Data is the new oil in today’s age of AI, but only a lucky few are sitting on a gusher. So, many are making their own fuel, one that’s both inexpensive and effective. It’s called synthetic data.
What Is Synthetic Data?
Synthetic data is annotated information that computer simulations or algorithms generate as an alternative to real-world data.
Put another way, synthetic data is created in digital worlds rather than collected from or measured in the real world.
It may be artificial, but synthetic data reflects real-world data, mathematically or statistically. Research demonstrates it can be as good or even better for training an AI model than data based on actual objects, events or people.

That’s why developers of deep neural networks increasingly use synthetic data to train their models. Indeed, a survey of the field calls use of synthetic data “one of the most promising general techniques on the rise in modern deep learning, especially computer vision” that relies on unstructured data like images and video.
The 156-page report cites 719 papers on synthetic data. It concludes “synthetic data is essential for further development of deep learning … [and] many more potential use cases still remain” to be discovered.
The rise of synthetic data comes as AI pioneer Andrew Ng is calling for a broad shift to a more data-centric approach to machine learning. He’s rallying support for a benchmark or competition on data quality which many claim represents 80 percent of the work in AI.
“Most benchmarks provide a fixed set of data and invite researchers to iterate on the code … perhaps it’s time to hold the code fixed and invite researchers to improve the data,” he wrote in his newsletter, The Batch.
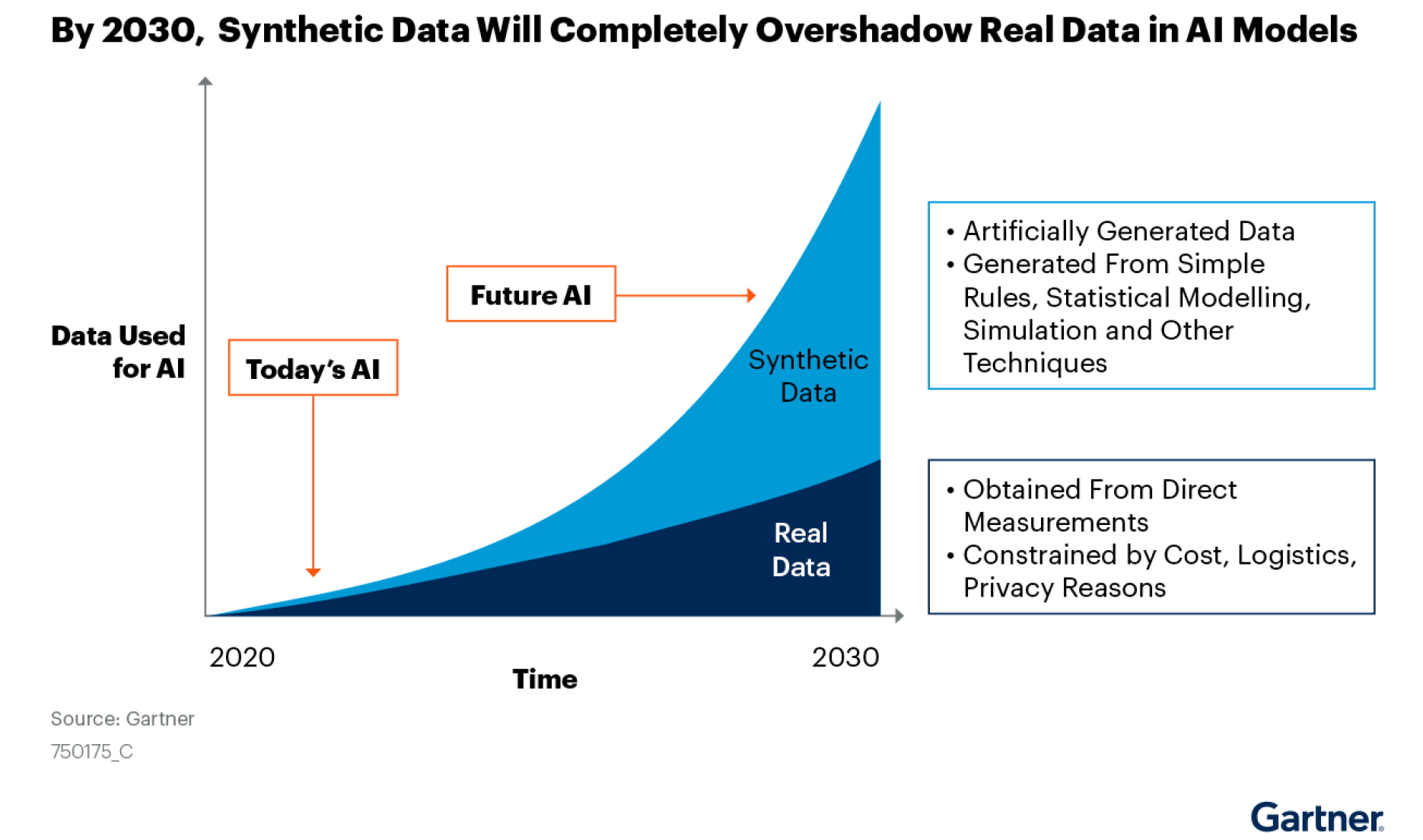
In a report on synthetic data, Gartner predicted by 2030 most of the data used in AI will be artificially generated by rules, statistical models, simulations or other techniques.
“The fact is you won’t be able to build high-quality, high-value AI models without synthetic data,” the report said.
Why Is Synthetic Data So Important?
Developers need large, carefully labeled datasets to train neural networks. More diverse training data generally makes for more accurate AI models.
The problem is gathering and labeling datasets that may contain a few thousand to tens of millions of elements is time consuming and often prohibitively expensive.
Enter synthetic data. A single image that could cost $6 from a labeling service can be artificially generated for six cents, estimates Paul Walborsky, who co-founded one of the first dedicated synthetic data services.
Cost savings are just the start. Synthetic data can address privacy issues and reduce bias by ensuring users have the data diversity to represent the real world.
Because synthetic datasets are automatically labeled and can deliberately include rare but crucial corner cases, it’s sometimes better than real-world data. For example, in the video below NVIDIA Omniverse Replicator generates synthetic data to train autonomous vehicles to navigate safely amid shopping carts and pedestrians in a simulated parking lot.
What’s the History of Synthetic Data?
Synthetic data has been around in one form or another for decades. It’s in computer games like flight simulators and scientific simulations of everything from atoms to galaxies.
Donald B. Rubin, a Harvard statistics professor, was helping branches of the U.S. government sort out issues such as an undercount especially of poor people in a census when he hit upon an idea. He described it in a 1993 paper often cited as the birth of synthetic data.
“I used the term synthetic data in that paper referring to multiple simulated datasets,” Rubin explained.
“Each one looks like it could have been created by the same process that created the actual dataset, but none of the datasets reveal any real data — this has a tremendous advantage when studying personal, confidential datasets,” he added.

In the wake of the Big Bang of AI, the ImageNet competition of 2012 when a neural network recognized objects faster than a human could, researchers started hunting in earnest for synthetic data.
Within a couple years, “researchers were using rendered images in experiments, and it was paying off well enough that people started investing in products and tools to generate data with their 3D engines and content pipelines,” said Gavriel State, a senior director of simulation technology and AI at NVIDIA.
Augmented and Anonymized Versus Synthetic Data
Most developers are already familiar with data augmentation, a technique that involves adding new data to an existing real-world dataset. For example, they might rotate or brighten an existing image to create a new one.
Given concerns and government policies about privacy, removing personal information from a dataset is another increasingly common practice. This is called data anonymization, and it’s especially popular for text, a kind of structured data used in industries like finance and healthcare.
Augmented and anonymized data are not typically considered synthetic data. However, it’s possible to create synthetic data using these techniques. For example, developers could blend two images of real-world cars to create a new synthetic image with two cars.
Ford, BMW Generate Synthetic Data
Indeed, car makers — as well as banks, drones, factories, hospitals, retailers, robots and scientists — use synthetic data today.
In a recent podcast, researchers from Ford described how they combine gaming engines and generative adversarial networks (GANs) to create synthetic data for AI training.
To optimize the process of how it makes cars, BMW created a virtual factory using NVIDIA Omniverse, a simulation platform that lets companies collaborate using multiple tools. The data BMW generates helps fine tune how assembly workers and robots work together to build cars efficiently. (See video below).
In logistics, Amazon Robotics uses synthetic data to train robots to identify packages of varying types and sizes. Food and beverage giant PepsiCo employs Omniverse Replicator to generate synthetic data it uses to train AI models in NVIDIA TAO, making its operations more efficient. (See video below.)
Synthetic Data at the Hospital, Bank and Store
Healthcare providers in fields such as medical imaging use synthetic data to train AI models while protecting patient privacy. For example, startup Curai trained a diagnostic model on 400,000 simulated medical cases.
“GAN-based architectures for medical imaging, either generating synthetic data [or] adapting real data from other domains … will define the state of the art in the field for years to come,” said Nikolenko in his 2019 survey.
GANs are getting traction in finance, too. American Express studied ways to use GANs to create synthetic data, refining its AI models that detect fraud.
In retail, companies such as startup Caper use 3D simulations to take as few as five images of a product and create a synthetic dataset of a thousand images. Such datasets enable smart stores where customers grab what they need and go without waiting in a checkout line.
How Do You Create Synthetic Data?
“There are a bazillion techniques out there” to generate synthetic data, said State from NVIDIA. For example, variational autoencoders compress a dataset to make it compact, then use a decoder to spawn a related synthetic dataset.
In another approach, NVIDIA researchers used AI to turn 2D video data into full 3D simulations. Their Neural Reconstruction Engine, now part of NVIDIA Drive, lets users automate the job of developing simulations and digital twins as shown in the video below.
Separately, NVIDIA is developing thousands of full-blown 3D models of real-world objects such as forklifts, palettes and ladders that developers can drop into their simulations. These SimReady assets are available for use in NVIDIA Omniverse, a platform for creating and collaborating in the metaverse of virtual worlds.
While GANs are on the rise, especially in research, simulations remain a popular option for two reasons. They support a host of tools to segment and classify still and moving images, generating perfect labels. And they can quickly spawn versions of objects and environments with different colors, lighting, materials and poses.
This last capability delivers the synthetic data that’s crucial for domain randomization, a technique increasingly used to improve the accuracy of AI models and tailor them to the needs of any user’s application.
Pro Tip: Use Domain Randomization
Domain randomization uses thousands of variations of an object and its environment so an AI model can more easily understand the general pattern. The video below shows how a smart warehouse uses domain randomization to train an AI-powered robot.
Domain randomization helps close the so-called domain gap — the space short of the perfect predictions an AI model would make if it was trained on the exact situation it happens to find on a given day. That’s why NVIDIA is building domain randomization for synthetic data generation tools into Omniverse, one part of the work described in a recent talk at GTC.
Such techniques are helping computer vision apps move from detecting and classifying objects in images to seeing and understanding activities in videos.
Synthetic data is especially valuable when working with video where users can create fully annotated video frames. Experts expect this approach to catch fire.
Where Can I Get Synthetic Data?
Though the sector is only a few years old, nearly 100 companies already provide synthetic data. Each has its own special sauce, often a focus on a particular vertical market or technique.
For example, a handful specialize in health care uses. A half dozen offer open source tools or datasets, including the Synthetic Data Vault, a set of libraries, projects and tutorials developed at MIT.
NVIDIA aims to work with a wide range of synthetic data and data-labeling services. Among its latest partners:
- Synthesis AI uses synthetic data to help customers build advanced AI models for computer vision applications.
- Sky Engine, based in London, works on computer vision apps across markets and can help users design their own data-science workflow.
- Israel-based Datagen creates synthetic datasets from simulations for a wide range of markets, including smart stores, robotics and interiors for cars and buildings.
- CVEDIA includes Airbus, Honeywell and Siemens among users of its customizable tools for computer vision based on synthetic data.
- Mostly AI provides a free synthetic data generator.
Training Robots With Synthetic Data
With Omniverse, NVIDIA aims to enable an expanding galaxy of designers and programmers interested in building or collaborating in virtual worlds across every industry. Synthetic data generation is one of many businesses the company expects will live there.
NVIDIA created Isaac Sim as an application in Omniverse for robotics. Users can train robots in this virtual world with synthetic data and domain randomization and deploy the resulting software on robots working in the real world.
Omniverse supports multiple applications for vertical markets such as NVIDIA DRIVE Sim for autonomous vehicles. It’s been letting developers test self-driving cars in the safety of a realistic simulation, generating useful datasets even in the midst of the pandemic.
These applications are among the latest examples of how simulations are fulfilling the promise of synthetic data for AI.
Learn More About Synthetic Data
For more information on synthetic data, check out these resources:
- An ebook by O’Reilly and NVIDIA on using synthetic data in AI
- A talk on synthetic data at GTC 2022 with Bhumin Pathak, , senior product manager, Omniverse Replicator, NVIDIA (free registration required)
- An interview with Rev Lebaredian, vice president of simulation technology at NVIDIA
- An assortment of NVIDIA developer blogs published in 2021 on synthetic data.
- A presentation at GTC 2021 by Scotiabank and the University of Alberta on research using generative models to create synthetic data (Free registration required)
- Open Synthetics provides a wealth of synthetic datasets and papers with contributions from Apple, Google, Meta, Microsoft and NVIDIA
- Examples with code samples for synthetic data generation on Omniverse
- A technical blog on synthetic data for explainable AI
Watch this on-demand technical webinar on generating synthetic data for training AI models with Isaac Replicator.