low-latency models that don’t need the muscle of a full GPU.
“NVIDIA technology is critical to Serve, our delivery robot platform,” said Zhenyu Guo, director of artificial intelligence at Postmates.
“MIG will enable us to get the most out of every GPU we deploy because it lets us dynamically reconfigure our compute resources to meet changing workload demands, optimizing our cloud-based infrastructure for maximum efficiency and cost savings,” he said.
Built for IT/DevOps
Users won’t have to change the CUDA programming model to get the benefits of MIG for AI and HPC. MIG works with existing Linux operating systems as well as Kubernetes and containers.
NVIDIA enables MIG with software it provides for its A100. That includes GPU drivers, NVIDIA’s CUDA 11 software (available soon), an updated NVIDIA container runtime and a new resource type in Kubernetes via the NVIDIA Device Plugin.
Using the NVIDIA Virtual Compute Server (vCS) in tandem with MIG, will deliver the management and monitoring goodness of hypervisors such as Red Hat Virtualization and VMware vSphere. The combination will support popular functions such as live migration and multi-tenancy.
“Our customers have an increasing need to manage multi-tenant workflows running on virtual machines while providing isolation and security benefits,” said Chuck Dubuque, Director of Marketing, Red Hat.
“The new multi-instance GPU capabilities on NVIDIA A100 GPUs enable a new range of AI-accelerated workloads that run on Red Hat platforms from the cloud to the edge,” he added.
With NVIDIA A100 and its software in place, users will be able to see and schedule jobs on their new GPU instances as if they were physical GPUs.
Where to Go to Learn More
To get the big picture on the role of MIG in A100 GPUs, watch the keynote with NVIDIA CEO and founder Jensen Huang. To learn even more, register for the MIG webinar or read a detailed article that takes a deep dive into the NVIDIA Ampere architecture.
MIG is among a battery of new capabilities in the NVIDIA Ampere architecture, driving AI training, inference and HPC performance to new heights. For more details, check out our blogs on:
- The TensorFloat-32 (TF32) accelerated format, speeds AI training and certain HPC jobs up to 20x.
- Double-Precision Tensor Cores, speeding HPC simulations and AI up to 2.5x
- Support for sparsity, driving 2x improvements in math throughput for AI inference.
- Or, see the web page describing the A100 GPU.