
Quantum computing. Drug discovery. Fusion energy. Scientific computing and physics-based simulations are poised to make giant steps across domains that benefit humanity as advances in accelerated computing and AI drive the world’s next big breakthroughs.
NVIDIA unveiled at GTC in March the NVIDIA Blackwell platform, which promises generative AI on trillion-parameter large language models (LLMs) at up to 25x less cost and energy consumption than the NVIDIA Hopper architecture.
Blackwell has powerful implications for AI workloads, and its technology capabilities can also help to deliver discoveries across all types of scientific computing applications, including traditional numerical simulation.
By reducing energy costs, accelerated computing and AI drive sustainable computing. Many scientific computing applications already benefit. Weather can be simulated at 200x lower cost and with 300x less energy, while digital twin simulations have 65x lower cost and 58x less energy consumption versus traditional CPU-based systems and others.
Multiplying Scientific Computing Simulations With Blackwell
Scientific computing and physics-based simulation often rely on what’s known as double-precision formats, or FP64 (floating point), to solve problems. Blackwell GPUs deliver 30% more FP64 and FP32 FMA (fused multiply-add) performance than Hopper.
Physics-based simulations are critical to product design and development. From planes and trains to bridges, silicon chips and pharmaceuticals — testing and improving products in simulation saves researchers and developers billions of dollars.
Today application-specific integrated circuits (ASICs) are designed almost exclusively on CPUs in a long and complex workflow, including analog analysis to identify voltages and currents.
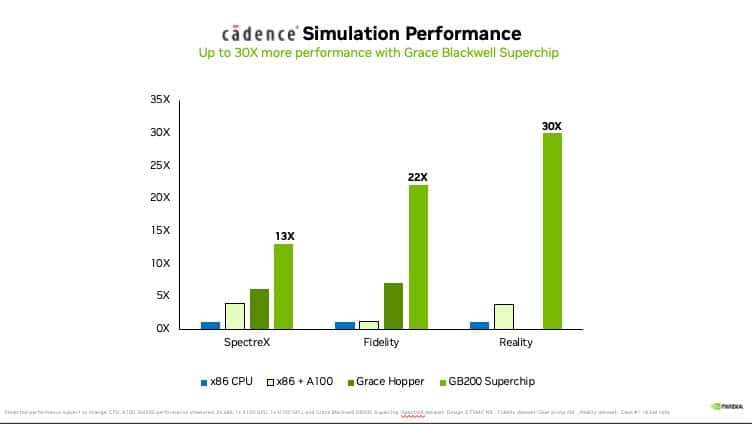
But that’s changing. The Cadence SpectreX simulator is one example of an analog circuit design solver. SpectreX circuit simulations are projected to run 13x quicker on a GB200 Grace Blackwell Superchip — which connects Blackwell GPUs and Grace CPUs — than on a traditional CPU.
Also, GPU-accelerated computational fluid dynamics, or CFD, has become a key tool. Engineers and equipment designers use it to predict the behavior of designs. Cadence Fidelity runs CFD simulations that are projected to run as much as 22x faster on GB200 systems than on traditional CPU-powered systems. With parallel scalability and 30TB of memory per GB200 NVL72 rack, it’s possible to capture flow details like never before.
In another application, Cadence Reality’s digital twin software can be used to create a virtual replica of a physical data center, including all its components — servers, cooling systems and power supplies. Such a virtual model allows engineers to test different configurations and scenarios before implementing them in the real world, saving time and costs.
Cadence Reality’s magic happens from physics-based algorithms that can simulate how heat, airflow and power usage affect data centers. This helps engineers and data center operators to more effectively manage capacity, predict potential operational problems and make informed decisions to optimize the layout and operation of the data center for improved efficiency and capacity utilization. With Blackwell GPUs, these simulations are projected to run up to 30x faster than with CPUs, offering accelerated timelines and higher energy efficiency.
AI for Scientific Computing
New Blackwell accelerators and networking will deliver leaps in performance for advanced simulation.
The NVIDIA GB200 kicks off a new era for high-performance computing (HPC). Its architecture sports a second-generation transformer engine optimized to accelerate inference workloads for LLMs.
This delivers a 30x speedup on resource-intensive applications like the 1.8-trillion-parameter GPT-MoE (generative pretrained transformer-mixture of experts) model compared to the H100 generation, unlocking new possibilities for HPC. By enabling LLMs to process and decipher vast amounts of scientific data, HPC applications can sooner reach valuable insights that can accelerate scientific discovery.
Sandia National Laboratories is building an LLM copilot for parallel programming. Traditional AI can generate basic serial computing code efficiently, but when it comes to parallel computing code for HPC applications, LLMs can falter. Sandia researchers are tackling this issue head-on with an ambitious project — automatically generating parallel code in Kokkos, a specialized programming language designed by multiple national labs for running tasks across tens of thousands of processors in the world’s most powerful supercomputers.
Sandia is using an AI technique known as retrieval-augmented generation, or RAG, which combines information-retrieval capabilities with language generation models. The team is creating a Kokkos database and integrating it with AI models using RAG.
Initial results are promising. Different RAG approaches from Sandia have demonstrated autonomously generated Kokkos code for parallel computing applications. By overcoming hurdles in AI-based parallel code generation, Sandia aims to unlock new possibilities in HPC across leading supercomputing facilities worldwide. Other examples include renewables research, climate science and drug discovery.

Driving Quantum Computing Advances
Quantum computing unlocks a time machine trip for fusion energy, climate research, drug discovery and many more areas. So researchers are hard at work simulating future quantum computers on NVIDIA GPU-based systems and software to develop and test quantum algorithms faster than ever.
The NVIDIA CUDA-Q platform enables both simulation of quantum computers and hybrid application development with a unified programming model for CPUs, GPUs and QPUs (quantum processing units) working together.
CUDA-Q is speeding simulations in chemistry workflows for BASF, high-energy and nuclear physics for Stony Brook and quantum chemistry for NERSC.
NVIDIA Blackwell architecture will help drive quantum simulations to new heights. Utilizing the latest NVIDIA NVLink multi-node interconnect technology helps shuttle data faster for speedup benefits to quantum simulations.
Accelerating Data Analytics for Scientific Breakthroughs
Data processing with RAPIDS is popular for scientific computing. Blackwell introduces a hardware decompression engine to decompress compressed data and speed up analytics in RAPIDS.
The decompression engine provides performance improvements up to 800GB/s and enables Grace Blackwell to perform 18x faster than CPUs — on Sapphire Rapids — and 6x faster than NVIDIA H100 Tensor Core GPUs for query benchmarks.
Rocketing data transfers with 8TB/s of high-memory bandwidth and the Grace CPU high-speed NVLink Chip-to-Chip (C2C) interconnect, the engine speeds up the entire process of database queries. Yielding top-notch performance across data analytics and data science use cases, Blackwell speeds data insights and reduces costs.

Driving Extreme Performance for Scientific Computing with NVIDIA Networking
The NVIDIA Quantum-X800 InfiniBand networking platform offers the highest throughput for scientific computing infrastructure.
It includes NVIDIA Quantum Q3400 and Q3200 switches and the NVIDIA ConnectX-8 SuperNIC, together hitting twice the bandwidth of the prior generation. The Q3400 platform offers 5x higher bandwidth capacity and 14.4Tflops of in-network computing with NVIDIA’s scalable hierarchical aggregation and reduction protocol (SHARPv4), providing a 9x increase compared with the prior generation.
The performance leap and power efficiency translates to significant reductions in workload completion time and energy consumption for scientific computing.
Learn more about NVIDIA Blackwell.