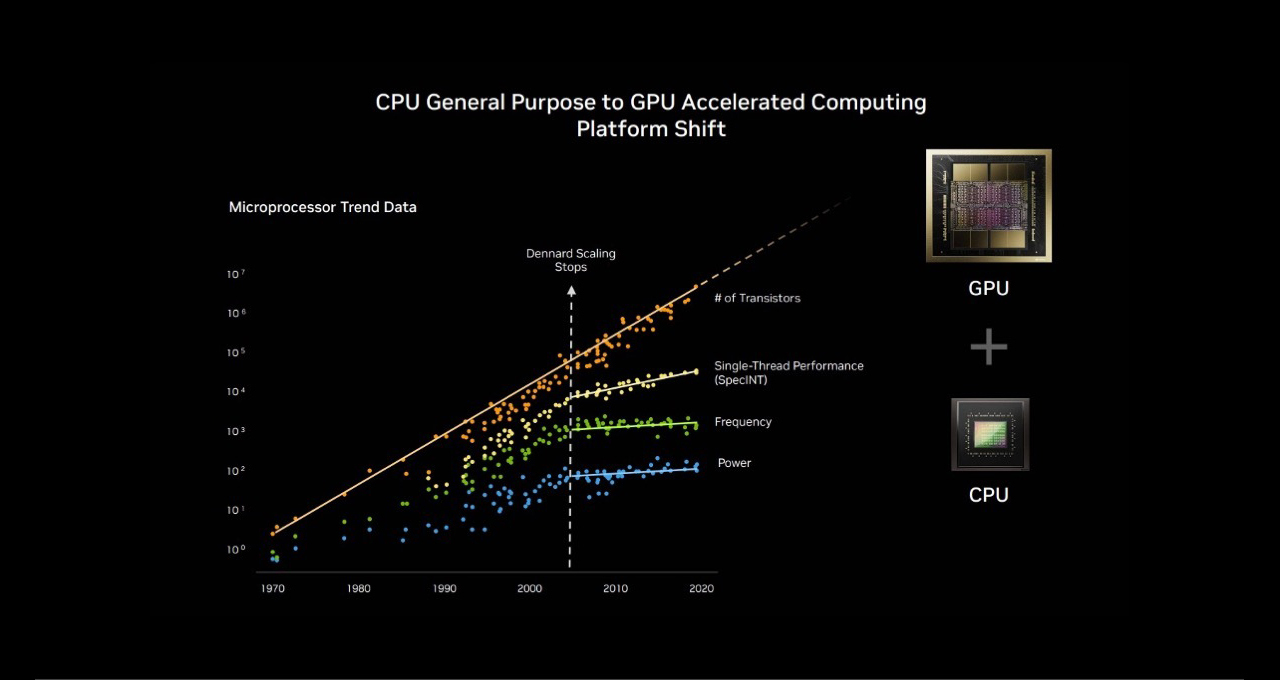
The NVIDIA accelerated computing platform is leading supercomputing benchmarks once dominated by CPUs, enabling AI, science, business and computing efficiency worldwide.
Moore’s Law has run its course, and parallel processing is the way forward. With this evolution, NVIDIA GPU platforms are now uniquely positioned to deliver on the three scaling laws — pretraining, post-training and test-time compute — for everything from next-generation recommender systems and large language models (LLMs) to AI agents and beyond.
- How NVIDIA has transformed the foundation of computing
- AI pretraining, post-training and inference are driving the frontier
- How hyperscalers are using AI to transform search and recommender systems
The CPU-to-GPU Transition: A Historic Shift in Computing 🔗
At SC25, NVIDIA founder and CEO Jensen Huang highlighted the shifting landscape. Within the TOP100, a subset of the TOP500 list of supercomputers, over 85% of systems use GPUs. This flip represents a historic transition from the serial‑processing paradigm of CPUs to massively parallel accelerated architectures.
![]()
Before 2012, machine learning was based on programmed logic. Statistical models were used and ran efficiently on CPUs as a corpus of hard-coded rules. But this all changed when AlexNet running on gaming GPUs demonstrated image classification could be learned by examples. Its implications were enormous for the future of AI, with parallel processing on increasing sums of data on GPUs driving a new wave of computing.
This flip isn’t just about hardware. It’s about platforms unlocking new science. GPUs deliver far more operations per watt, making exascale practical without untenable energy demands.
Recent results from the Green500, a ranking of the world’s most energy-efficient supercomputers, underscore the contrast between GPUs versus CPUs. The top five performers in this industry standard benchmark were all NVIDIA GPUs, delivering an average of 70.1 gigaflops per watt. Meanwhile, the top CPU-only systems provided 15.5 flops per watt on average. This 4.5x differential between GPUs versus CPUs on energy efficiency highlights the massive TCO (total cost of ownership) advantage of moving these systems to GPUs.
Another measure of the CPU-versus-GPU energy-efficiency and performance differential arrived with NVIDIA’s results on the Graph500. NVIDIA delivered a record-breaking result of 410 trillion traversed edges per second, placing first on the Graph500 breadth-first search list.
The winning run more than doubled the next highest score and utilized 8,192 NVIDIA H100 GPUs to process a graph with 2.2 trillion vertices and 35 trillion edges. That compares with the next best result on the list, which required roughly 150,000 CPUs for this workload. Hardware footprint reductions of this scale save time, money and energy.
Yet NVIDIA showcased at SC25 that its AI supercomputing platform is far more than GPUs. Networking, CUDA libraries, memory, storage and orchestration are co-designed to deliver a full-stack platform.

Enabled by CUDA, NVIDIA is a full-stack platform. Open-source libraries and frameworks such as those in the CUDA-X ecosystem are where big speedups occur. Snowflake recently announced an integration of NVIDIA A10 GPUs to supercharge data science workflows. Snowflake ML now comes preinstalled with NVIDIA cuML and cuDF libraries to accelerate popular ML algorithms with these GPUs.
With this native integration, Snowflake’s users can easily accelerate model development cycles with no code changes required. NVIDIA’s benchmark runs show 5x less time required for Random Forest and up to 200x for HDBSCAN on NVIDIA A10 GPUs compared with CPUs.
The flip was the turning point. The scaling laws are the trajectory forward. And at every stage, GPUs are the engine driving AI into its next chapter.
But CUDA-X and many open-source software libraries and frameworks are where much of the magic happens. CUDA-X libraries accelerate workloads across every industry and application — engineering, finance, data analytics, genomics, biology, chemistry, telecommunications, robotics and much more.
“The world has a massive investment in non-AI software. From data processing to science and engineering simulations, representing hundreds of billions of dollars in compute cloud computing spend each year,” Huang said on NVIDIA’s recent earning call.
Many applications that once ran exclusively on CPUs are now rapidly shifting to CUDA GPUs. “Accelerated computing has reached a tipping point. AI has also reached a tipping point and is transforming existing applications while enabling entirely new ones,” he said.

What began as an energy‑efficiency imperative has matured into a scientific platform: simulation and AI fused at scale. The leadership of NVIDIA GPUs in the TOP100 is both proof of this trajectory and a signal of what comes next — breakthroughs across every discipline.
As a result, researchers can now train trillion‑parameter models, simulate fusion reactors and accelerate drug discovery at scales CPUs alone could never reach.
The Three Scaling Laws Driving AI’s Next Frontier 🔗
The change from CPUs to GPUs is not just a milestone in supercomputing. It’s the foundation for the three scaling laws that represent the roadmap for AI’s next workflow: pretraining, post‑training and test‑time scaling.
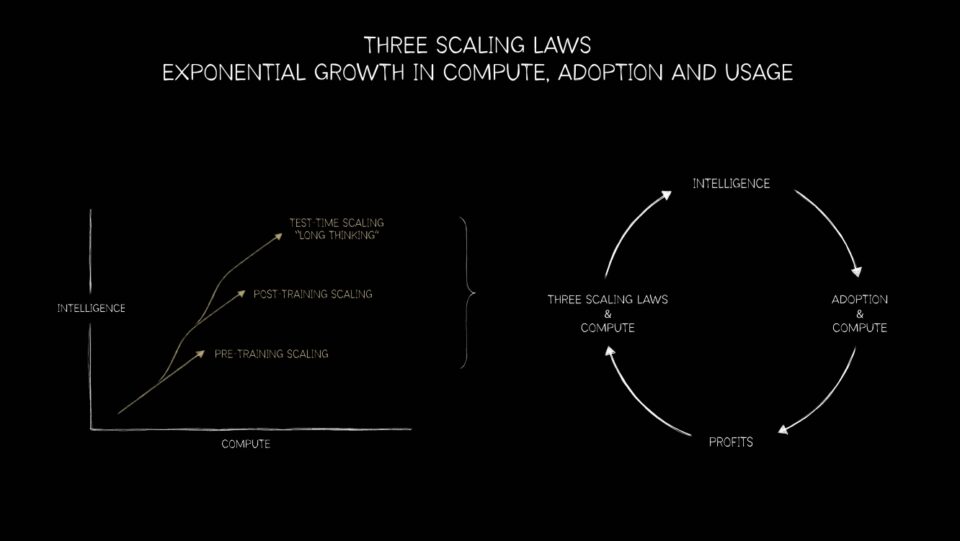
Pre‑training scaling was the first law to assist the industry. Researchers discovered that as datasets, parameter counts and compute grew, model performance improved predictably. Doubling the data or parameters meant leaps in accuracy and versatility.
On the latest MLPerf Training industry benchmarks, the NVIDIA platform delivered the highest performance on every test and was the only platform to submit on all tests. Without GPUs, the “bigger is better” era of AI research would have stalled under the weight of power budgets and time constraints.
Post‑training scaling extends the story. Once a foundation model is built, it must be refined — tuned for industries, languages or safety constraints. Techniques like reinforcement learning from human feedback, pruning and distillation require enormous additional compute. In some cases, the demands rival pre‑training itself. This is like a student improving after basic education. GPUs again provide the horsepower, enabling continual fine‑tuning and adaptation across domains.
Test‑time scaling, the newest law, may prove the most transformative. Modern models powered by mixture-of-experts architectures can reason, plan and evaluate multiple solutions in real time. Chain‑of‑thought reasoning, generative search and agentic AI demand dynamic, recursive compute — often exceeding pretraining requirements. This stage will drive exponential demand for inference infrastructure — from data centers to edge devices.
Together, these three laws explain the demand for GPUs for new AI workloads. Pretraining scaling has made GPUs indispensable. Post‑training scaling has reinforced their role in refinement. Test‑time scaling is ensuring GPUs remain critical long after training ends. This is the next chapter in accelerated computing: a lifecycle where GPUs power every stage of AI — from learning to reasoning to deployment.
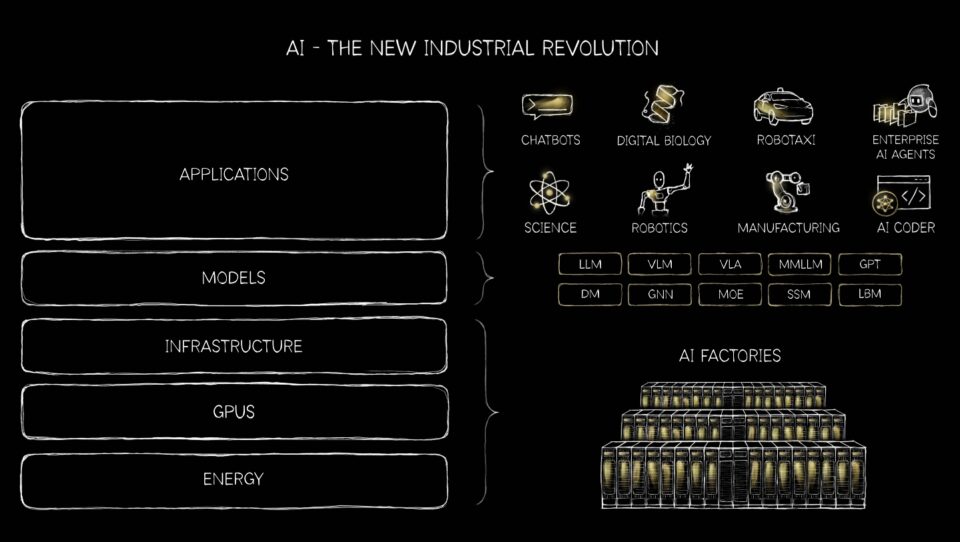
Generative, Agentic, Physical AI and Beyond 🔗
The world of AI is expanding far beyond basic recommenders, chatbots and text generation. VLMs, or vision language models, are AI systems combining computer vision and natural language processing for understanding and interpreting images and text. And recommender systems — the engines behind personalized shopping, streaming and social feeds — are but one of many examples of how the massive transition from CPUs to GPUs is reshaping AI.
Meanwhile, generative AI is transforming everything from robotics and autonomous vehicles to software-as-a-service companies and represents a massive investment in startups.
NVIDIA platforms are the only to run on all of the leading generative AI models and handle 1.4 million open-source models.
Once constrained by CPU architectures, recommender systems struggled to capture the complexity of user behavior at scale. With CUDA GPUs, pretraining scaling enables models to learn from massive datasets of clicks, purchases and preferences, uncovering richer patterns. Post‑training scaling fine‑tunes those models for specific domains, sharpening personalization for industries from retail to entertainment. On leading global online sites, even a 1% gain in relevance accuracy of recommendations can yield billions more in sales.
Electronic commerce sales are expected to reach $6.4 trillion worldwide for 2025, according to Emarketer.
The world’s hyperscalers, a trillion-dollar industry, are transforming search, recommendations and content understanding from classical machine learning to generative AI. NVIDIA CUDA excels at both and is the ideal platform for this transition driving infrastructure investment measured in hundreds of billions of dollars.
Now, test‑time scaling is transforming inference itself: recommender engines can reason dynamically, evaluating multiple options in real time to deliver context‑aware suggestions. The result is a leap in precision and relevance — recommendations that feel less like static lists and more like intelligent guidance. GPUs and scaling laws are turning recommendation from a background feature into a frontline capability of agentic AI, enabling billions of people to sort through trillions of things on the internet with an ease that would otherwise be unfeasible.
What began as conversational interfaces powered by LLMs is now evolving into intelligent, autonomous systems poised to reshape nearly every sector of the global economy.
We are experiencing a foundational shift — from AI as a virtual technology to AI entering the physical world. This transformation demands nothing less than explosive growth in computing infrastructure and new forms of collaboration between humans and machines.
Generative AI has proven capable of not just creating new text and images, but code, designs and even scientific hypotheses. Now, agentic AI is arriving — systems that perceive, reason, plan and act autonomously. These agents behave less like tools and more like digital colleagues, carrying out complex, multistep tasks across industries. From legal research to logistics, agentic AI promises to accelerate productivity by serving as autonomous digital workers.
Perhaps the most transformative leap is physical AI — the embodiment of intelligence in robots of every form. Three computers are required to build physical AI-embodied robots — NVIDIA DGX GB300 to train the reasoning vision-language action model, NVIDIA RTX PRO to simulate, test and validate the model in a virtual world built on Omniverse, and Jetson Thor to run the reasoning VLA at real-time speed.
What’s expected next is a breakthrough moment for robotics within years, with autonomous mobile robots, collaborative robots and humanoids disrupting manufacturing, logistics and healthcare. Morgan Stanley estimates there will be 1 billion humanoid robots with $5 trillion in revenue by 2050.
Signaling how deeply AI will embed into the physical economy, that’s just a sip of what’s on tap.

AI is no longer just a tool. It performs work and stands to transform every one of the world’s $100 trillion in markets. And a virtuous cycle of AI has arrived, fundamentally changing the entire computing stack, transitioning all computers into new supercomputing platforms for vastly larger opportunities.

