
Accelerated computing is humming in the background, making life better even on a quiet night at home.
It prevents credit card fraud when you buy a movie to stream. It recommends a dinner you might like and arranges a fast delivery. Maybe it even helped the movie’s director win an Oscar for stunning visuals.
So, What Is Accelerated Computing?
Accelerated computing is the use of specialized hardware to dramatically speed up work, using parallel processing that bundles frequently occurring tasks. It offloads demanding work that can bog down CPUs, processors that typically execute tasks in serial fashion.
Because accelerated computing on NVIDIA GPUs can do more work in less time, it’s energy efficient, consuming less energy than general-purpose servers that employ CPUs.
That’s why accelerated computing is sustainable computing. Users worldwide are documenting energy-efficiency gains with AI and accelerated computing.
Born in the PC, accelerated computing came of age in supercomputers. It lives today in your smartphone and every cloud service. And now companies of every stripe are adopting it to transform their businesses with data.
Accelerated computers blend CPUs and other kinds of processors together as equals in an architecture sometimes called heterogeneous computing.
Accelerated Computers: A Look Under the Hood
GPUs are the most widely used accelerators. Data processing units (DPUs) are a rapidly emerging class that enable enhanced, accelerated networking. Each has a role to play along with the host CPU to create a unified, balanced system.
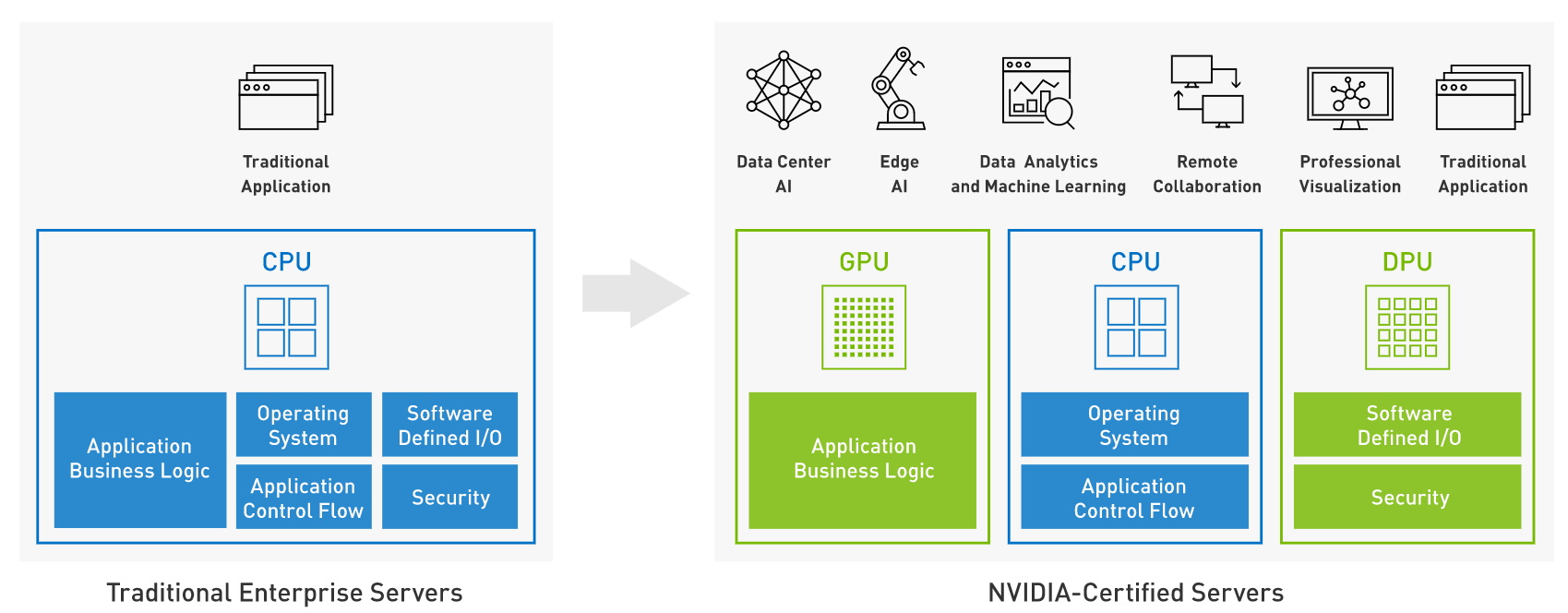
Both commercial and technical systems today embrace accelerated computing to handle jobs such as machine learning, data analytics, simulations and visualizations. It’s a modern style of computing that delivers high performance and energy efficiency.
How PCs Made Accelerated Computing Popular
Specialized hardware called co-processors have long appeared in computers to accelerate the work of a host CPU. They first gained prominence around 1980 with floating-point processors that added advanced math capabilities to the PC.
Over the next decade, the rise of video games and graphical user interfaces created demand for graphics accelerators. By 1993, nearly 50 companies were making graphics chips or cards.
In 1999, NVIDIA launched the GeForce 256, the first chip to offload from the CPU key tasks for rendering 3D images. It was also the first to use four graphics pipelines for parallel processing.
NVIDIA called it a graphics processing unit (GPU), putting a stake in the ground for a new category of computer accelerators.
How Researchers Harnessed Parallel Processing
By 2006, NVIDIA had shipped 500 million GPUs. It led a field of just three graphics vendors and saw the next big thing on the horizon.
Some researchers were already developing their own code to apply the power of GPUs to tasks beyond the reach of CPUs. For example, a team at Stanford led by Ian Buck unveiled Brook, the first widely adopted programming model to extend the popular C language for parallel processing.
Buck started at NVIDIA as an intern and now serves as vice president of accelerated computing. In 2006, he led the launch of CUDA, a programming model to harness the parallel-processing engines inside the GPU for any task.
Teamed with a G80 processor in 2007, CUDA powered a new line of NVIDIA GPUs that brought accelerated computing to an expanding array of industrial and scientific applications.
HPC + GPUs = Accelerated Science
This family of GPUs destined for the data center expanded on a regular cadence with a succession of new architectures named after innovators — Tesla, Fermi, Kepler, Maxwell, Pascal, Volta, Turing, Ampere, Hopper and Blackwell.
Like the graphics accelerators of the 1990s, these new GPUs faced many rivals, including novel parallel processors such as the transputer from Inmos.
“But only the GPU survived because the others had no software ecosystem and that was their death knell,” said Kevin Krewell, an analyst at Tirias Research.
Experts in high performance computing around the world built accelerated HPC systems with GPUs to pioneer science. Their work today spans fields from the astrophysics of black holes to genome sequencing and beyond.
Indeed, Oak Ridge National Lab even published a guide to accelerated computing for HPC users.
InfiniBand Revs Accelerated Networks
Many of these supercomputers use InfiniBand, a fast, low-latency link ideal for creating large, distributed networks of GPUs. Seeing the importance of accelerated networking, NVIDIA acquired Mellanox, a pioneer of InfiniBand, in April 2020.
Just six months later, NVIDIA announced its first DPU, a data processor that defines a new level of security, storage and network acceleration. A roadmap of BlueField DPUs is already gaining traction in supercomputers, cloud services, OEM systems and third-party software.
By June 2021, 342 of the TOP500 fastest supercomputers in the world were using NVIDIA technologies, including 70 percent of all new systems and eight of the top 10.

To date, the CUDA ecosystem has spawned more than 700 accelerated applications, tackling grand challenges like drug discovery, disaster response and even plans for missions to Mars.
Meanwhile, accelerated computing also enabled the next big leap in graphics. In 2018, NVIDIA’s Turing architecture powered GeForce RTX GPUs, the first to deliver ray tracing, a holy grail of visual technology, giving games and simulations lifelike realism.
AI, a Killer App for Accelerated Computing
In 2012, the tech world heard a Big Bang, signaling a new and powerful form of computing had arrived, AI.
Under the covers, it’s a parallel processing job. From the early days of deep learning, researchers and cloud-service providers discovered GPU-accelerated computers were ideal for AI.
Leading companies across every vertical market quickly saw the significance of AI on accelerated computers.
- American Express uses it to prevent credit card fraud.
- Cloud services use it in recommender systems that drive sales.
- Many companies use conversational AI to improve customer service.
- Telcos are exploring AI to deliver smart 5G services.
- Movie makers used it to make Robert DeNiro and Al Pacino look younger in The Irishman.
- And you can watch it while eating dinner suggested and delivered thanks to the AI smarts of DoorDash or Domino’s.
Some day, every company will be a data company, and every server will be an accelerated computer.
It’s a vision shared by the leaders of mainstream IT software companies like VMware and Red Hat, which are tailoring their products for accelerated computing. System makers are already delivering dozens of NVIDIA-Certified Systems, accelerated computers ready to go to work for every business.
They are vehicles for the journey to accelerated computing in the enterprise. To help pave the onramp, NVIDIA is delivering a full stack solution with products such as NVIDIA AI Enterprise, and NVIDIA NIM, an optimized and accelerated API for AI inference.
“Figuring out how to do more while using less power is the key to driving flexibility, scalability and sustainability,” said NVIDIA founder and CEO Jensen Huang. “Given this, every data center in the world should be accelerated.”
An Energy-Efficient Future
Accelerated computing “is the only path forward,” according to computing veterans like John Hennessey and David Patterson. They described the trend as a move to “domain-specific architectures” in a talk commemorating their 2017 Turing award, the equivalent of a Nobel in computing.
The energy efficiency of the approach is an important reason why it represents the future. For example, GPUs deliver 20x better energy efficiency on AI inference than CPUs.
Indeed, if you switched all the CPU-only servers running AI worldwide to GPU-accelerated systems, you could save a whopping 10 trillion watt-hours of energy a year. That’s like saving the energy 1.4 million homes consume in a year (see chart below).
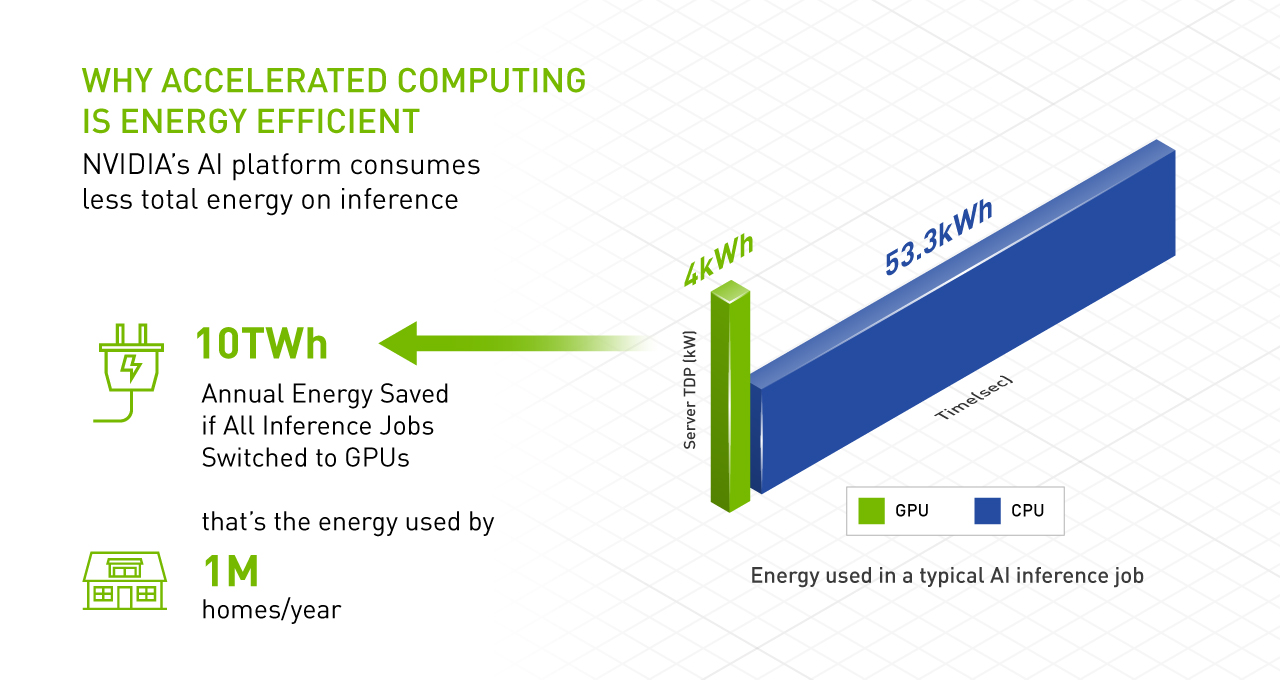
Experts in accelerated computing are already reaping these benefits.
In a recent ranking of the world’s most energy-efficient supercomputers, known as the Green500, NVIDIA-powered systems swept the top six spots, and 40 of the top 50. Supercomputers on the list that use NVIDIA GPUs are 5x more energy efficient than ones that don’t, a consistent and growing trend.
For more information, visit the NVIDIA Technical Blog and watch the video on enterprise accelerated computing below.

