In a talk, now available online, NVIDIA Chief Scientist Bill Dally describes a tectonic shift in how computer performance gets delivered in a post-Moore’s law era.
Each new processor requires ingenuity and effort inventing and validating fresh ingredients, he said in a recent keynote address at Hot Chips, an annual gathering of chip and systems engineers. That’s radically different from a generation ago, when engineers essentially relied on the physics of ever smaller, faster chips.
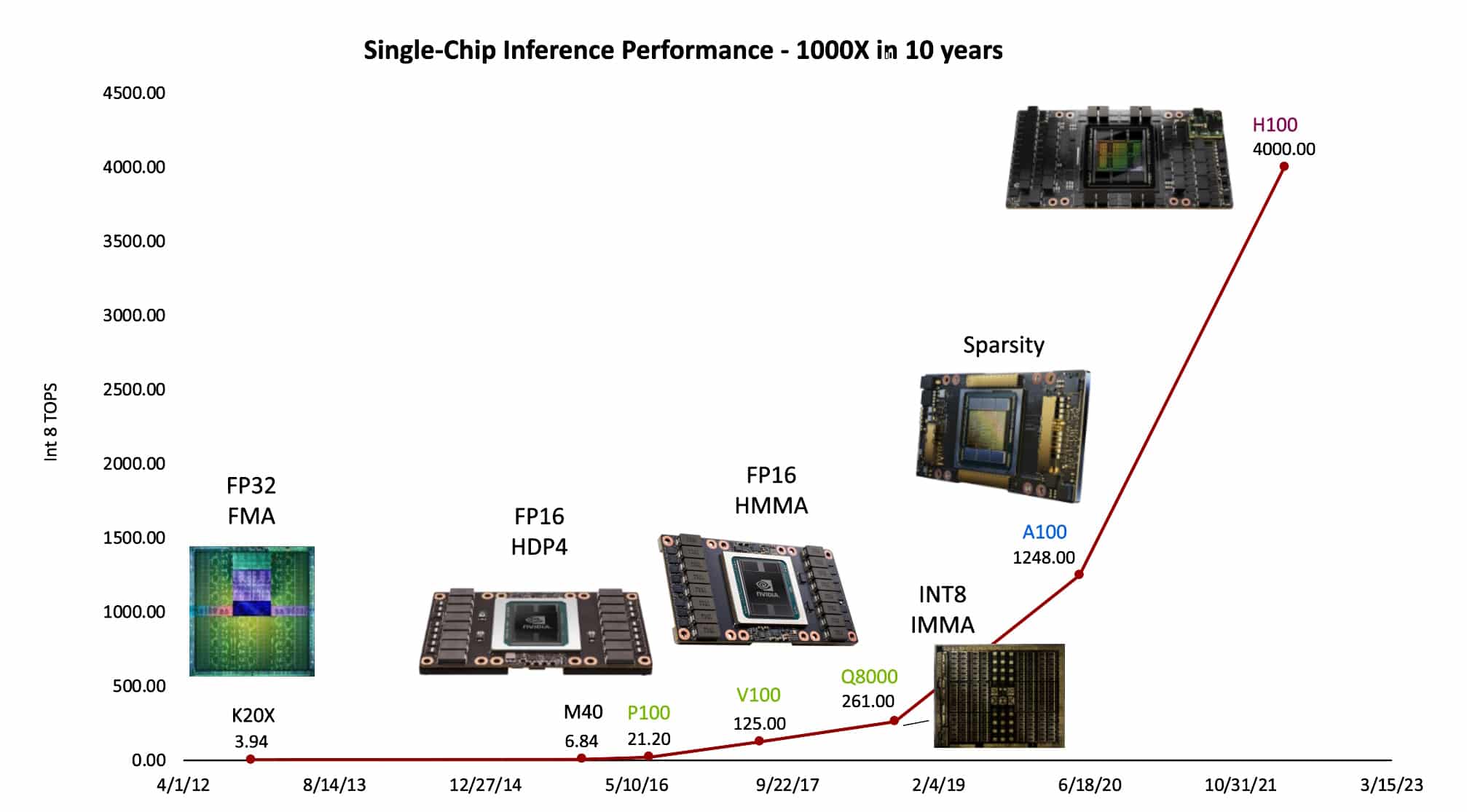
The team of more than 300 that Dally leads at NVIDIA Research helped deliver a whopping 1,000x improvement in single GPU performance on AI inference over the past decade (see chart below).
It’s an astounding increase that IEEE Spectrum was the first to dub “Huang’s Law” after NVIDIA founder and CEO Jensen Huang. The label was later popularized by a column in the Wall Street Journal.
The advance was a response to the equally phenomenal rise of large language models used for generative AI that are growing by an order of magnitude every year.
“That’s been setting the pace for us in the hardware industry because we feel we have to provide for this demand,” Dally said.
In his talk, Dally detailed the elements that drove the 1,000x gain.
The largest of all, a sixteen-fold gain, came from finding simpler ways to represent the numbers computers use to make their calculations.
The New Math
The latest NVIDIA Hopper architecture with its Transformer Engine uses a dynamic mix of eight- and 16-bit floating point and integer math. It’s tailored to the needs of today’s generative AI models. Dally detailed both the performance gains and the energy savings the new math delivers.
Separately, his team helped achieve a 12.5x leap by crafting advanced instructions that tell the GPU how to organize its work. These complex commands help execute more work with less energy.
As a result, computers can be “as efficient as dedicated accelerators, but retain all the programmability of GPUs,” he said.
In addition, the NVIDIA Ampere architecture added structural sparsity, an innovative way to simplify the weights in AI models without compromising the model’s accuracy. The technique brought another 2x performance increase and promises future advances, too, he said.
Dally described how NVLink interconnects between GPUs in a system and NVIDIA networking among systems compound the 1,000x gains in single GPU performance.
No Free Lunch
Though NVIDIA migrated GPUs from 28nm to 5nm semiconductor nodes over the decade, that technology only accounted for 2.5x of the total gains, Dally noted.
That’s a huge change from computer design a generation ago under Moore’s law, an observation that performance should double every two years as chips become ever smaller and faster.
Those gains were described in part by Denard scaling, essentially a physics formula defined in a 1974 paper co-authored by IBM scientist Robert Denard. Unfortunately, the physics of shrinking hit natural limits such as the amount of heat the ever smaller and faster devices could tolerate.
An Upbeat Outlook
Dally expressed confidence that Huang’s law will continue despite diminishing gains from Moore’s law.
For example, he outlined several opportunities for future advances in further simplifying how numbers are represented, creating more sparsity in AI models and designing better memory and communications circuits.
Because each new chip and system generation demands new innovations, “it’s a fun time to be a computer engineer,” he said.
Dally believes the new dynamic in computer design is giving NVIDIA’s engineers the three opportunities they desire most: to be part of a winning team, to work with smart people and to work on designs that have impact.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.