
As with all computing, you’ve got to get your math right to do AI well. Because deep learning is a young field, there’s still a lively debate about which types of math are needed, for both training and inferencing.
In November, we explained the differences among popular formats such as single-, double-, half-, multi- and mixed-precision math used in AI and high performance computing. Today, the NVIDIA Ampere architecture introduces a new approach for improving training performance on the single-precision models widely used for AI.
TensorFloat-32 is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations used at the heart of AI and certain HPC applications. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs. Combining TF32 with structured sparsity on the A100 enables performance gains over Volta of up to 20x.
Understanding the New Math
It helps to step back for a second to see how TF32 works and where it fits.
Math formats are like rulers. The number of bits in a format’s exponent determines its range, how large an object it can measure. Its precision — how fine the lines are on the ruler — comes from the number of bits used for its mantissa, the part of a floating point number after the radix or decimal point.
A good format strikes a balance. It should use enough bits to deliver precision without using so many it slows processing and bloats memory.
The chart below shows how TF32 is a hybrid that strikes this balance for tensor operations.
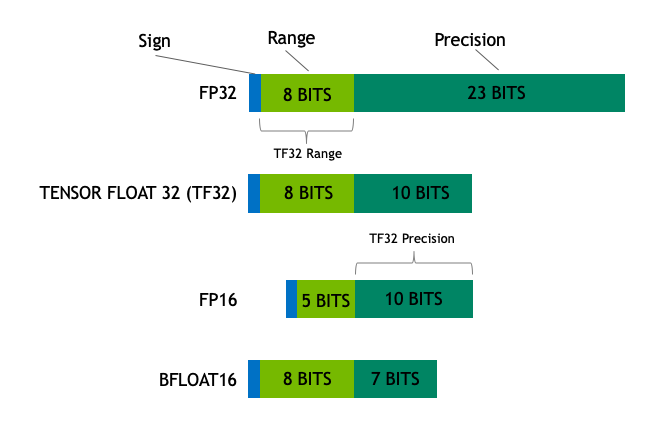
TF32 uses the same 10-bit mantissa as the half-precision (FP16) math, shown to have more than sufficient margin for the precision requirements of AI workloads. And TF32 adopts the same 8-bit exponent as FP32 so it can support the same numeric range.
The combination makes TF32 a great alternative to FP32 for crunching through single-precision math, specifically the massive multiply-accumulate functions at the heart of deep learning and many HPC apps.
Applications using NVIDIA libraries enable users to harness the benefits of TF32 with no code change required. TF32 Tensor Cores operate on FP32 inputs and produce results in FP32. Non-matrix operations continue to use FP32.
For maximum performance, the A100 also has enhanced 16-bit math capabilities. It supports both FP16 and Bfloat16 (BF16) at double the rate of TF32. Employing Automatic Mixed Precision, users can get a further 2x higher performance with just a few lines of code.
TF32 Is Demonstrating Great Results Today
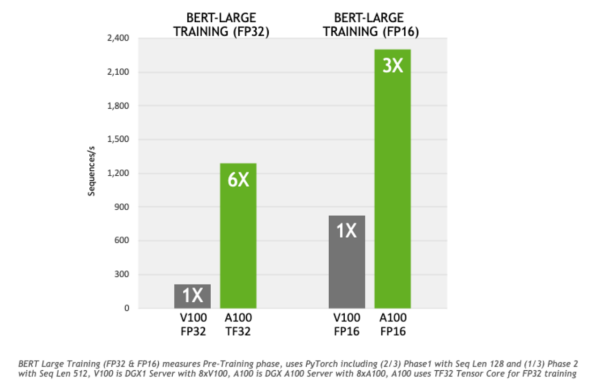
Compared to FP32, TF32 shows a 6x speedup training BERT, one of the most demanding conversational AI models. Applications-level results on other AI training and HPC apps that rely on matrix math will vary by workload.
To validate the accuracy of TF32, we used it to train a broad set of AI networks across a wide variety of applications from computer vision to natural language processing to recommender systems. All of them have the same convergence-to-accuracy behavior as FP32.
That’s why NVIDIA is making TF32 the default on its cuDNN library which accelerates key math operations for neural networks. At the same time, NVIDIA is working with the open-source communities that develop AI frameworks to enable TF32 as their default training mode on A100 GPUs, too.
In June, developers will be able to access a version of the TensorFlow framework and a version of the PyTorch framework with support for TF32 on NGC, NVIDIA’s catalog of GPU-accelerated software.
“TensorFloat-32 provides a huge out-of-the-box performance increase for AI applications for training and inference while preserving FP32 levels of accuracy,” said Kemal El Moujahid, director of Product Management for TensorFlow.
“We plan to make TensorFloat-32 supported natively in TensorFlow to enable data scientists to benefit from dramatically higher speedups in NVIDIA A100 Tensor Core GPUs without any code changes,” he added.
“Machine learning researchers, data scientists and engineers want to accelerate time to solution,” said a spokesperson for the PyTorch team. “When TF32 is natively integrated into PyTorch, it will enable out-of-the-box acceleration with zero code changes while maintaining accuracy of FP32 when using the NVIDIA Ampere architecture-based GPUs.”
TF32 Accelerates Linear Solvers in HPC
HPC apps called linear solvers — algorithms with repetitive matrix-math calculations — also will benefit from TF32. They’re used in a wide range of fields such as earth science, fluid dynamics, healthcare, material science and nuclear energy as well as oil and gas exploration.
Linear solvers using FP32 to achieve FP64 precision have been in use for more than 30 years. Last year, a fusion reaction study for the International Thermonuclear Experimental Reactor demonstrated that mixed-precision techniques delivered a speedup of 3.5x for such solvers using NVIDIA FP16 Tensor Cores. The same technology used in that study tripled the Summit supercomputer’s performance on the HPL-AI benchmark.
To demonstrate the power and robustness of TF32 for linear system solvers, we ran a variety of tests in the SuiteSparse matrix collection using cuSOLVER in CUDA 11.0 on the A100. In these tests, TF32 delivered the fastest and most robust results compared to other Tensor Core modes, including FP16 and BF16.
Beyond linear solvers, other domains in high performance computing make use of FP32 matrix operations. NVIDIA plans to work with the industry to study the application of TF32 to more use cases that rely on FP32 today.
Where to Go for More Information
To get the big picture on the role of TF32 in our latest GPUs, watch the keynote with NVIDIA founder and CEO Jensen Huang. To learn even more, register for webinars on mixed-precision training or CUDA math libraries or read a detailed article that takes a deep dive into the NVIDIA Ampere architecture.
TF32 is among a cluster of new capabilities in the NVIDIA Ampere architecture, driving AI and HPC performance to new heights. For more details, check out our blogs on:
- Our support for sparsity, driving up to 50 percent improvements for AI inference.
- Double-precision Tensor Cores, speeding HPC simulations up to 2.5x
- Multi-instance GPU (MIG), supporting up to 7x in GPU productivity gains.
- Or, see the web page describing the NVIDIA A100 GPU.